4Densidades previas conjugadas y estimadores de Bayes
NotaObjetivos de aprendizaje
Al finalizar este capítulo, el estudiante será capaz de:
Definir la distribución previa y la distribución posterior en el marco bayesiano, e interpretar su significado estadístico.
Calcular la distribución posterior a partir de una verosimilitud y una previa, aplicando el teorema de Bayes.
Identificar familias conjugadas para los modelos más comunes (Exponencial, Bernoulli/Binomial, Poisson, Normal) y usarlas para simplificar el cálculo de la posterior.
Derivar estimadores bayesianos bajo distintas funciones de pérdida (cuadrática y absoluta), y relacionarlos con la media y mediana posterior.
Interpretar el efecto del tamaño de muestra sobre la distribución posterior y la consistencia del estimador bayesiano.
4.1 Distribución previa (distribución a priori)
Cuando trabajamos con un modelo estadístico con un parámetro desconocido \(\theta\), es común en el enfoque bayesiano considerar a \(\theta\) como una variable aleatoria. La distribución que describe nuestras creencias o conocimientos previos sobre \(\theta\) antes de observar cualquier dato se llama densidad previa y se denota por \(\pi(\theta)\).
Observación. La función de distribución previa \(\pi\) tiene las siguientes características.
Está definida en \(\Omega\) (espacio paramétrico).
Se establece antes de obtener cualquier muestra.
Hagamos algunos ejemplos para entender como funciona la densidad previa.
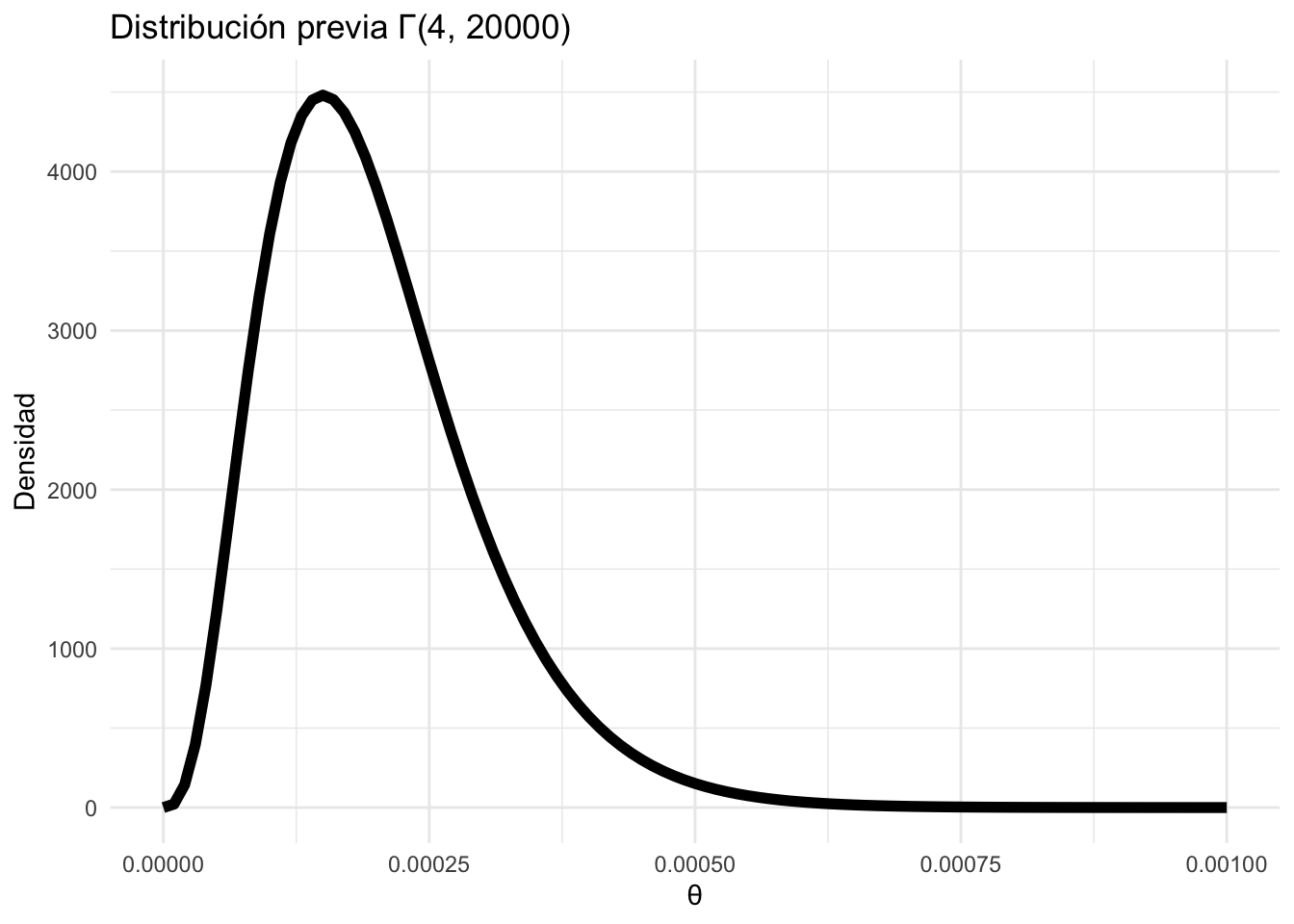
Ejemplo 4.1 (Componentes eléctricos) Consideremos el tiempo de vida de ciertos componentes que sigue una distribución exponencial \(X_1,\dots, X_n \sim \text{Exp}(\theta)\).
Si suponemos que \(\theta\) es una variable aleatoria que sigue una distribución Gamma con parámetros \(\alpha = 1\) y \(\beta = 2\), entonces la densidad previa de \(\theta\) es:
