Al finalizar este capítulo, el estudiante será capaz de:
Recordar la estructura del estadístico \(\chi^2\) de Pearson y su distribución asintótica bajo \(H_0\).
Comprender por qué los grados de libertad se reducen en \(s\) unidades cuando se estiman \(s\) parámetros (\(k-1-s\)).
Aplicar la prueba \(\chi^2\) de bondad de ajuste a datos categóricos y a datos continuos agrupados, usando chisq.test.
Analizar cuándo la aproximación \(\chi^2\) es válida (regla \(np_i^0\ge 5\)) y qué hacer si no se cumple.
Evaluar el ajuste de una distribución parametrizada estimando \(\theta\) por máxima verosimilitud y contrastando los dos límites de grados de libertad.
En los ejemplos que hemos visto siempre hemos necesitado una distribución de referencia que nos permita calcular los cuantiles correspondientes. Sin embargo, es posible que ese supuesto no se cumpla, o que la distribución no sea normal por ejemplo. En estos casos primero se debe de considerar una prueba de hipótesis para revisar las condiciones de nuestros datos. Una familia de problemas no paramétricos surgen a partir de esta observación.
En los temas vistos hasta ahora hemos asumido que nuestros datos siguen una distribución en particular, a menudo la distribución normal. Hemos utilizado esta suposición para realizar inferencias algunas inferencias (intervalos de confianza y pruebas de hipótesis). Pero, ¿qué pasa si nuestros datos no siguen la distribución que supusimos? ¿Cómo sabríamos si nuestra suposición es correcta?
Aquí es donde entran en juego las pruebas de bondad de ajuste. Estas pruebas nos permiten comparar nuestros datos con una distribución de referencia teórica y hacer una decisión objetiva sobre si la distribución de nuestros datos se ajusta suficientemente bien a la distribución teórica.
Si encontramos que nuestros datos no se ajustan a la distribución supuesta, entonces tendríamos que considerar el uso de métodos estadísticos no paramétricos. De esta forma se puede evitar algunos supuestos sobre nuestro problema.
En este capítulo, revisaremos toda una familia de problemas y métodos estadísticos no paramétricos diseñados específicamente para trabajar con datos que no cumplen con las suposiciones de las técnicas estadísticas paramétricas estándar.
13.1 Datos Categóricos y Prueba de Chi-Cuadrada
Imagina que tienes datos categóricos. Esta es una clase de datos donde la variable en cuestión puede caer en un número finito de categorías o estados.
Los datos categóricos son una clase de datos donde la variable en cuestión puede caer en un número finito de categorías o estados.
En un escenario como este, cada categoría tiene una probabilidad asociada, representada por \(p_i\), donde \(i\) es el número de la categoría. Así, tenemos \(k\) categorías y \(p_i\) para cada \(i\) de 1 a \(k\). El total de estas probabilidades debe sumar 1, es decir, \(\displaystyle \sum_{i=1}^kp_i = 1\).
Además, se pueden tener supuestos teóricos sobre esas probabilidades para cada categoría. Podemos definir, \(p_1^0,\dotsc,p_k^0\), y nuevamente, su suma también debe ser 1.
Así, puedes plantear una prueba de hipótesis:
La probabilidad para cada categoría es igual a la probabilidad propuesta. \[\begin{equation*}
H_0: p_i = p_i^0\text{ para } i=1,\dots,k
\end{equation*}\]
La probabilidad para al menos una categoría es diferente de la propuesta. \[\begin{equation*}
H_1: p_i \ne p_i^0\text{ para al menos un }i
\end{equation*}\]
Ejemplo 13.1 Por ejemplo, supongamos que estás estudiando la distribución de tipos de sangre en la población. La variable puede caer en una de las cuatro categorías posibles:
Categoría
Tipo de sangre
1
A
2
B
3
AB
4
O
Si sigues con nuestro ejemplo, podrías querer probar la siguiente hipótesis sobre la distribución de los tipos de sangre:
Categoría
Tipo de sangre
Hipótesis (\(p_i ^{0}\))
1
A
1/3
2
B
1/8
3
AB
1/24
4
O
1/2
En este contexto, suponga que recoges una muestra de \(n\) individuos. Deja \(N_i\) ser el número de individuos en tu muestra que caen en la categoría \(i\). Por lo tanto, \(\sum _{i=1}^kN_i = n\).
Es importante notar que el conjunto de estas cuentas de categorías, \((N_1,\dots,N_k)\), sigue una distribución multinomial con parámetros \((p_1, \dots, p_k)\), i.e., \[
(N_1,\dots,N_k) \sim \text{Multinomial}(n,p_1,\dots,p_k).
\]
Observación. Una distribución multinomial tiene la siguiente forma:
El número esperado de elementos en la categoría \(i\) es \(n\cdot p_i^0\). Si la diferencia \(N_i -np_i^0\) es cercana a 0 para cada categoría, es un indicio de que nuestra hipótesis nula \(H_0\) podría ser cierta.
En 1900, Karl Pearson demostró que si el tamaño de la muestra \(n\) es grande y el número de categorías \(k\) es “relativamente” pequeño en comparación con \(n\), bajo la hipótesis nula \(H_0\), la estadística \(Q\) sigue una distribución chi-cuadrada con \(k-1\) grados de libertad:
\[
Q \xrightarrow[H_0]{}\chi^2_{k-1}.
