library(copula)
set.seed(123)11 Cópulas
Hasta el momento hemos visto como construir modelos univariados. Pero existen aplicaciones donde dos riesgos están correlacionados.
Es decir, a partir de la correlación lineal \(\rho\) entre dos variables \(X\) y \(Y\), podríamos describir su comportamiento. Sin embargo, en pérdidas nos interesa responder otras preguntas:
- Si un riesgo tiene una pérdida muy grande, ¿es más probable que otro riesgo también tenga una pérdida grande?
- ¿Cuáles son las probabilidades de tener varias pérdidas grandes de diferentes tipos de riesgo?
Estas preguntas se responde a partir del concepto de dependencia en las colas construida a partir de la cópula.
11.1 Definición y construcción de cópulas
El concepto de cópula es una distribución generada a partir de las distribuciones marginales de dos o más variables. Formalmente
Una cópula es una función \(C:[0,1]^d \mapsto[0,1]\) con las siguientes propiedades:
- Marginales:. Para cualquier \(j=1, \cdots, d\) se tiene que \(C\left(1, \dots, 1, u_j, 1, \dots, 1\right)=u_j\).
- Isotónica: \(C(u) \leq C(v)\) si \(u \leq v\), donde \(u \leq v\) significa que \(u_j \leq v_j\) para todo \(j=1 , \cdots, d\).
- \(d\)-creciente: para cualquier caja \([a, b] \subset[0,1]^d\) con volumen no vacío, \(C([a, b])> 0\).
En particular una cópula \(C\) con \(d\)-variable es la función de distribución conjunta de \(d\) variables aleatorias uniformes \((0,1)\). Si etiquetamos las variables aleatorias \(d\) como \(U_1, U_2, \ldots, U_d\), entonces podemos escribir la cópula \(C\) como
\[\begin{equation*} C\left(u_1, \ldots, u_d\right)=\operatorname{Pr}\left(U_1 \leq u_1, \ldots, U_d \leq u_d\right) . \end{equation*}\]
Ahora considere cualquier variable aleatoria continua \(X_1, X_2, \ldots, X_d\) con funciones de distribución \(F_1, F_2, \ldots, F_d\), respectivamente.
Construya una función de distribución multivariada de la siguiente manera:
\[\begin{equation*} \begin{aligned} F\left(x_1, \ldots, x_d\right) &=C\left[F_1\left(x_1\right), \ldots, F_d\left(x_d\right)\right] \\ &=\operatorname{Pr}\left(U_1 \leq F_1\left(x_1\right), \ldots, U_d \leq F_d\left(x_d\right)\right) . \end{aligned} \end{equation*}\]
Primero hay que verificar dos cosas
\(F\) es una función de distribución.
Prueba. Note que cada argumento es no decreciente ya que conforme crece cada \(x_i\) la función \(F_i(x_i)\) correspondiente no decrece (por ser una distribución). Como la función \(C\) fue construida a partir de la definición de una distribución conjunta, entonces \(F\) también lo es.
Note que el Teorema 11.1 (Sklar) nos dice que siempre se puede construir esta función \(C\) a partir de las distribuciones marginales y que esta es única.
Teorema 11.1 (Teorema de Sklar) Para un vector aleatorio \(X\) con distribución \(F\) y marginales univariadas \(F_1, \cdots, F_d\). Existe una cópula \(C\) tal que \[\begin{equation*} F\left(x_1, \cdots, x_d\right)=C\left(F_1\left(x_1\right), \cdots, F_d\left(x_d\right)\right) . \end{equation*}\] Si \(X\) es continua, entonces tal cópula \(C\) es única.
Las marginales de \(F\) son también funciones de distribución.
Prueba. Para una variable \(X_1\) se tiene que: \[\begin{equation*} \begin{aligned} \operatorname{Pr}\left(X_1 \leq x_1\right) &=F\left(x_1, \infty, \ldots, \infty\right) \\ &=\operatorname{Pr}\left[U_1 \leq F_1\left(x_1\right), U_2 \leq F_2(\infty), \ldots, U_d \leq F_d(\infty)\right] \\ &=\operatorname{Pr}\left[U_1 \leq F_1\left(x_1\right), U_2 \leq 1, \ldots, U_d \leq 1\right] \\ &=\operatorname{Pr}\left[U_1 \leq F_1\left(x_1\right)\right] \\ &=F_1\left(x_1\right) \end{aligned} \end{equation*}\]
Las ventajas de usar cópulas es que en un problema podemos reconocer el riesgo individual y que este está ligado con otros. Pero no tenemos idea como. El Teorema 11.1 nos dice que podemos experimentar con los riesgos individuales para constuir ese riesgo conjunto desconocido.
11.2 Medidas de asociación
La forma más sencilla de construir una cópula es basado en su correlación
11.2.1 \(\rho\) de Spearman
Para dos variables aleatoarios \((X_1, X_2)\), esta cópula se define como
\[\begin{equation*} \rho_S\left(X_1, X_2\right)=\rho\left(F_1\left(X_1\right), F_2\left(X_2\right)\right), \end{equation*}\]
donde \(\rho\) es la correlación lineal clásica.
Si recordamos que la distribución es una variable uniforme \((0,1)\) con media 1/2 y varianza 1/12 entonces:
\[\begin{equation*} \begin{aligned} \rho_S\left(X_1, X_2\right) &=\frac{\mathrm{E}\left[F_1\left(X_1\right) F_2\left(X_2\right)\right]-\mathrm{E}\left[F_1\left(X_1\right)\right] \mathrm{E}\left[F_2\left(X_2\right)\right]}{\sqrt{\operatorname{Var}\left(F_1\left(X_1\right)\right) \operatorname{Var}\left(F_2\left(X_2\right)\right)}} \\ &=12 \mathrm{E}\left[F_1\left(X_1\right) F_2\left(X_2\right)\right]-3 . \end{aligned} \end{equation*}\]
Más concretamente, la \(\rho\) de Spearman se puede escribir como \[\begin{equation*} \begin{aligned} \rho_S\left(X_1, X_2\right) &=12 \mathrm{E}[U V]-3 \\ &=12 \int_0^1 \int_0^1 u v d C(u, v)-3 \\ &=12 \int_0^1 \int_0^1 C(u, v) d u d v-3 . \end{aligned} \end{equation*}\]
Ejercicio 11.1 Muestre que \[\begin{equation*} \int_0^1 \int_0^1 u v d C(u, v) = \int_0^1 \int_0^1 C(u, v) d u d v. \end{equation*}\] usando integración por partes.
