En este capítulo aprenderás sobre expresiones regulares, un lenguaje conciso y poderoso para describir patrones dentro de cadenas de texto. Estas son abreviadas comúnmente como regex. Las expresiones regulares te permiten detectar, contar, extraer y modificar patrones en texto, lo cual es invaluable para tareas de análisis y limpieza de datos.
Para esta clase utilizaremos las funciones de expresiones regulares del paquete stringr de la colección tidyverse, así como datos del paquete babynames.
8.1 Conceptos básicos de patrones
El patrón más simple consiste en letras y números que coinciden exactamente con esos caracteres:
La mayoría de los caracteres de puntuación tienen significados especiales en regex y se llaman metacaracteres. Por ejemplo, el punto (.) coincide con cualquier carácter:
Los cuantificadores permiten controlar cuántas veces puede coincidir un patrón:
? coincide 0 o 1 veces.
+ coincide al menos 1 vez.
* coincide cualquier cantidad de veces, incluso 0.
str_view(c("a", "ab", "abb"), "ab?")
[1] │ <a>
[2] │ <ab>
[3] │ <ab>b
str_view(c("a", "ab", "abb"), "ab+")
[2] │ <ab>
[3] │ <abb>
str_view(c("a", "ab", "abb"), "ab*")
[1] │ <a>
[2] │ <ab>
[3] │ <abb>
Las clases de caracteres te permiten definir un conjunto de caracteres, por ejemplo, [aeiou] coincide con cualquier vocal. También puedes invertir el patrón usando ^.
Las expresiones regulares son sensibles a las mayúsculas por lo que el primer caso Aaban solo cuenta dos vocales. Podemos resolver esto de varias formas
Para reemplazar coincidencias, usamos str_replace() o str_replace_all().
x <-c("manzana", "pera", "banana")str_replace_all(x, "[aeiou]", "-")
[1] "m-nz-n-" "p-r-" "b-n-n-"
Esta función es útil para eliminar caracteres que cumplen con un patrón.
x <-c("apple", "pear", "banana")str_remove_all(x, "[aeiou]")
[1] "ppl" "pr" "bnn"
8.2.4 Extraer variables
La función separate_wider_regex() permite extraer datos a partir de un patrón en una columna.
df <-tribble(~str,"<Sheryl>-F_34","<Kisha>-F_45","<Brandon>-N_33","<Sharon>-F_38","<Penny>-F_58","<Justin>-M_41","<Patricia>-F_84",)df |>separate_wider_regex(str,patterns =c("<", nombre ="[A-Za-z]+", ">-", genero =".", "_", edad ="[0-9]+") )
# A tibble: 7 × 3
nombre genero edad
<chr> <chr> <chr>
1 Sheryl F 34
2 Kisha F 45
3 Brandon N 33
4 Sharon F 38
5 Penny F 58
6 Justin M 41
7 Patricia F 84
8.3 Detalles de patrones
8.3.1 Escapando caracteres especiales
Para hacer coincidir un carácter especial, como un punto, necesitamos “escaparlo” usando una doble barra invertida (\\). Por ejemplo:
str_view(c("abc", "a.c", "bef"), "a\\.c")
[2] │ <a.c>
Si se necesita encontrar un carácter como ., *, +, ?, ^, $, |, (, ), [, {, }, \, se puede escapar con \\ o se usar como una clase [.], [*], [+], etc.
str_view(c("abc", "a.c", "a*c", "a c"), "a[.]c")
[2] │ <a.c>
str_view(c("abc", "a.c", "a*c", "a c"), ".[*]c")
[3] │ <a*c>
8.3.2 Anclas
Las anclas permiten que el patrón coincida solo al principio (^) o al final ($) de una cadena.