\]
Para un nivel de significancia dado \(\alpha\), rechazamos la hipótesis nula si \(Q\geq c\), donde \(c\) es el valor crítico tal que:
\[
\mathbb P_{H_0}[Q\geq c]\le \alpha\implies c = F^{-1}_{\chi^2_{k-1}}(1-\alpha)
\]
Es una medida que cuantifica cuánto varían los datos observados con respecto a lo que se esperaría si la hipótesis nula fuera cierta. Para entenderla mejor vamos a desglosar cada uno de sus componentes:
\(\text{observado}_{i}\) es la cantidad de observaciones reales para la categoría \(i\) en la muestra.
\(\text{esperado}_{i}\) es la cantidad de observaciones que esperamos para la categoría \(i\) bajo la hipótesis nula.
\((\text{observado}_{i} - \text{esperado}_{i})^2\) es el cuadrado de la diferencia entre los observado y epserado. Se toma cuadrado para eliminar signos y centrarnos en la magnitud de la diferencia.
\((\text{observado}_{i} - \text{esperado}_{i})^2/\text{esperado}_{i}\) es la diferencia al cuadrado normalizada por la cantidad esperada. Esto nos permite comparar las diferencias entre las categorías, independientemente de la cantidad de observaciones esperadas para cada categoría.
ImportanteReglas empíricas
La aproximación \((Q\sim\chi^2_{k-1})\) funciona bien si \(np_i^0\geq 5\).
La aproximación es adecuada si \(np_i^0\ge 1.5\) para todas las categorías \(i=1,\dots,k\).
Ejemplo 13.2 Vamos a continuar con el ejemplo de los tipos de sangre en una muestra de 6004 personas de raza blanca en California. Después de recolectar los datos, se construye esta tabla:
Grupo
Observado (\(n_i\))
Teórico (\(p_i ^{0}\))
A
2162
1/3
B
738
1/8
AB
228
1/24
O
2876
1/2
Vamos a probar la hipótesis nula \(H_0: p_i = p_i^0\) para \(i=1,2,3,4\).
Los valores esperados bajo la hipótesis nula serían:
Chi-squared test for given probabilities
data: observado
X-squared = 20.359, df = 3, p-value = 0.000143
Código
import numpy as npfrom scipy import statsobservado = np.array([2162, 738, 228, 2876])probabilidad_hipotetica = np.array([1/3, 1/8, 1/24, 1/2])# f_exp = n * p0 ; chisquare exige que las frecuencias esperadas sumen lo mismores = stats.chisquare( f_obs=observado, f_exp=observado.sum() * probabilidad_hipotetica,)print(f"Q = {res.statistic:.4f}")
Q = 20.3591
Código
print(f"valor-p = {res.pvalue:.6e}")
valor-p = 1.430022e-04
Ejemplo 13.3 Consideremos un conjunto de 100 observaciones, \(X_i\), con \(i=1,2,\dots,100\) y \(0 < X_i < 1\). Supongamos que estas observaciones siguen una función de densidad \(f\), la cual es continua. Nos gustaría probar las siguientes hipótesis: \[
H_0: f=\text{Unif}(0,1) \text{ vs } H_1: f \ne\text{Unif}(0,1).
\]
Para esto, dividimos el intervalo [0,1] en 20 niveles, de tal manera que una observación \(X_j\) pertenece al nivel \(i\) si se cumple que:
\[
\dfrac{i-1}{20}\leq X_j <\dfrac{i}{20}.
\]
Es decir, construimos una nueva estructura de frecuencias de la forma:
\(\text{Nivel}\)
\(1\)
\(2\)
\(\cdots\)
\(20\)
\(\text{Frecuencia}\)
\(N_1\)
\(N_2\)
\(\cdots\)
\(N_{20}\)
donde \(N_i\) es el número de observaciones que están en el intervalo \(i\).
\(i\)
\(X_i\)
\(\text{Grupo}\)
\(1\)
\(X_1\)
\(2\)
\(2\)
\(X_2\)
\(4\)
\(3\)
\(X_3\)
\(17\)
\(\vdots\)
\(\vdots\)
\(\vdots\)
\(100\)
\(X_{100}\)
\(20\)
Las hipótesis anteriores son equivalentes a suponer que cada nivel tiene la misma probabilidad de ser escogido, es decir,
\[
H_0: p_i = \dfrac{1}{20}, \;i=1,\dots,20.
\]
El número esperado de observaciones en cada nivel bajo la hipótesis nula es \(np_i^0 = 100\cdot\dfrac 1{20} = 5,\;i = 1,\dots,20\).
Definimos el estadístico de prueba como
\[
Q = \sum_{i=1}^{20}\dfrac{(N_i-5)^2}{5}.
\]
Rechazamos la hipótesis \(f = \text{Unif}(0,1)\) si \(Q>\chi^2_{19, 1-\alpha}\).
Nota
Este método es aplicable para cualquier tipo de distribución. Para aplicarlo, debemos seguir estos pasos:
Particionamos la recta real o el intervalo que contiene nuestros datos en \(k\) subintervalos disjuntos, de manera que todos los datos estén contenidos en este intervalo.
Determinamos las probabilidades hipotéticas \(p_i ^{0}\) que asignaremos a cada subintervalo. El valor esperado para cada subintervalo será \(n p_i ^{0}\).
Contamos las observaciones que caen en cada subintervalo, y denominamos este valor \(N_i\).
Calculamos el estadístico de prueba \(Q\) y tomamos una decisión respecto a la hipótesis nula. Bajo la hipótesis nula, \(Q\) debe seguir una distribución \(\chi ^{2}\) con \(k-1\) grados de libertad.