11.2.2 \(\tau\) de Kendall
Considere dos variables aleatorias bivariadas continuas independientes e idénticamente distribuidas \(\left(X_1, X_2\right)\) y \(\left(X_1^*, X_2^*\right)\) con distribución marginal \(F_1(x_1)\) para \(X_1\) y \(X_1^*\) y distribución marginal \(F_2\left(x_2\right)\) para \(X_2\) y \(X_2^*\).
La medida de asociación, de la \(\tau\) de Kendall, \(\tau_K\left(X_1, X_2\right)\), está dada por \[\begin{equation*} \tau_K\left(X_1, X_2\right)=\operatorname{Pr}\left[\left(X_1-X_1^*\right)\left(X_2-X_2^*\right)>0\right]-\operatorname{Pr}\left[\left(X_1-X_1^*\right)\left(X_2-X_2^*\right)<0\right] \end{equation*}\]
Es claro que esta medida se puede reescribir como \[\begin{equation*} \tau_K\left(X_1, X_2\right)=\mathrm{E}\left[\operatorname{sign}\left(X_1-X_1^*\right)\left(X_2-X_2^*\right)\right] . \end{equation*}\]
Además se puede reescribir como función de la cópula misma
\[\begin{equation*} \begin{aligned} \tau_K\left(X_1, X_2\right) &=4 \int_0^1 \int_0^1 C(u, v) d C(u, v)-1 \\ &=4 \mathrm{E}[C(U, V)]-1 . \end{aligned} \end{equation*}\]
Ejercicio 11.2 Pruebe la igualdad anterior haciendo lo siguiente:
- Recuerde que \(\operatorname{Pr}\left[\left(X_1-X_1^*\right)\left(X_2-X_2^*\right)<0\right] = 1 - \operatorname{Pr}\left[\left(X_1-X_1^*\right)\left(X_2-X_2^*\right)>0\right]\)
- Separe en dos probabilidades distintas \(\operatorname{Pr}\left[\left(X_1-X_1^*\right)\left(X_2-X_2^*\right)>0\right]\).
- Reconstruya cada termino en terminos de \(C\).
Si la cópula es absolutamente continua, entonces la ecuación anterior se puede reescribir como \[\begin{equation*} \tau_K\left(X_1, X_2\right)=4 \int_0^1 \int_0^1 C(u, v) c(u, v) d u d v-1 \end{equation*}\]
donde \(c(u, v)=\frac{\partial^2 C(u, v)}{\partial u \partial v}\) es la función de densidad.
11.3 Dependencia en las colas
El interés de construir estos objetos es en caso de que haya pérdidas grandes en una variable, entonces reconocer que también lo existe en las otras.
Considere dos variables aleatorias continuas \(X\) y \(Y\) con distribuciones marginales \(F(x)\) y \(G(y)\). El índice de dependencia de la cola superior \(\lambda_U\) se define como:
\[\begin{equation*} \lambda_U=\lim _{u \rightarrow 1} \operatorname{Pr}\left[X>F^{-1}(u) \mid Y>G^{-1}(u)\right] . \end{equation*}\]
En resumen, si \(X\) es muy grande, dado que \(Y\) lo es, entonces podemos identificar cierta dependencia.
Podemos reescribir esta igualdad como
\[\begin{equation*} \begin{aligned} \lambda_U &=\lim _{u \rightarrow 1} \operatorname{Pr}[F(X)>u \mid G(Y)>u] \\ &=\lim _{u \rightarrow 1} \operatorname{Pr}[U>u \mid V>u] \end{aligned} \end{equation*}\]
Haciendo un poco más de álgebra se puede escribir así (¿por qué?):
\[\begin{equation*} \begin{aligned} \lambda_U &=\lim _{u \rightarrow 1} \frac{1-\operatorname{Pr}(U \leq u)-\operatorname{Pr}(V \leq u)+\operatorname{Pr}(U \leq u, V \leq u)}{1-\operatorname{Pr}(V \leq u)} \\ &=\lim _{u \rightarrow 1} \frac{1-2 u+C(u, u)}{1-u} \end{aligned} \end{equation*}\]
De acá observamos que la dependencia de las colas puede ser explicada completamente partir de la cópula y no de las distribuciones marginales.
11.4 Generación de cópulas
El punto clave en la discusión de modelos de cópulas es la construcción de la función \(C(u,v)\). En esta sección veremos algunas formas de construirla.
11.4.1 Cópulas arquimedianas
La forma de esta cópula es,
\[\begin{equation*} C\left(u_1, \ldots, u_d\right)=\phi^{-1}\left[\phi\left(u_1\right)+\cdots+\phi\left(u_d\right)\right], \end{equation*}\] donde \(\phi(x)\) es llamado generador.
Propiedades de un generador
- Es una función estrictamente decreciente, convexa y continua.
- Se tiene que \(\phi: [0,1] \to [0, \infty]\).
- \(\phi(1) = 0\).
- La inversa del generador \(\phi^{-1}(t)\) debe ser completamente monótona en \([0, \infty]\). Es decir debe cumplir que \[\begin{equation*} (-1)^n \frac{d^n}{d x^n} \phi^{-1}(x) \geq 0, n=1,2,3, \ldots \end{equation*}\]
Para el caso de dos variables, se puede describir,
\(\tau_K\) de kendall: Haciendo los respectivos cálculos se tiene que
\[\begin{equation*} \tau_K\left(X_1, X_2\right)=1+4 \int_0^t \frac{\phi(u)}{\phi^{\prime}(u)} d u . \end{equation*}\]Dependencia de la colas: \[\begin{equation*} \begin{aligned} \lambda &= \lim _{u \rightarrow 1} \frac{1-2 u+C(u, u)}{1-u}\\ &=\lim _{u \rightarrow 1} \frac{1-2 u+\phi^{-1}[2 \phi(u)]}{1-u} \\ &=2-2 \lim _{t \rightarrow 0} \frac{\frac{d}{d t} \phi^{-1}(2 t)}{\frac{d}{d x} \phi^{-1}(t)} \end{aligned} \end{equation*}\] con la condición que \(\lim_{t \to 0} \frac{d}{dt}{dt} \phi^{-1}(t) = -\infty\).
Ejercicio 11.3 Prueben esta propiedad usando el teorema de l’Hopital.
11.4.2 Cópulas independientes
Una caso particular de las arquimedianas es cuando \(\phi(u)= - \ln(u)\). Acá se obtiene que
\[\begin{equation*} C\left(u_1, \ldots, u_d\right)=\prod_{j=1}^d u_j \end{equation*}\]
Ejercicio 11.4 Para este caso en el caso de dos variables se tiene que
- \(\tau_K = 0\).
- \(\lambda_U = 0\).
¿Por qué se da este fenómeno?