El operador \b coincide con el límite de una palabra, es decir, el espacio entre un carácter de palabra y un carácter que no es de palabra. Esto permite coincidir con palabras completas.
x <-c("summary(x)", "summarize(df)", "rowsum(x)", "sum(x)")str_view(x, "sum")
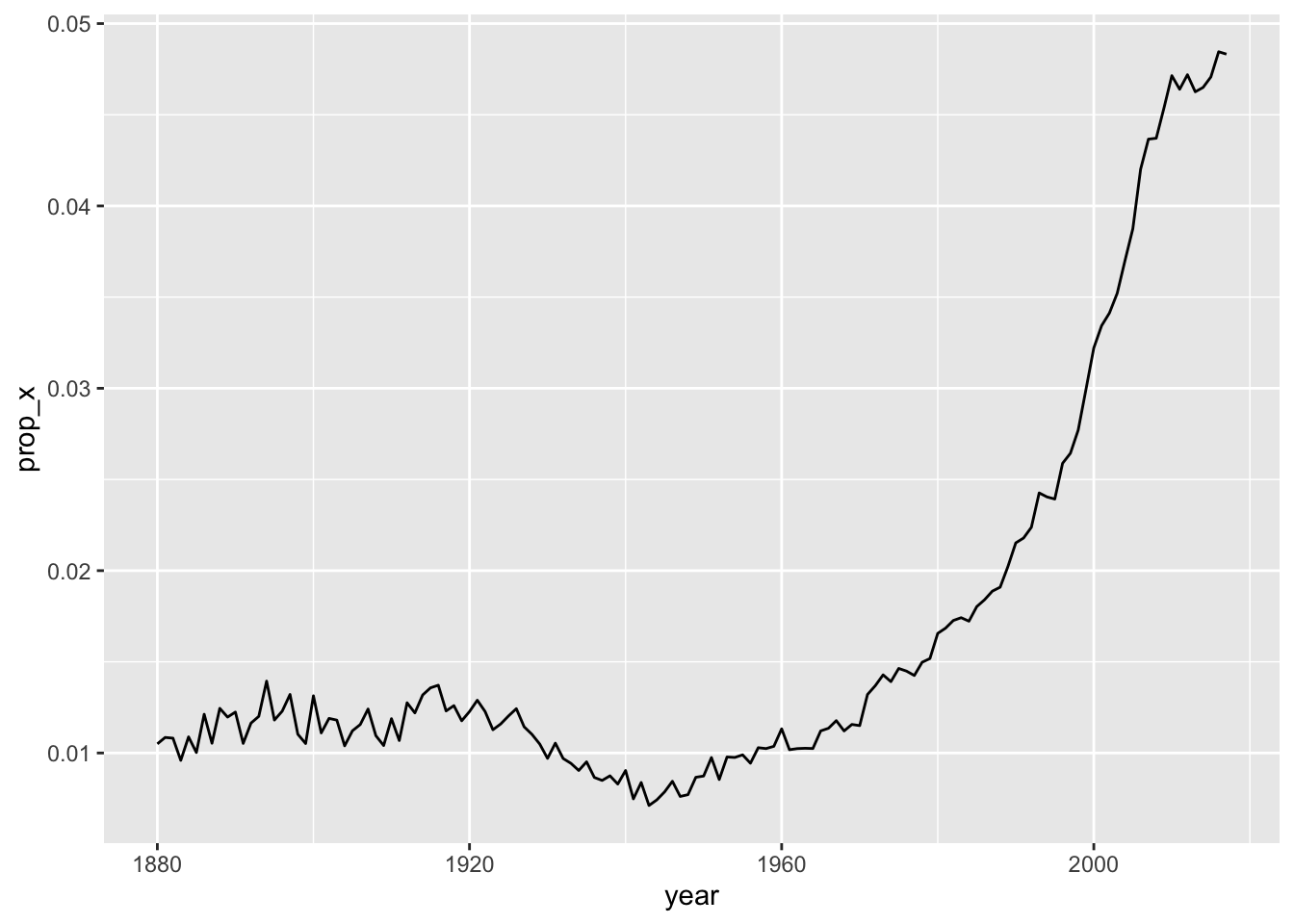
Vamos a jugar con https://wordly.org/ para practicar con expresiones regulares.