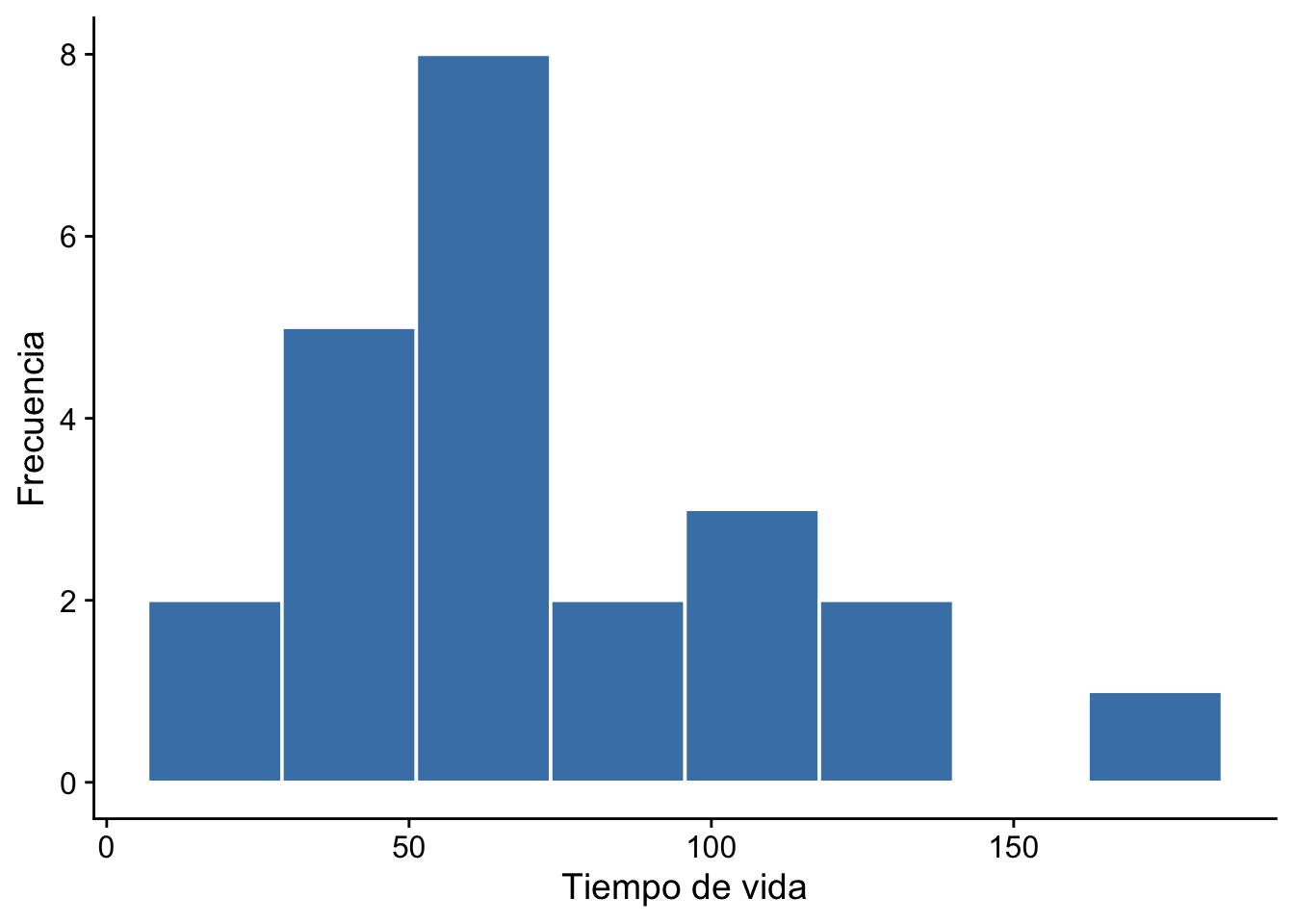
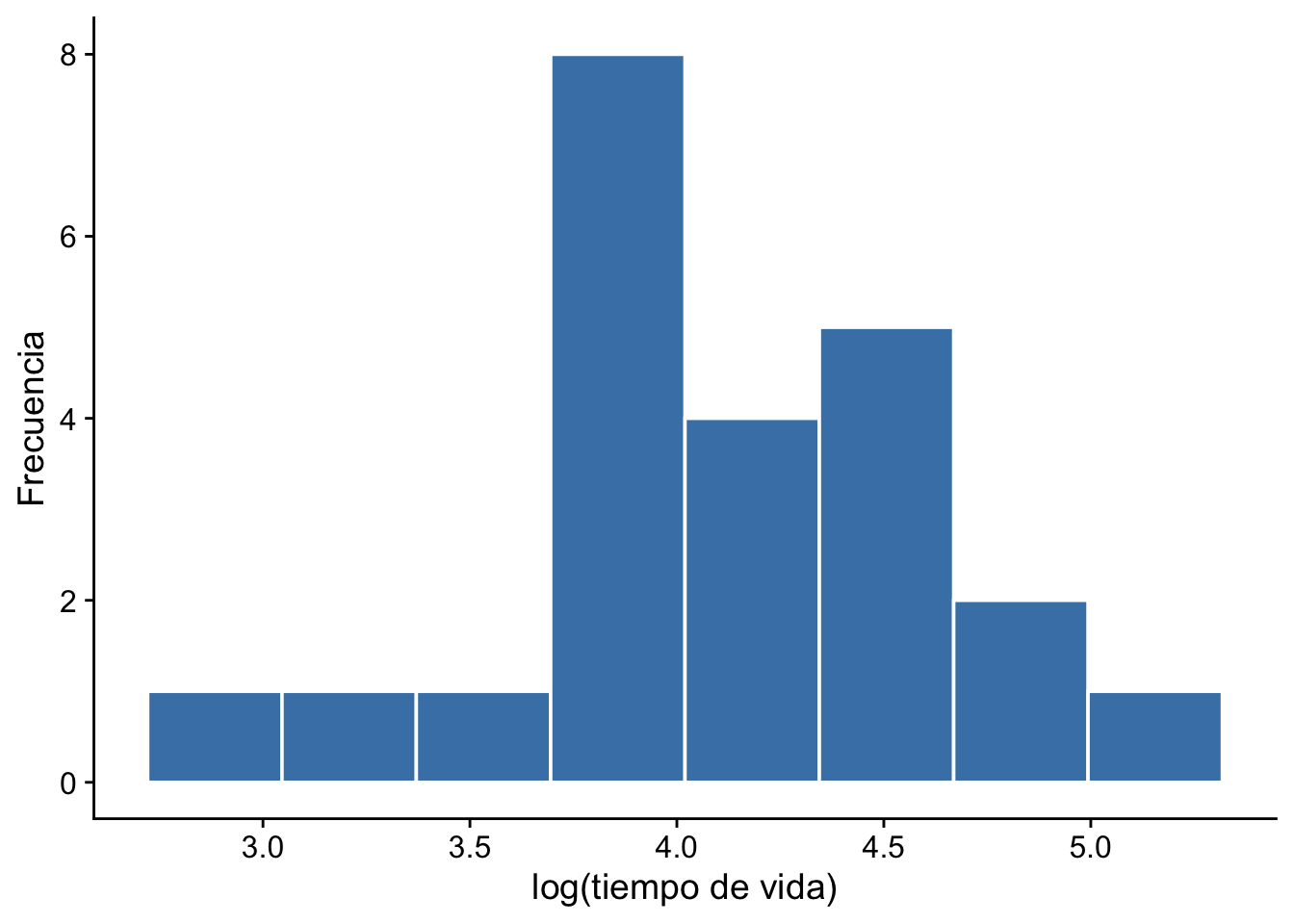
Ejemplo 13.4 Supongamos que tenemos 23 observaciones correspondientes al tiempo de vida útil de ciertas partes mecánicas de automóviles. Trabajaremos con el logaritmo del tiempo de vida de estos dispositivos. Los datos son los siguientes:
Código
x <-c(17.88,28.92,33,41.52,42.12,45.6,48.8,51.84,51.96,54.12,55.56,67.8,68.44,68.64,68.88,84.12,93.12,98.64,105.12,105.84,127.92,128.04,173.4)log_x <-log(x)
Código
ggplot(data.frame(x), aes(x)) +geom_histogram(bins =8, fill ="steelblue", color ="white") +labs(x ="Tiempo de vida", y ="Frecuencia") + cowplot::theme_cowplot()ggplot(data.frame(log_x), aes(log_x)) +geom_histogram(bins =8, fill ="steelblue", color ="white") +labs(x ="log(tiempo de vida)", y ="Frecuencia") + cowplot::theme_cowplot()
De acuerdo con estos gráficos, nos gustaría probar las siguientes hipótesis:
\[
H_0: f = N(\log(50),0.25) \quad vs \quad H_1: f \neq N(\log(50),0.25)
\]
Elegimos un número de grupos \(k\) tal que la probabilidad de que el log-tiempo pertenezca al i-ésimo intervalo sea mayor o igual a \(\dfrac 5{23}\approx \dfrac 14\). Es decir:
El valor-\(p\) corresponde a \(P(\chi^2_3 \ge 3.609) = 1-F_{\chi^2_3}(3.609) = 0.307\).
Código
chisq.test(resumen_conteos)
Chi-squared test for given probabilities
data: resumen_conteos
X-squared = 3.6087, df = 3, p-value = 0.3069
Con un nivel de significancia de 30%, no rechazamos la hipótesis de que los datos siguen una distribución normal con los parámetros especificados.