11.4.3 Cópula de Gumbel
Usando \(\phi(u)=(-\ln u)^\theta, \quad \theta \geq 1\) se obtiene
\[\begin{equation*} C\left(u_1, \ldots, u_d\right)=\exp \left\{-\left[\left(-\ln u_1\right)^\theta+\cdots+\left(-\ln u_d\right)^\theta\right]^{1 / \theta}\right\} \end{equation*}\]
En este caso se debe ajustar el parametro \(\theta\).
Ejercicio 11.5 Para este caso en el caso de dos variables se tiene que
- \(\tau_K = 1-\frac{1}{\theta}\).
- \(\lambda_U = 2-2^{\frac{1}{\theta}}\).
11.4.4 Otras cópulas
| Nombre | Generador | \(C(u_1, \ldots, u_d)\) | \(\lambda_U\) |
|---|---|---|---|
| Joe | \(-\ln \left[1-(1-u)^\theta\right], \quad \theta \geq 1\) | \(1-\left[\sum_{j=1}^d\left(1-u_j\right)^\theta-\prod_{j=1}^d\left(1-u_j\right)^\theta\right]^{1 / \theta}\) | \(2-2^{\frac{1}{\theta}}\) |
| BB1 | \(\left(u^{-5}-1\right)^\theta, \delta>0, \quad \theta \geq 1\) | \(\left\{1+\left[\sum_{j=1}^d\left(u_j^{-\delta}-1\right)^\theta\right]^{1 / \theta}\right\}^{-1 / \delta}\) | \(2-2^{1 /(\delta\theta)}\) |
11.5 Cópulas elípticas
Estas son generadas principalmente por distribuciones elípticas.
11.5.1 Cópula gaussiana
\[\begin{equation*} C\left(u_1, \ldots, u_d\right)=\Phi_{\mathbf{P}}\left(\Phi^{-1}\left(u_1\right), \ldots, \Phi^{-1}\left(u_d\right)\right) \end{equation*}\]
donde \(\Phi(x)\) es la cdf normal univariada estándar y \(\boldsymbol{\Phi}_{\mathbf{P}}\left(x_1, \ldots, x_d\right)\) es la cdf multivariada de la distribución normal multivariada estándar (con media cero y varianza de 1 para cada componente) y matriz de correlación \(\mathbf{P}\). Debido a que la matriz de correlación contiene \(d(d-1) / 2\) correlaciones por pares, este es el número de parámetros en la cópula.
No existe una forma cerrada simple para la cópula. En el caso bidimensional (con un solo elemento de correlación \(\rho\) ), la cópula gaussiana se puede escribir como \[\begin{equation*} C\left(u_1, u_2\right)=\int_{-\infty}^{\Phi^{-1}\left(u_1\right)} \int_{-\infty}^{\Phi^{-1}\left(u_2\right)} \frac{1}{2 \pi \sqrt{1-\rho^2}} \exp \left\{-\frac{x^2-2 \rho x y+y^2}{2\left(1-\rho^2\right)}\right\} d y d x \end{equation*}\]
Aunque su forma teórica es algo difícil de construir, es muy fácil de simular.
Para dos variable se tiene que \[\begin{equation*} \tau_K\left(X_1, X_2\right)=\frac{2}{\pi} \arcsin (\rho) \end{equation*}\] si \(\rho=0\) entonces se obtiene la cópula independiente.
Además, \(\lambda_U=0\) por lo que esta cópula no es adecuada para modelado de riesgo por este motivo.
11.5.2 Cópula \(t\)-student
La cópula \(t\) viene dada por \[\begin{equation*} C\left(u_1, \ldots, u_d\right)=\mathbf{t}_{\nu, \mathbf{P}}\left(t_\nu^{-1}\left(u_1\right), \ldots, t_\nu^{-1}\left(u_d\right)\right), \end{equation*}\] donde \(t_\nu(x)\) es el cdf de la distribución estándar \(t\) con \(\nu\) grados de libertad y \(\mathbf{t}_{\nu, \mathbf{ P}}\left(x_1, \ldots, x_d\right)\) es la cdf conjunta de la distribución estándar multivariada \(t\) con \(\nu\) grados de libertad para cada componente y donde \(\mathbf {P}\) es una matriz de correlación. En el caso bidimensional (con un solo elemento de correlación \(\rho\) ), la cópula \(t\) se puede escribir como\[\begin{equation*} C\left(u_1, u_2\right)=\int_{-\infty}^{t_\nu^{-1}\left(u_1\right)} \int_{-\infty}^{t_\nu^{-1}\left(u_2\right)} \frac{1}{2 \pi \sqrt{1-\rho^2}}\left\{1+\frac{x^2-2 \rho x y+y^2}{\nu\left(1-\rho^2\right)}\right\}^{-1-\frac{\nu}{2}} d y d x. \end{equation*}\]
Se puede estimar que \[\begin{equation*} \tau_K\left(X_1, X_2\right)=\frac{2}{\pi} \arcsin \rho \end{equation*}\] pero si \(\rho=0\) no implica la cópula independiente.
Para este caso, \[\begin{equation*} \lambda_U=2 t_{\nu+1}\left(-\sqrt{\frac{1-\rho}{1+\rho}(\nu+1)}\right) . \end{equation*}\]
11.6 Laboratorio
Para este ejercicio vamos a usar el siguiente paquete
- Abra la ayuda en la función
ellipCopulay describa que tipo de entradas se necesita y que objeto voy a obtener. - Construya una cópula gauassiana, de dimensión 3 y \(\rho=0.4\). Use
getSigmapara ver la matriz de correlación. - Haga lo mismo con cópula \(t\) con 8 df, pero use
dispstr='toep'yparam = c(0.8, 0.5). Qué ocurrió? - Finalmente use la función
archmCopulay construya una cópula gumbel con parámetro 3.
Ejercicio 11.6 En este ejemplo se generarán datos que tengan marginales Gamma con una cópula elíptica.