Tenemos esta base de datos de las soluciones de wordle: Soluciones Wordle.
wordle <-read_csv("data/wordle_solutions.csv")
Rows: 2315 Columns: 1
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): word
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
dim(wordle)
[1] 2315 1
head(wordle)
# A tibble: 6 × 1
word
<chr>
1 aback
2 abase
3 abate
4 abbey
5 abbot
6 abhor
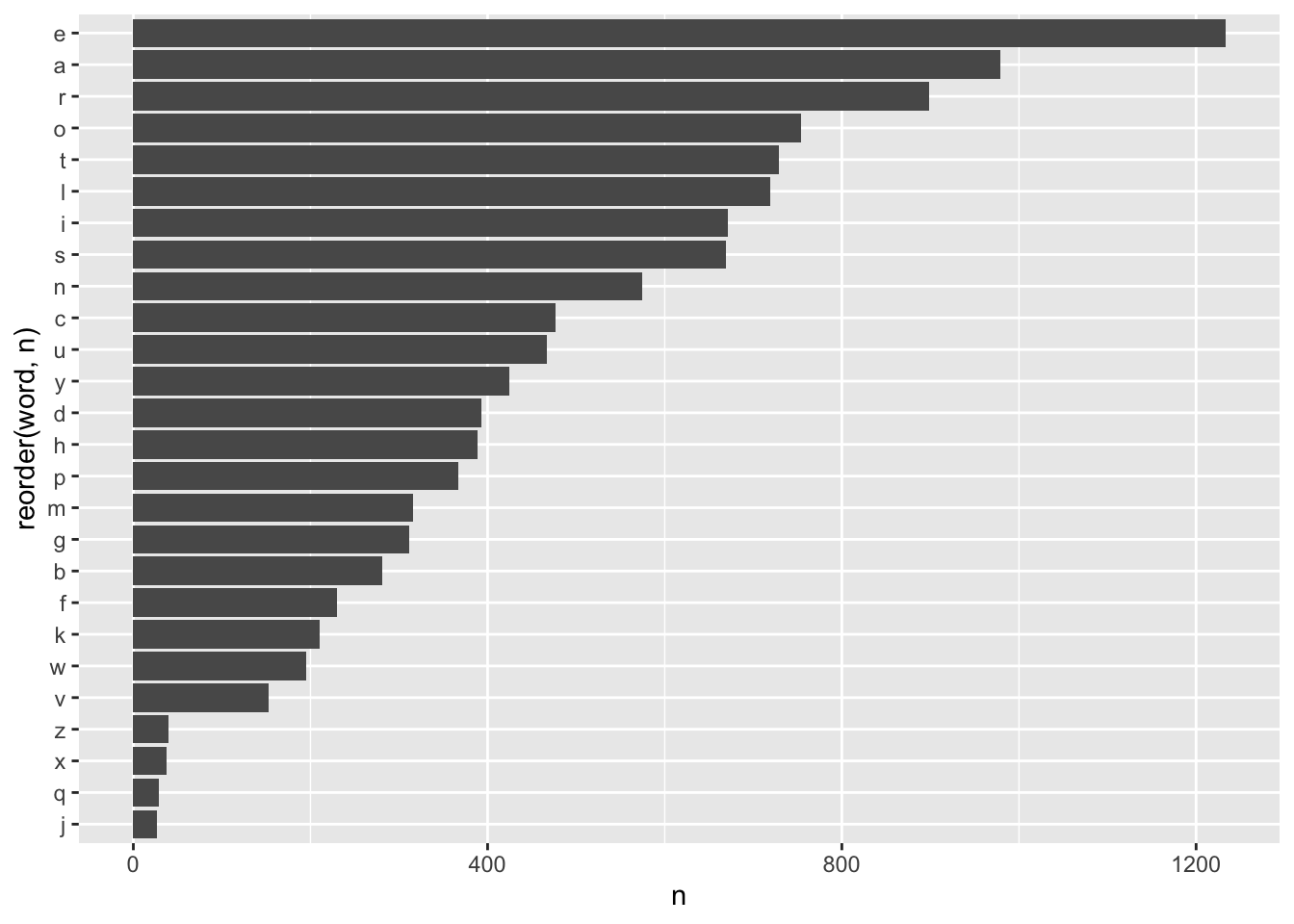
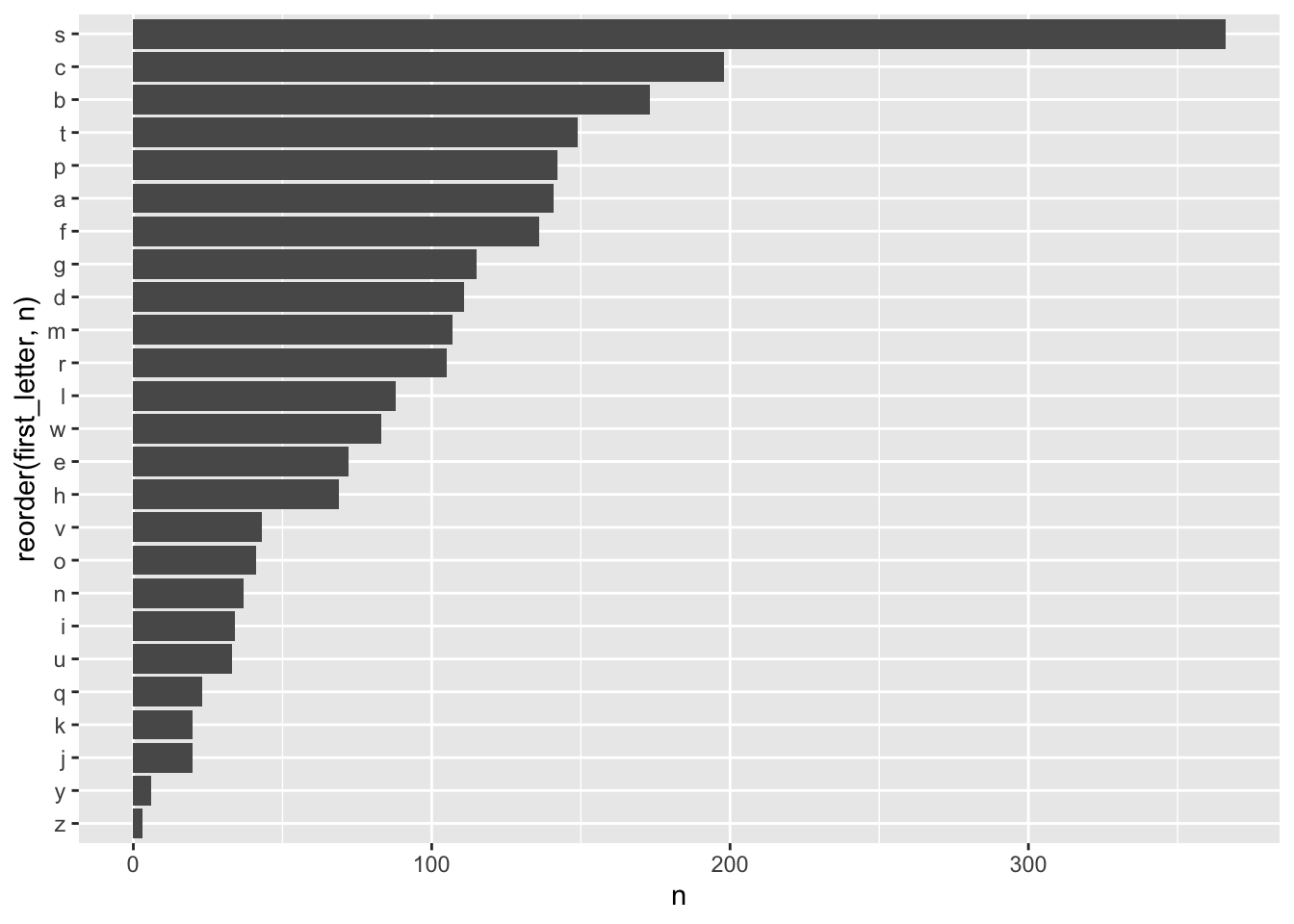
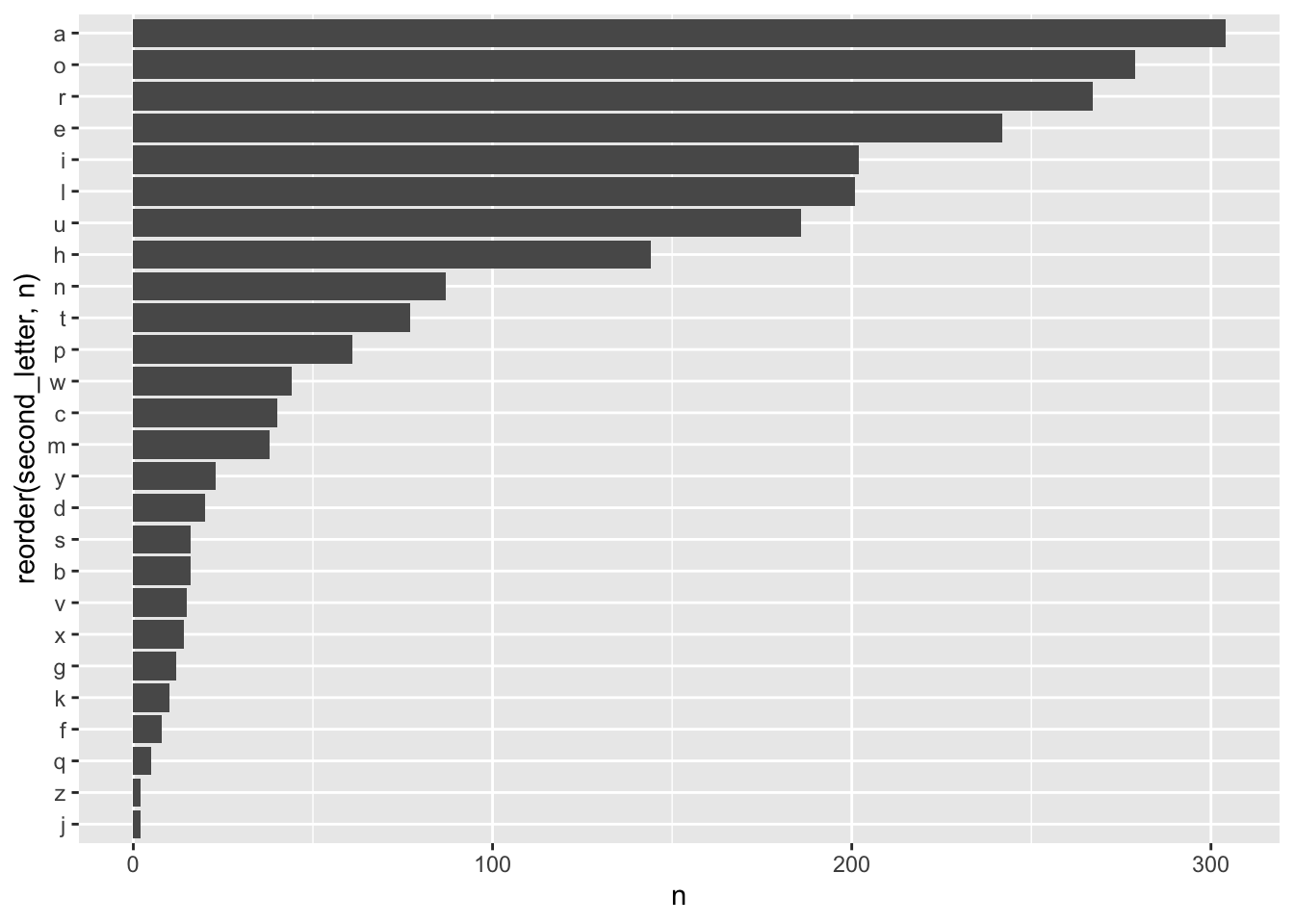
Ahora hagamos un pequeño análisis de los datos. Primero revisemos cuales letras son las más comunes en las soluciones.
# A tibble: 78 × 1
word
<chr>
1 abbot
2 adapt
3 aglow
4 album
5 allay
6 allot
7 allow
8 alloy
9 alpha
10 awful
# ℹ 68 more rows
El problema acá es la posición de las letras “t”, “o”, “l” y “a” también importan. Entonces para esto usaremos la expresión regular (?=) que significa “lookahead”.