Importante
La función chisq.test si no se llama con ninguna hipótesis nula p, esta asume que \(p = 1/n\) para cada categoría. En este caso como son 4 categorías sería \(1/4\).
Importante
Una elección diferente de parámetros podría llevar a la aceptación de la hipótesis nula.
13.2 Pruebas \(\chi^2\) con hipótesis parametrizadas
En la sección anterior, hemos realizado una prueba para verificar si nuestros datos siguen una distribución normal con media \(\log(50)\) y varianza \(0.25\) (es decir, desviación estándar \(\sqrt{0.25}=0.5\)). Los resultados de la prueba nos indicaron que estos parámetros no son adecuados para nuestros datos.
Una pregunta natural que surge es: ¿qué parámetros serían los correctos? ¿Pertenecen los datos a una distribución normal?
Para abordar este problema, vamos a considerar una técnica que nos permita parametrizar nuestras hipótesis. En lugar de asumir que cada probabilidad \(p_i\) es fija, vamos a considerar que cada \(p_i\) es una función de algunos parámetros \(\theta = (\theta_1,\dots,\theta_s)\), es decir,
\[
p_i = \pi_i(\theta),\quad i=1,\dots,k.
\]
Asumimos que \(s<k-1\) y que las componentes de \(\theta\) no son redundantes, es decir, ninguna de las entradas de \(\theta\) se puede expresar como una función de las otras. Además, la suma de las probabilidades parametrizadas es igual a 1, es decir, \(\sum \pi_i(\theta) = 1\).
Nuestras hipótesis se vuelven:
Hipótesis nula (\(H_0\)): \(p_i = \pi_i(\theta)\) para algún parámetro \(\theta\in\Omega,\;i=1,\dots,k\).