CopulaModelo <-
mvdc(
copula = ellipCopula(family = "normal", param = 0.5),
margins = c("gamma", "gamma"),
paramMargins = list(list(shape = 2, scale = 1), list(shape = 3, scale = 2))
)
contour(CopulaModelo, dMvdc, xlim = c(-1, 6), ylim = c(-1, 14))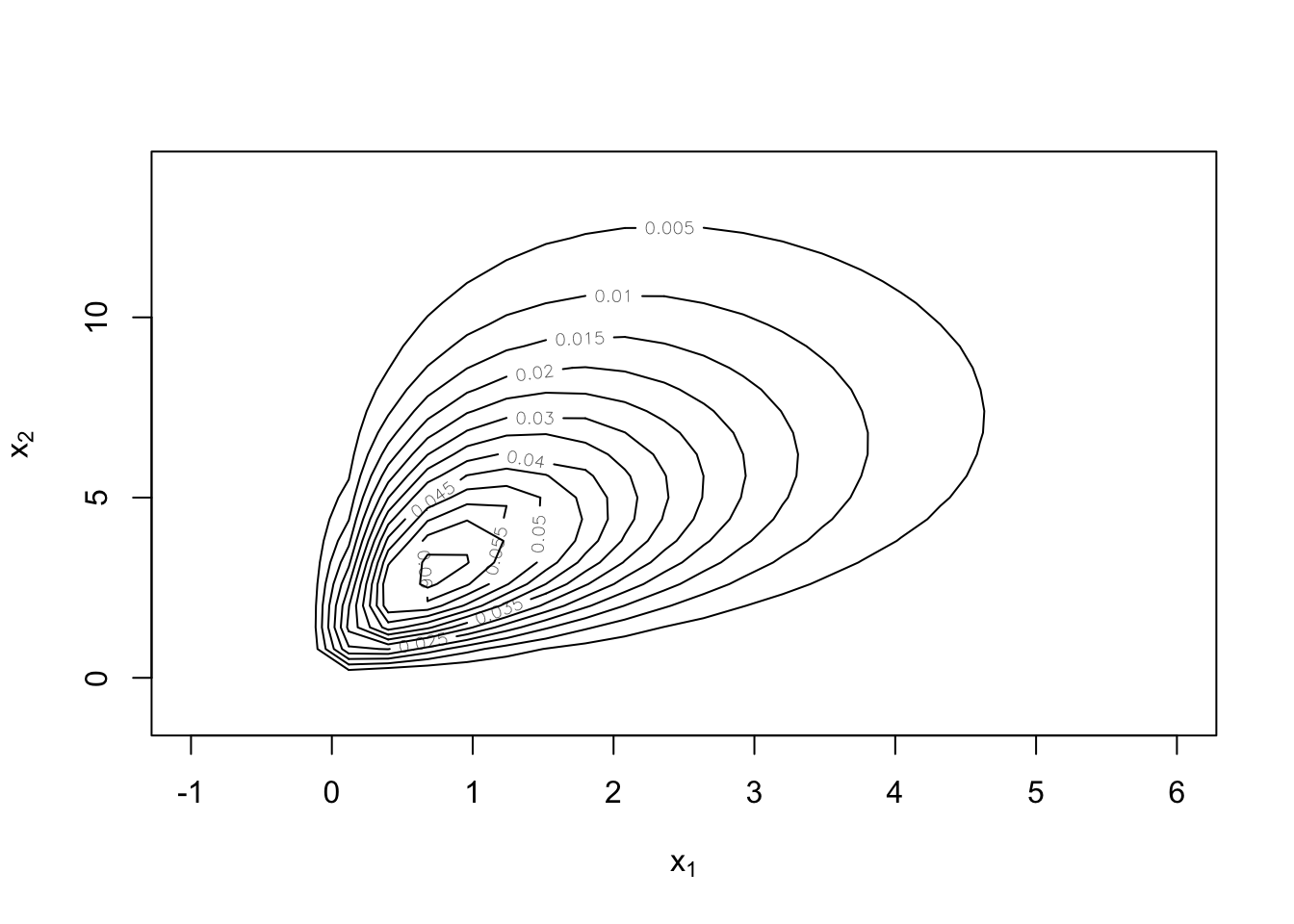
n <- 1000
dat <- rMvdc(mvdc = CopulaModelo, n = n)- Cuál es la fórmula exacta para calcular los parámetros
shapeyscaleusando los datos.
- Construya la \(\tau_K\) para estos datos
- Use la función
fitMvdcpara ajustar la cópula sin valores iniciales. ¿Qué parámetros necesita? - Usando los valores iniciales calculados anteriormente vuelva a hacer el ajuste.
- Vuelva a dibujar la copula, pero usando los valores ajustados del punto anterior.
11.7 Cópulas de valor extremo
Una cópula de este tipo tiene la propiedad de tener estabilidad en el máximo. Para entender esta propiedad veamos esta proposición:
Proposición 11.1 Una cópula de valor extremo satisface la igualdad,
\[\begin{equation*} C\left(u_1^n, \ldots, u_d^n\right)=C^n\left(u_1, \ldots, u_d\right), \end{equation*}\]
para todo \((u_1, \dots, u_{d})\) y para todo \(n\geq 0\).
Prueba. Para demostrar esta propiedad, considere el caso bivariado. Supongamos que \(\left(X_1, Y_1\right),\left(X_2, Y_2\right), \ldots,\left(X_n, Y_n\right)\) son \(n\) pares aleatorios independientes e idénticamente distribuidos extraídas de la distribución conjunta \(F(x, y)\), con distribuciones marginales \(F_X(x)\) y \(F_Y(y)\) y cópula \(C(x, y)\).
Sea \(M_X=\max \left(X_1, \ldots, X_n\right)\) y \(M_Y=\max \left(Y_1, \ldots, Y_n\right)\) los máximos por en cada margen.
Entonces la función de distribución del par aleatorio \(\left(M_X, M_Y\right)\) es \[\begin{equation*} \begin{aligned} \operatorname{Pr}\left(M_X \leq x, M_Y \leq y\right) &=\operatorname{Pr}\left(X_i \leq x, \mathrm{Y}_i \leq y, \text { para todo } i\right) \\ &=F^n(x, y) \end{aligned} \end{equation*}\]
De manera similar, las distribuciones marginales de \(M_X\) y \(M_Y\) son \(F_X^n(x)\) y \(F_Y^n(y)\). Entonces, dado que \[\begin{equation*} F(x, y)=C\left[F_X(x), F_Y(y)\right], \end{equation*}\] podemos escribir la distribución conjunta de los máximos como \[\begin{equation*} \begin{aligned} F^n(x, y) &=C^n\left[F_X(x), F_Y(y)\right] \\ &=C^n\left\{\left[F_X^n(x)\right]^{1 / n},\left[F_Y^n(y)\right]^{1 / n}\right\} . \end{aligned} \end{equation*}\] Por tanto, la cópula de los máximos viene dada por \[\begin{equation*} C_{\max }\left(u_1, u_2\right)=C^n\left(u_1^{1 / n}, u_2^{1 / n}\right) \end{equation*}\] o equivalente, \[\begin{equation*} C_{\max }\left(u_1^n, u_2^n\right)=C^n\left(u_1, u_2\right) . \end{equation*}\]
El resultado anterior dice que si \(C_{\max}\) es del mismo tipo que la cópula original \(C\), entonces la cópula tiene la estabilidad del máximo.