Hipótesis alternativa (\(H_1\)): la hipótesis nula no es cierta.
donde \(\hat\theta\) es el estimador de máxima verosimilitud (MLE, por sus siglas en inglés) de \(\theta\), y \(N_i\) es el número de observaciones en el i-ésimo grupo.
Teorema 13.1 Bajo la hipótesis nula, cuando el número de observaciones \(n\) tiende al infinito, la distribución de \(Q\) tiende a una distribución \(\chi^2\) con \(k-1-s\) grados de libertad.
Ejemplo 13.5 Supongamos que tenemos 3 grupos y definimos un parámetro \(0<\theta<1\). El analista hace el supuesto de que las probabilidades son:
Notamos que la suma de estas probabilidades es 1, es decir, \(p_1+p_2+p_3=1\), ya que \[
p_1+p_2+p_3 = \theta^2 + 2\theta(1-\theta) +(1-\theta)^2 =[\theta+(1-\theta)]^2 = 1.
\]
Aquí \(s = 1\), y el espacio de parámetros es \(\Omega = [0,1]\).
Dado que la distribución de las observaciones \((N_1,\dots,N_k)\) sigue una distribución multinomial con parámetros \(n\) y \(p_1,\dots,p_k\) bajo la hipótesis nula, podemos escribir la función de verosimilitud como
Entonces las hipótesis del problema son \[\begin{align*}
H_{0}: & \ p_{1}=0.2025,\ p_{2}=0.495,\ p_{3}=0.3025 \\
H_{1}: & \ p_{i} \neq \pi_i(\hat\theta) \text{ para al menos un } i.
\end{align*}\]
Ahora el estadístico de prueba es \[\begin{multline*}
Q = \dfrac{(20-100\cdot 0.2025)^2}{100\cdot 0.2025} + \dfrac{(50-100\cdot 0.495)^2}{100\cdot 0.495} \\
+ \dfrac{(30-100\cdot 0.3025)^2}{100\cdot 0.3025} = 0.0102.
\end{multline*}\]
Esto se debe comparar con una distribución \(\chi^2\) con 1 grado de libertad. \(\chi^2_{1,0.95} =\) 3.8414588.
Rechazamos la hipótesis nula si \(Q>\chi^2_{1,0.95}\).
En este caso no rechazamos la hipótesis nula. El valor-\(p\) asociado a este estadístico es \(\mathbb{P}(\chi^2_{1} > 0.0102) \approx 0.92\), muy alto. Esto es esperable: como \(\theta\) se estimó por máxima verosimilitud a partir de estos mismos datos, las frecuencias esperadas \(n\,\pi_i(\hat\theta)\) quedan muy cerca de las observadas, de modo que el modelo binomial ajusta bien.
Ejemplo 13.6 (Partes de automóvil) Retomemos el ejemplo de las partes de un automóvil, y recordemos que tenemos una muestra de datos \(X_1,\dots,X_n\) que provienen de alguna distribución \(f\). Queremos probar la hipótesis de que la distribución es normal con media \(\mu\) y varianza \(\sigma^2\), ambas desconocidas, es decir, \(H_0: f = N(\mu,\sigma^2)\).
Para hacer esto, podemos construir las funciones de probabilidad parametrizadas \(\pi\), tratando de ajustar los cuantiles que habíamos definido antes con los valores teóricos de \(\mu\) y \(\sigma\). Entonces, para cada partición \(i\) con límites \(a_i\) y \(b_i\), la función de probabilidad se convierte en:
A continuación, se muestra cómo podemos calcular la verosimilitud y optimizarla numéricamente en R:
Código
# Definición de los cortes de los cuantilescortes <-qnorm(p =c(0, 1/4, 2/4, 3/4, 1),mean =log(50),sd =sqrt(0.25))# Definición de la función de log-verosimilitudlog_versomilitud <-function(par, cortes, log_x) { G <-length(cortes) mu <- par[1] sigma <- par[2] pi <-numeric()for (k in1:(G -1)) { pi[k] <-pnorm(q = cortes[k +1], mean = mu, sd = sigma) -pnorm(q = cortes[k], mean = mu, sd = sigma) } conteos <-cut(log_x, breaks = cortes) conteos <-summary(conteos) l <--sum(conteos *log(pi))return(l)}# Optimización numérica de la función de log-verosimilitudsol <-optim(par =c(0, 1),fn = log_versomilitud,cortes = cortes,log_x = log_x)# Imprime los parámetros optimizadossol$par
[1] 4.0926455 0.4331326
Con esta información podemos calcular las probabilidades \(\pi_1(\hat \mu,\hat \sigma^2)\),\(\pi_2(\hat \mu,\hat \sigma^2)\),\(\pi_3(\hat \mu,\hat \sigma^2)\) y \(\pi_4(\hat \mu,\hat \sigma^2)\), y el estadístico de prueba \(Q\).
Ahora se compara con una \(\chi^2\) con \(k-1-s = 4 - 1 - 2 = 1\) grado de libertad (hay \(k=4\) grupos y se estimaron \(s=2\) parámetros, \(\mu\) y \(\sigma^2\); no se usa el número de observaciones \(n=23\)). Es decir, nos preguntamos si rechazamos la hipótesis nula \(H_0\) de que los datos provienen de una distribución normal con media \(\mu\) y varianza \(\sigma^2\).
Código
Q2 >qchisq(p =0.95, df =1)
[1] FALSE
El valor-p es:
Código
pchisq(q = Q2, df =1, lower.tail =FALSE)
[1] 0.5040037
Para otra solución, considere el siguiente teorema:
Teorema 13.2 Si \(X_1,\dots, X_n\) son variables aleatorias con distribución \(F_\theta\), donde \(\theta\) es un parámetro \(p\)-dimensional y \(\hat\theta_n\) es el estimador de máxima verosimilitud (MLE) de \(\theta\) basado en \(X_1,\dots, X_n\). Tomamos una partición de \(\mathbb R\) con \(k\) intervalos disjuntos \((I_1,\dots,I_k)\), donde \(N_i\) es la cantidad de \(X_i\) que caen en el intervalo \(I_i\) y \(\pi_i(\theta)=\mathbb P_\theta[X_i\in I_i]\). Entonces, se tiene el siguiente estadístico de prueba:
Bajo las condiciones de regularidad del MLE, si \(n\to\infty\), la función de distribución acumulada de \(Q'\) asumiendo \(H_0\) verdadero está entre \(\chi^2_{k-p-1}\) y \(\chi^2_{k-1}\).
Ejemplo 13.7 Apliquemos este teorema a nuestros datos, calculando \(\hat\mu = \bar{X}_n = 4.1506137\) y \(\hat\sigma = s_n = 0.5332049\) (de modo que \(\hat\sigma^2 = 0.2843\)). Tomamos la partición de los datos en los siguientes 4 intervalos:
Por el teorema anterior, el verdadero valor-\(p\) se encuentra entre estas dos cotas, es decir, entre \(0.247\) y \(0.720\). Como ambas superan los niveles usuales de significancia, no rechazamos \(H_0\) (hipótesis de normalidad) a, por ejemplo, \(\alpha = 0.05\).
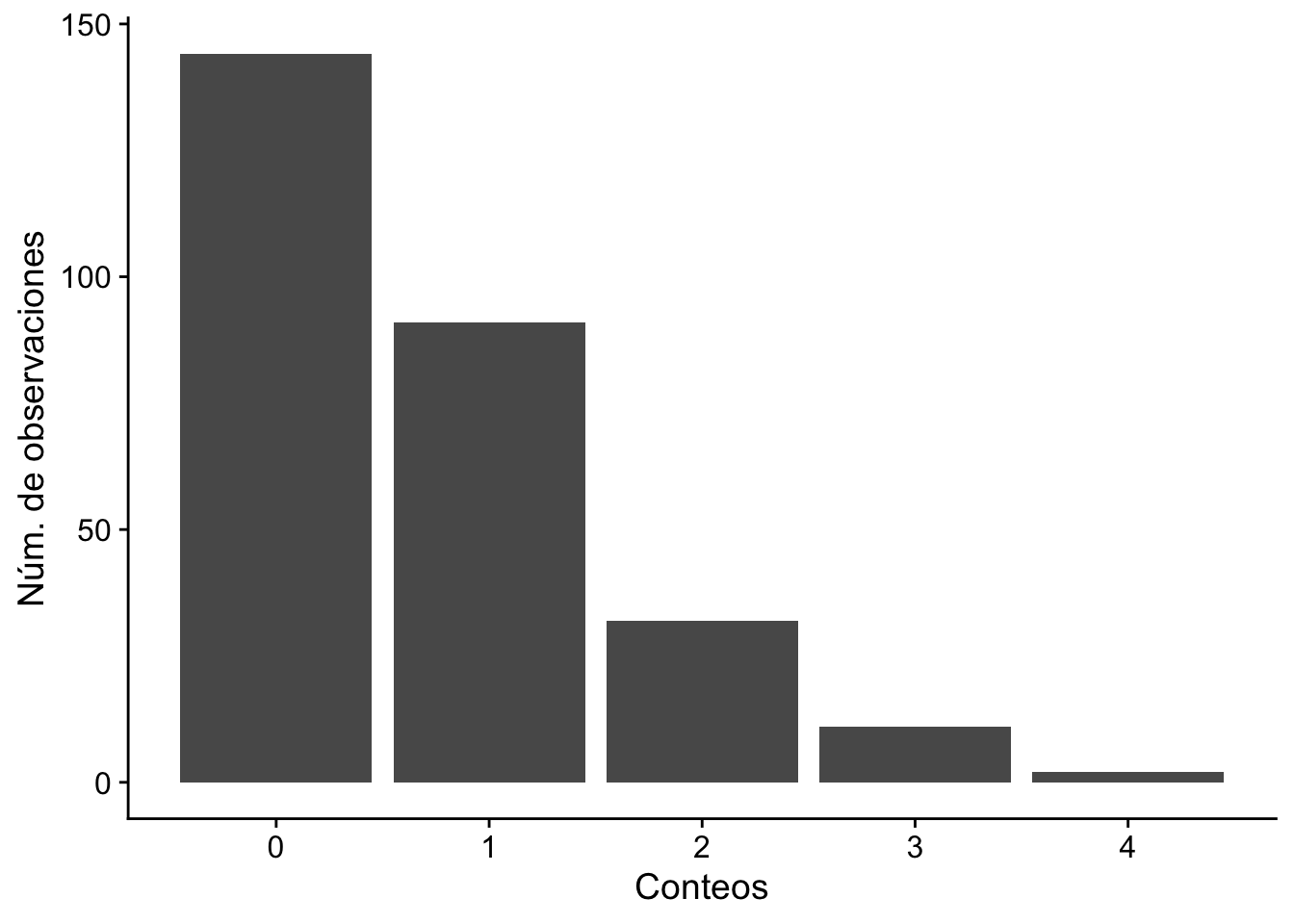
Ejemplo 13.8 Recordemos el conjunto de datos históricos sobre el número de muertes causadas por patadas de caballo en el ejército prusiano. El conjunto de datos es el siguiente:
\(\text{Conteos}\)
\(0\)
\(1\)
\(2\)
\(3\)
\(\ge 4\)
\(\text{Total}\)
\(\text{Núm. de obs.}\)
\(144\)
\(91\)
\(32\)
\(11\)
\(2\)
\(280\)
Nos preguntamos si estos datos siguen una distribución de Poisson. Podemos visualizar los datos en un gráfico de barras utilizando el siguiente código R:
Código
df <-data.frame(conteos =c(0, 1, 2, 3, 4),observaciones =c(144, 91, 32, 11, 2))ggplot(df, aes(x = conteos, y = observaciones)) +geom_col() +labs(x ="Conteos", y ="Núm. de observaciones") + cowplot::theme_cowplot()
Formulamos la hipótesis nula como sigue: \(H_0: f = \text{Poisson}(\theta), \theta>0\).