En otras palabras, esta propiedad dice la copula asociados con \((M_{X}, M_{Y})\) es la misma que \(C(x,y)\)
Se puede probar que la forma general de estas cópulas es
\[\begin{equation*} C\left(u_1, u_2\right)=\exp \left\{\ln \left(u_1 u_2\right) A\left(\frac{\ln u_1}{\ln \left(u_1 u_2\right)}\right)\right\}, \end{equation*}\]
donde \(A(w)\) es una función de dependencia,
\[\begin{equation*} A(w)=\int_0^1 \max [x(1-w), w(1-x)] d H(x) \end{equation*}\]
para cualquier \(w \in[0,1]\) y \(H\) es una función de distribución sobre \([0,1]\). Resulta que \(A(w)\) debe ser una función convexa que satisfaga \[\begin{equation*} \max (w, 1-w) \leq A(w) \leq 1,0<w<1 \end{equation*}\] y que cualquier función convexa diferenciable \(A(w)\) que satisfaga esta desigualdad puede usarse para construir una cópula. Tenga en cuenta que la cópula de independencia resulta de establecer \(A(w)\) en su límite superior \(A(w)=1\). En el otro extremo, si \(A(w)=\max (w, 1-w)\), entonces hay correlación perfecta y, por tanto, dependencia perfecta con \(C(u, u)=u\).
La dependencia de la cola superior se puede escribir como
\[\begin{equation*} \begin{aligned} \lambda_U &=\lim _{u \rightarrow 1} \frac{1-2 u+C(u, u)}{1-u} \\ &=\lim _{u \rightarrow 1} \frac{1-2 u+u^{2 A(1 / 2)}}{1-u} \\ &=\lim _{u \rightarrow 1} 2-2 A(1 / 2) u^{2 A(1 / 2)-1} \\ &=2-2 A(1 / 2) . \end{aligned} \end{equation*}\]
Algunos ejemplos de este tipo de cópulas son
| Nombre | \(A(w)\) | \(\lambda_U\) |
|---|---|---|
| Gumbel | \(\left[w^\theta+(1-w)^\theta\right]^{1 / \theta}, \quad \theta \geq 0\) | si \(w=\frac{1}{2}\) entonces \(2-2^{\frac{1}{\theta}}\) |
| Galambos | \(1-\left[w^{-\theta}+(1-w)^{-\theta}\right]^{-1 / \theta}, \quad \theta>0\) | \(2^{-1 /\theta}\) |
11.7.1 Cópulas Archimax
Combinando cópulas arquimedianas y de valor extremos se puede escribir las siguiente representación,
\[\begin{equation*} C\left(u_1, u_2\right)=\phi^{-1}\left[\left\{\phi\left(u_1\right)+\phi\left(u_2\right)\right\} A\left(\frac{\phi\left(u_1\right)}{\phi\left(u_1\right)+\phi\left(u_2\right)}\right)\right], \end{equation*}\] donde \(\phi(u)\) es un generador arquimediano válido y \(A(w)\) es una función de dependencia válida.
| Nombre | \(\phi(u)\) | \(A(w)\) | \(C(u_1,u_2)\) | |
|---|---|---|---|---|
| BB4 | \(u^{-\theta}-1, \quad \theta \geq 0\) | \(1-\left\{w^{-\delta}+(1-w)^{-\delta}\right\}^{-1 / \delta}, \quad \theta>0, \delta>0\) | \(\left\{u_1^{-\theta}+u_2^{-\theta}-1-\left[\left(u_1^{-\theta}-1\right)^{-\delta}+\left(u_2^{-\theta}-1\right)^{-\delta}\right]^{-1 / \delta}\right\}^{-1 / \theta}\) |
11.8 Estimación por máxima verosimilitud
Recuerde que la cópula es de la forma \[\begin{equation*} F\left(x_1, \ldots, x_d\right)=C\left[F_1\left(x_1\right), \ldots, F_d\left(x_d\right)\right] \end{equation*}\]
y su densidad es \[\begin{equation*} f\left(x_1, \ldots, x_d\right)=f_1\left(x_1\right) f_2\left(x_2\right) \cdots f_d\left(x_d\right) c\left[F_1\left(x_1\right), \ldots, F_d\left(x_d\right)\right] \end{equation*}\]
Nota
La estimación de los parámetros de la cópula depende de la estimación de las marginales.
Entonces se puede escribir para \(n\) datos
\[\begin{equation*} \begin{aligned} l &=\sum_{j=1}^n \ln f\left(x_{1, j}, \ldots, x_{d, j}\right) \\ &=\sum_{j=1}^n \sum_{i=1}^d \ln f_i\left(x_{i, j}\right)+\sum_{j=1}^n \ln c\left[F_1\left(x_{1, j}\right), \ldots, F_d\left(x_{d, j}\right)\right] \\ &=l_w+l_c . \end{aligned} \end{equation*}\]
Forma de estimación
- Optimice las \(d\) funciones \(\ln(f_{i}(x_{ij})\) individualmente.
- Use esos valores para construir los pseudo-verosimiludes \(\widetilde{u}_{i, j}=\widetilde{F}_i\left(x_{i, j}\right)\).
- Optimice la pseudo-verosimilitud de la cópula \(\widetilde{l}_c=\sum_{j=1}^n \ln c\left(\widetilde{u}_{1, j}, \ldots, \widetilde{u}_{d j}\right)\).
11.9 Medidas de mejor ajuste
Sabemos que \(U_1=F_1\left(X_1\right)\) y \(U_2=F_2\left(X_2\right)\) son ambas variables aleatorias uniformes \((0,1)\).
Ahora introduzca las variables aleatorias condicionales \(V_1=F_{12}\left(X_1 \mid X_2\right)\) y \(V_2=F_{ 21}\left(X_2 \mid X_1\right)\). Entonces, las variables aleatorias \(V_1\) y \(U_2\) son \((0,1)\) variables aleatorias uniformes mutuamente independientes.
Note que la variable aleatoria \(V_1=F_{12}\left(X_1 \mid\right.\) \(X_2=x\) ). Debido a que es una distribución aplicada a una variable aleatoria, debe tener una distribución uniforme \((0,1)\). Este resultado es cierto para cualquier valor de \(x\). Así, la distribución de \(V_1\) no depende del valor de \(X_2\) y por tanto no depende de \(U_2=F_2\left(X_2\right)\).