Podemos calcular el estimador de máxima verosimilitud (MLE) de \(\theta\) como la media ponderada del número de muertes por su frecuencia, es decir,
Interpretamos nuestros resultados: si tomamos un nivel de significancia del 5%, no podemos rechazar la hipótesis nula de que los datos siguen una distribución de Poisson.
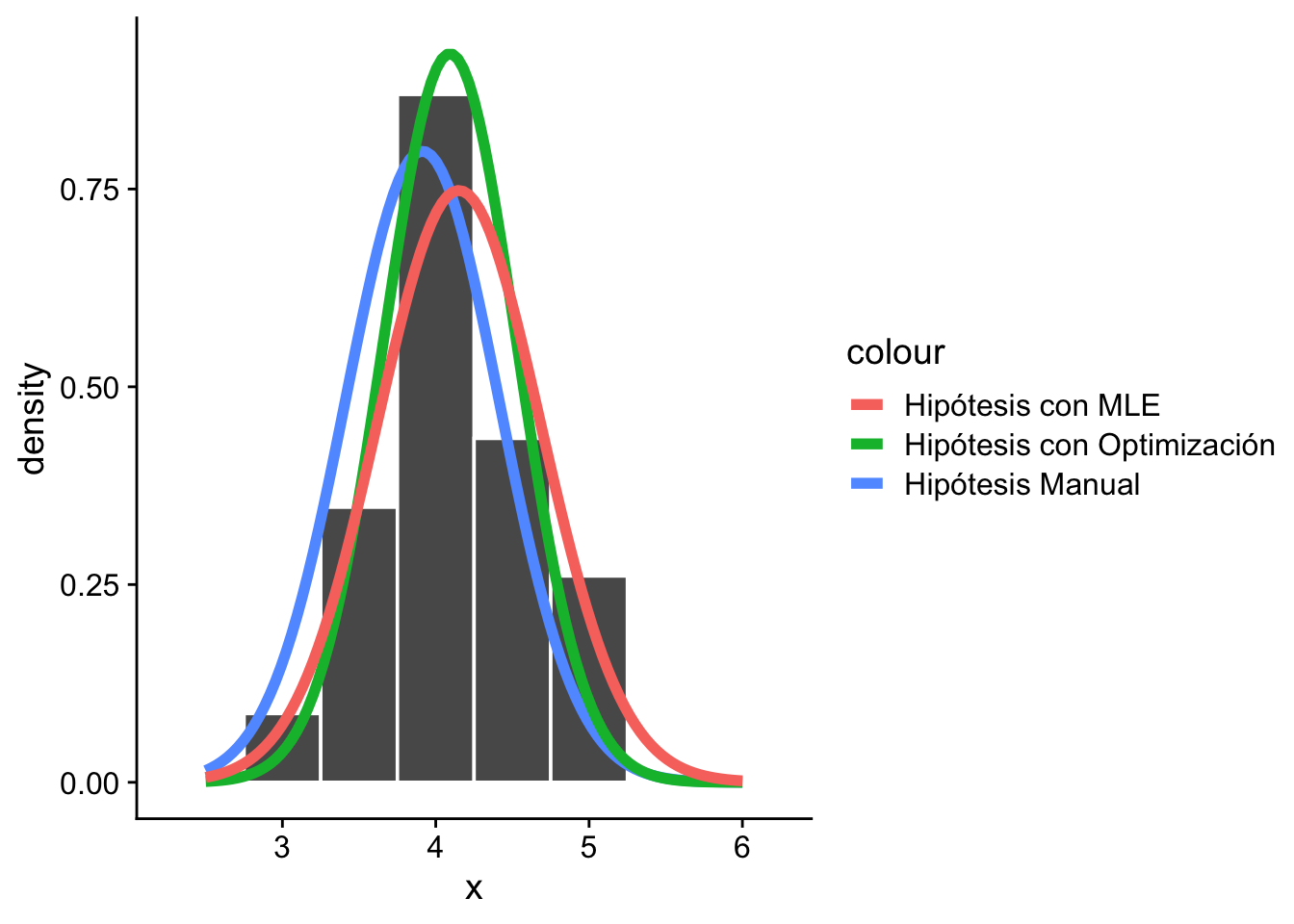
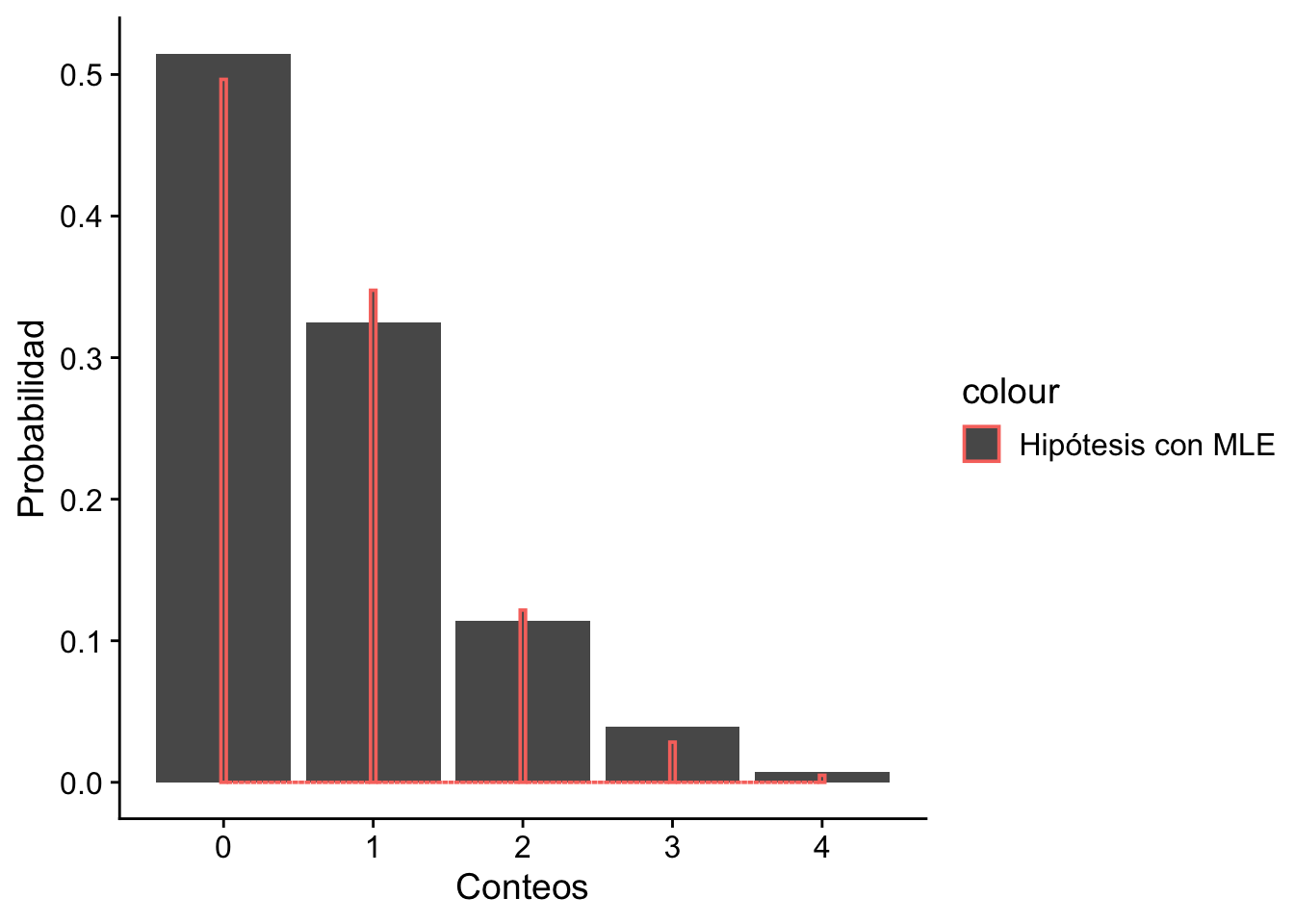
Finalmente, podemos visualizar nuestra prueba de bondad de ajuste en un gráfico de barras que compara las observaciones reales con las esperadas bajo la distribución de Poisson con \(\hat\theta = 0.7\).
El cálculo completo del estadístico \(Q'\) y de los valores-\(p\) en ambos lenguajes:
Finalmente, podemos visualizar nuestra prueba de bondad de ajuste en un gráfico de barras que compara las observaciones reales con las esperadas bajo la distribución de Poisson con \(\hat\theta = 0.7\).
Código