El valor observado de la función de distribución de la variable aleatoria condicional \(X_2\) dada \(X_1=x_1\) es \[\begin{equation*} F_{21}\left(x_2 \mid X_1=x_1\right)=C_1\left[F_{X_1}\left(x_1\right), F_{X_2}\left(x_2\right)\right] . \end{equation*}\] El valor observado \(v_2\) de la variable aleatoria \(V_2\) se puede obtener a partir de los valores observados de las variables aleatorias bivariadas \(\left(X_1, X_2\right)\) de \[\begin{equation*} v_2=\widehat{F}_{21}\left(x_2 \mid X_1=x_1\right)=\widehat{C}_1\left[\widehat{F}_{X_1}\left(x_1\right), \widehat{F}_{X_2}\left(x_2\right)\right] . \end{equation*}\] Por lo tanto, podemos generar un conjunto univariado de datos que debería verse como una muestra de una distribución \((0,1)\) uniforme si la combinación de distribuciones marginales y la cópula se ajusta bien a los datos.
El método sugerido para probar el ajuste es el siguiente
Nota
- Paso 1. Ajuste y seleccione las distribuciones marginales utilizando métodos univariados.
- Paso 2. Pruebe la uniformidad de la distribución condicional de \(V_1\).
- Paso 3. Pruebe la uniformidad de la distribución condicional de \(V_2\).
Las pruebas a usar son las usuales que hemos visto en el curso.
Para más dimensiones, se pueden probar las variables dos a dos y comprobar el ajuste.
11.9.1 Laboratorio
library(copula)
library(tidyverse)data(loss)
# loss data loss: pérdida de la compañía hasta cierto límite.
# alae: gastos relacionados con el reclamo (gastos legales, gastos por
# investigaciones, etc. )
ggplot(loss, aes(loss, alae)) +
geom_point()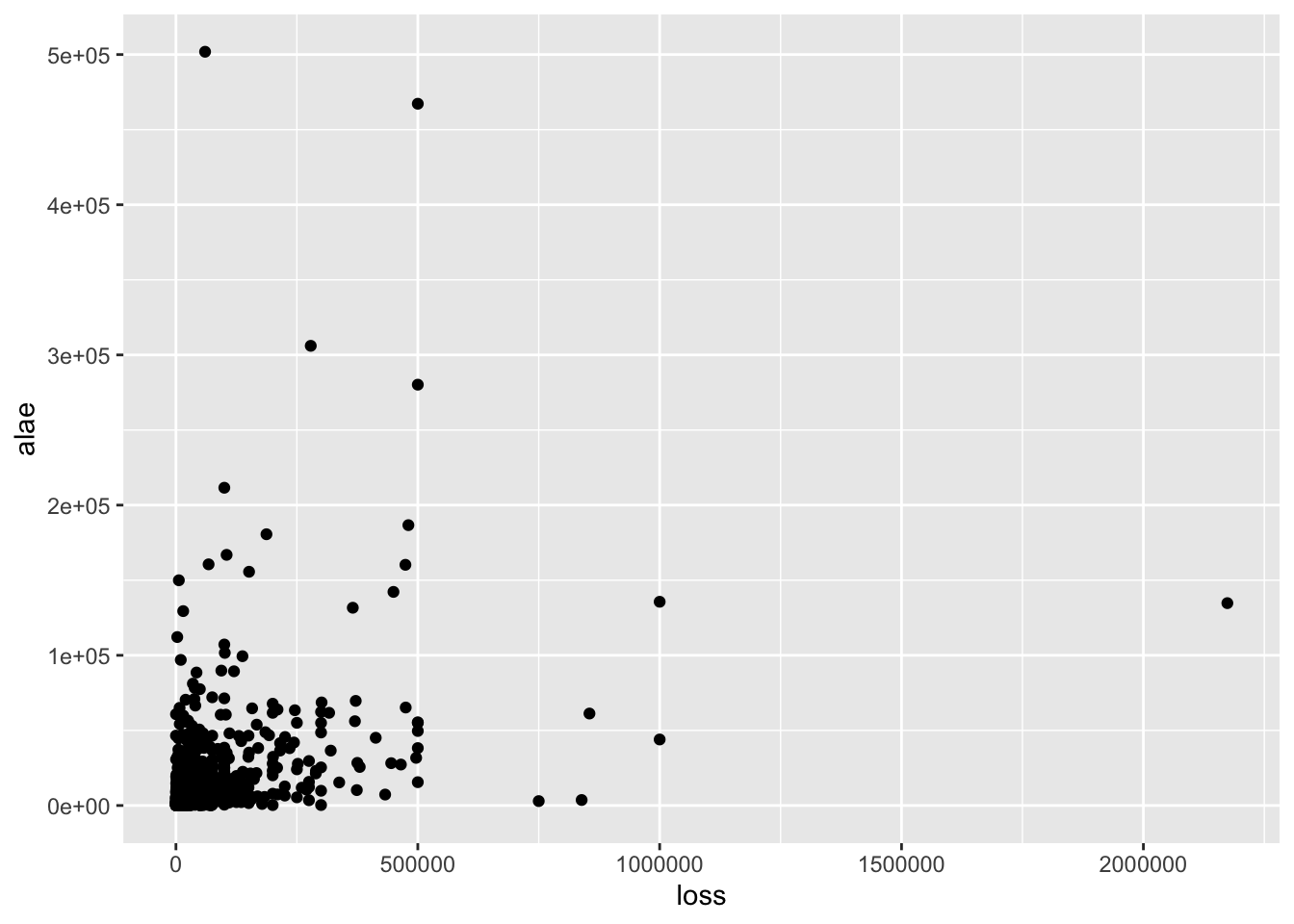
ggplot(loss, aes(log(loss), log(alae))) +
geom_point()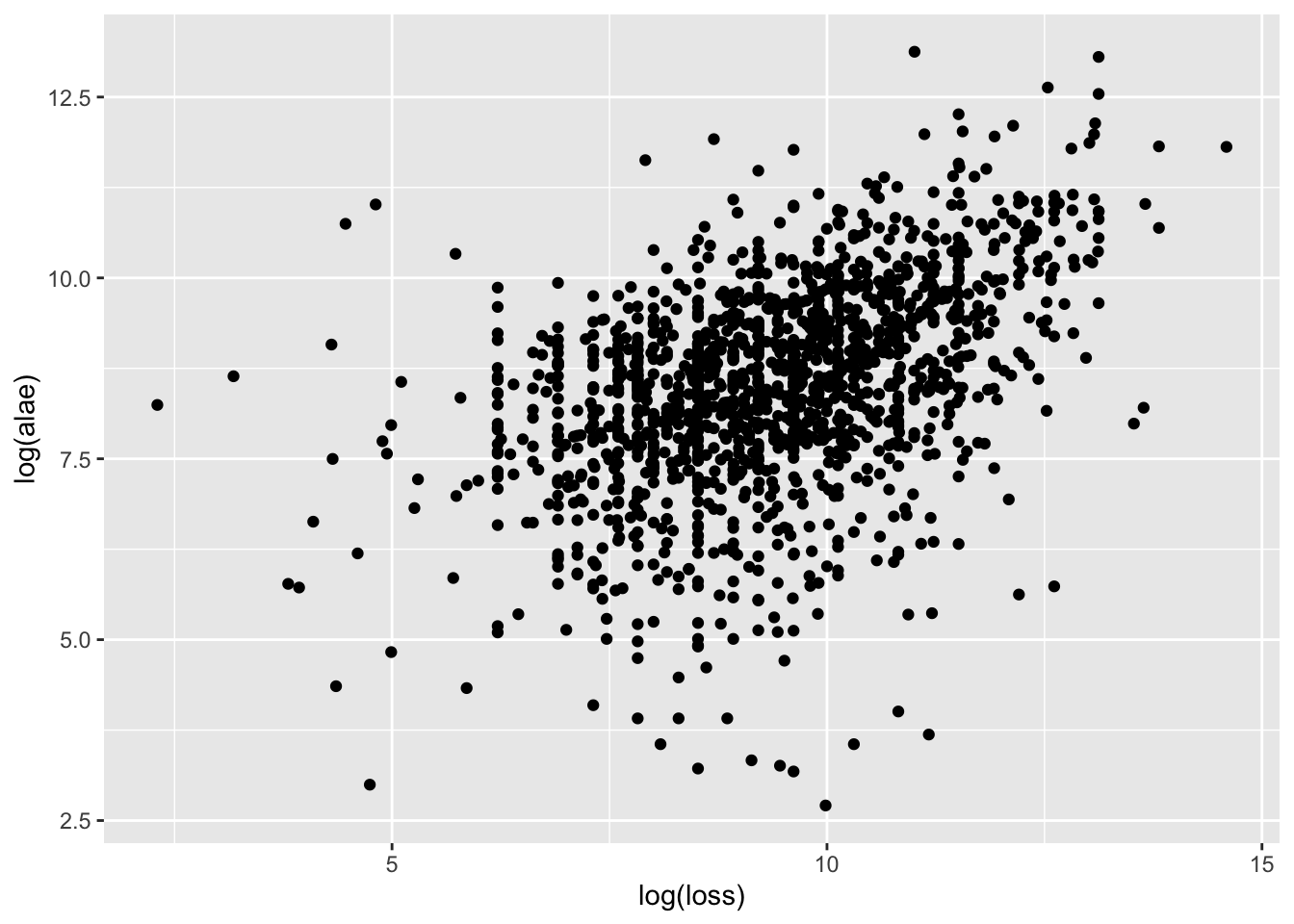
- Ajuste las variables
lossyalaeindividualmente. Traten Pareto, lognormal, gamma, etc. ¿Cuál es mejor? (Noten que algunos valores están censurados) (usencoef(fit)para obtener los parámetros correctos.) - Construya las variables \(U_1\) y \(U_2\) para cada marginal. Compruebe que la hipotesis de uniformidad se cumple.
- Use cópulas Frank, Gumbel, Normal y t para modelar la distribución conjunta de \(U_1\) y \(U_2\). (revise la función
archCopula). - Use la funciones
contourypersppara visualizar la copula. - Revisen la tau de Kendall y la dependencia de la cola para caso.
- Calcule la distribuciones condicionales usando
cCopulay verifique el supuesto de uniformidad. - Finalmente, calcule el VaR al 95% y 99% de cada margen asumiendo independencia. Usando la función
rMvdcgenere datos aleatorios de cada margen usando la cópula y calcule los mismos niveles de VaR. Compare los resultados.
11.10 El rol de los deducibles
Cada variable puede tener su propio deducibles y las variables en los margenes podrían ser datos individuales o agrupados. Esto genera diferencias para la construcción del estimador de máxima verosimilitud.
En este caso explicaremos las diferencias en el caso bivariado. Recordemos que
\[\begin{align*} F(x, y)&=C\left[F_1\left(x_1\right), F_2\left(x_2\right)\right]\\ f(x, y)&=f_1\left(x_1\right) f_2\left(x_2\right)c\left[ F_1\left(x_1\right), F_2\left(x_2\right)\right] \end{align*}\]
donde \[\begin{equation*} \begin{aligned} C_1\left(u_1, u_2\right) &=\frac{\partial}{\partial u_1} C\left(u_1, u_2\right) \\ C_2\left(u_1, u_2\right) &=\frac{\partial}{\partial u_2} C\left(u_1, u_2\right), \\ c\left(u_1, u_2\right) &=C_{12}\left(u_1, u_2\right)=\frac{\partial}{\partial u_1} \frac{\partial}{\partial u_2} C\left(u_1, u_2\right) . \end{aligned} \end{equation*}\]
En el caso de datos agrupados solo hay que considerar el caso cuando el dato cae sobre intervalo. Llamemos \([a_1,b_1]\) y \([a_2,b_2]\) los intervalos respectivos para \(X_1\) y \(X_2\).
Consideramos cuatro casos:
- Caso #1: Datos individuales para \(X_1\) y \(X_2\).
- En este caso, se tiene un factor muy similar al visto para el caso univariado. Si \(X_1\) o \(X_2\) caen por debajo de su deducibles no son tomadas en cuenta.
\[\begin{equation*} \begin{aligned} &\frac{f\left(x_1, x_2\right)}{1-F_1\left(d_1\right)-F_2\left(d_2\right)+F\left(d_1, d_2\right)} \\ &=\frac{f_1\left(x_1\right) f_2\left(x_2\right) c\left[F_1\left(x_1\right), F_2\left(x_2\right)\right]}{1-F_1\left(d_1\right)-F_2\left(d_2\right)+C\left[F_1\left(d_1\right), F_2\left(d_2\right)\right]} . \end{aligned} \end{equation*}\]
- Caso #2: Dato individual para \(X_1\) y dato agrupado para \(X_2\).
- Tenemos lo siguiente
\[\begin{equation*} \begin{aligned} &\frac{\frac{\partial}{\partial x_1} F\left(x_1, b_2\right)-\frac{\partial}{\partial x_1} F\left(x_1, a_2\right)}{1-F_1\left(d_1\right)-F_2\left(d_2\right)+F\left(d_1, d_2\right)} \\ &=\frac{f_1\left(x_1\right)\left\{C_1\left[F_1\left(x_1\right), F_2\left(b_2\right)\right]-C_1\left[F_1\left(x_1\right), F_2\left(a_2\right)\right]\right\}}{1-F_1\left(d_1\right)-F_2\left(d_2\right)+C\left[F_1\left(d_1\right), F_2\left(d_2\right)\right]} . \end{aligned} \end{equation*}\]
- Caso #3: Dato individual para \(X_2\) y dato agrupado para \(X_1\).