total <-sum(df$observaciones)ggplot(data =data.frame(x =c(0, 4)), aes(x)) +geom_col(data = df, aes(x = conteos, y = observaciones / total)) +stat_function(fun = dpois,args =list(lambda =0.7),aes(color ="Hipótesis con MLE"),size =2,geom ="col" ) +labs(x ="Conteos", y ="Probabilidad") + cowplot::theme_cowplot()
TipIdeas clave — prueba \(\chi^2\) de bondad de ajuste
Compara frecuencias observadas con las esperadas bajo \(H_0\) mediante \(Q=\sum_i (O_i-E_i)^2/E_i\).
Si las probabilidades \(p_i^0\) están fijas, \(Q\to\chi^2_{k-1}\); si se estiman \(s\) parámetros por MLE, los grados de libertad bajan a \(k-1-s\) (donde \(k\) es el número de grupos, no de observaciones).
La aproximación requiere frecuencias esperadas suficientes (regla práctica \(np_i^0\ge 5\)); si alguna categoría es muy pequeña, conviene agruparla con otra.
El valor-\(p\) es siempre la cola superior\(P(\chi^2\ge Q)\), no la CDF.
13.3 Resumen
La siguiente tabla reúne los casos de la prueba \(\chi^2\) de bondad de ajuste vistos en el capítulo.
En todos los casos se rechaza \(H_0\) si \(Q\ge \chi^2_{\text{df},\,1-\alpha}\), equivalentemente si el valor-\(p=P(\chi^2_{\text{df}}\ge Q)\) es menor que \(\alpha\).