- \[\begin{equation*} \begin{aligned} &\frac{\frac{\partial}{\partial x_2} F\left(b_1, x_2\right)-\frac{\partial}{\partial x_2} F\left(a_1, x_2\right)}{1-F_1\left(d_1\right)-F_2\left(d_2\right)+F\left(d_1, d_2\right)} \\ &=\frac{f_2\left(x_2\right)\left\{C_2\left[F_1\left(b_1\right), F_2\left(x_2\right)\right]-C_1\left[F_1\left(a_1\right), F_2\left(x_2\right)\right]\right\}}{1-F_1\left(d_1\right)-F_1\left(d_2\right)+C\left[F_1\left(d_1\right), F_2\left(d_2\right)\right]} . \end{aligned} \end{equation*}\]
- Caso #4: Ambos datos agrupados.
- \[\begin{equation*} \begin{gathered} \frac{F\left(b_1, b_2\right)-F\left(a_1, b_2\right)-F\left(b_1, a_2\right)+F\left(a_1, a_2\right)}{1-F_1\left(d_1\right)-F_2\left(d_2\right)+F\left(d_1, d_2\right)} \\ \left\{C\left[F_1\left(b_1\right), F_2\left(b_2\right)\right]-C\left[F_1\left(a_1\right), F_2\left(b_2\right)\right]\right. \\ =\frac{\left.-C\left[F_1\left(b_1\right), F_2\left(a_2\right)\right]+C\left[F_1\left(a_1\right), F_2\left(a_2\right)\right]\right\}}{\left.1-F_1\left(d_1\right)-F_2\left(d_2\right)+C\left[F_1\left(d_1\right), F_2\left(d_2\right)\right)\right]} . \end{gathered} \end{equation*}\]
11.11 Simulación de copulas
Para efectos de análisis de la cópula y las marginales, es necesario definir un proceso para generación de valores aleatorios.
11.11.1 Cópulas Gaussianas
Un vector gaussiano \(d\)-dimensional tiene la caracteristica de que
\[\begin{equation*} X = \mu + LZ \end{equation*}\]
donde \(\Sigma=LL^{\top}\). Entonces para generar números aleatorios a partir de la cópula se puede hacer lo siguiente:
- Calcule el factor de Cholesky \(L\) de la matriz de correlación \(P\).
- Genera una muestra \(Z_1, \ldots, Z_d \stackrel{\text { ind. }}{\sim} \mathrm{N}(0,1)\).
- Calcule \(\boldsymbol{X}=L \boldsymbol{Z}\).
- Devuelve \(\boldsymbol{U}=\left(\Phi\left(X_1\right), \ldots, \Phi\left(X_d\right)\right)\).
11.11.2 Cópulas \(t\)
Este caso es similar al gaussiano, salvo una modificación:
- Calcule el factor de Cholesky \(L\) de la matriz de correlación \(P\).
- Genera una muestra \(Z_1, \ldots, Z_d \stackrel{\text { ind. }}{\sim} \mathrm{N}(0,1)\).
- Genere una muestra \(W\sim IG\left(\frac{\nu}{2},\frac{\nu}{2}\right)\) independiente de \(Z\).
- Calcule \(\boldsymbol{X}=\sqrt{W} L \boldsymbol{Z}\).
- Devuelve \(\boldsymbol{U}=\left(t_{\nu}\left(X_1\right), \ldots, t_{\nu}\left(X_d\right)\right)\).
11.11.3 Cópulas arquimedianas
Para el caso de las arquimedianas, primero hay que definir lo siguiente.
Sea \(V\) una variable aleatoria no negativa con distribución \(F\). La transformada de Laplace-Stielties de \(F\) está definida por \[\begin{equation*} \mathcal{LS}[F](t)=\int_0^{\infty} \exp (-t v) \mathrm{d} F(v)=\mathbb{E}(\exp (-t V)), \quad t \in[0, \infty) . \end{equation*}\]
La función \(F\) se puede recuperar a partir de la inversa \(\mathcal{LS}^{-1}[\psi]\). El uso de esta función es debido al teorema de Bernstein. Este dice que \(\psi\) es completamente monótona si y solo si \(\psi\) es la transformada de Laplace-Stielties de una distribución \(F\) en los reales positivos con \(F(0)=0\).
La variable aleatoria \(V\sim F\) se cononce como frailty y \(F\) es la distribución frailty.
Se puede probar que
\[\begin{equation*} \boldsymbol{U}=\left(\psi\left(\frac{E_1}{V}\right), \ldots, \psi\left(\frac{E_d}{V}\right)\right) \sim C \end{equation*}\]
donde \(E_1, \ldots, E_d \stackrel{\text { ind }}{\sim} \operatorname{Exp}(1)\) son independientes de\(V\).
El algoritmo general es
- Muestree \(V \sim F=\mathcal{L} \mathcal{S}^{-1}[\psi]\).
- Muestree \(E_1, \ldots, E_d \stackrel{\text { ind }}{\sim} \operatorname{Exp}(1)\), independiente de \(V\).
- Devuelva \(\boldsymbol{U}=\left(\psi\left(E_1 / V\right), \ldots, \psi\left(E_d / V\right)\right)\).
11.11.4 Laboratorio
Use el algoritmo de construcción de cópulas gaussianas con matrices covarianza \[\begin{equation*} \begin{pmatrix} 16 & 4 \\ 4 & 2 \end{pmatrix} \quad \begin{pmatrix} 1 & 0.5 \\ 0.5 & 1 \end{pmatrix} \end{equation*}\] Use 1000 valores. Compare ambos resultados.
Construya una copula normal asumiendo que la \(\tau_K=0.5\). Revise la función
iTaupara encontrar el parámetro correcto.Genere con
rCopulay haga el plot de estos resultados. Comparelos con el punto estos resultados. Comparelos con el punto 1.Suponga que se quiere simular una cópula \(t\) con 4 grados de libertad. Repita lo puntos 1 a 3 para este caso. W puede simularse como \(W=\nu / T\) con \(T \sim \chi_\nu^2\)
Para 5 variables, ajuste una cópula Gumbel con \(\tau_K=0.5\). Use
iTaude nuevo.Para generar manualmente los valores aleatorios de la cópula se necesita lo siguiente
family = "Gumbel"
cop <- getAcop(family)
V <- cop@V0(n, theta = parametro_de_iTau) Revise la ayuda de acopula. 7. Compare este resultado con rCopula.