Ejemplo 4.2 (Lanzamiento de una moneda) Supongamos que estamos interesados en averiguar la probabilidad de obtener cara al lanzar una moneda, en un experimento donde hay dos tipos de monedas: las monedas justas y las monedas alteradas. Sin embargo, hay incertidumbre sobre qué moneda se va a utilizar en la siguiente lanzada, podría ser una moneda justa o una moneda alterada que siempre cae en cara, pero se sabe que su densidad previa sigue una distribución Gamma, por lo que antes de observar cualquier lanzamiento, modelamos nuestras creencias sobre \(\theta\), asumiendo la densidad previa calculada en el ejercicio anterior, de la siguiente manera:
Moneda justa: La probabilidad de que \(\theta = \dfrac{1}{2}\) es \(0.8\), i.e. , \(\pi(\frac{1}{2}) = 0.8\)
Moneda alterada: La probabilidad de que \(\theta = 1\) es \(0.2\), i.e. , \(\pi(1) = 0.2\).
Esto significa que si tuviéramos 100 monedas, esperaríamos que 20 de ellas fueran alterada y 80 fueran justas.
Ejemplo 4.3 (Componentes eléctricos (cont.)) Supongamos que estamos interesados en el tiempo de vida de un componente eléctrico. Sabemos que este tiempo se puede modelar con una distribución exponencial con parámetro \(\theta\). Además, basándonos en la experiencia de un experto, creemos que \(\theta\) tiene una distribución previa Gamma. El experto nos proporciona la siguiente información:
Dada la distribución Gamma, sus momentos están definidos en función de sus parámetros \(\alpha\) (forma) y \(\beta\) (tasa). Específicamente, para una variable aleatoria $ $ que sigue una distribución Gamma, sus momentos están dados por:
Muestra Aleatoria: Representamos la muestra aleatoria como un vector \(X = (X_1, X_2, \dots, X_n)\), donde cada \(X_i\) es una observación.
Densidad Conjunta: La densidad conjunta de \(X\) se denota como \(f_\theta(x)\).
Densidad Condicional: La densidad de \(X\) condicionada en el parámetro \(\theta\) se denota como \(f_n(x|\theta)\).
NotaSupuesto
Es esencial entender que para que \(X\) sea considerado como una muestra aleatoria, debe cumplir con la propiedad de ser condicionalmente independiente dado el parámetro \(\theta\). Matemáticamente, esto se traduce en:
Ejemplo 4.4 (Continuación de Ejemplo 4.3) Considerando el contexto del componente eléctrico discutido anteriormente, si tomamos una muestra \(X = (X_1, \dots, X_n)\) donde cada \(X_i\) sigue una distribución exponencial con parámetro \(\theta\) y \(X_i > 0\), la función de densidad conjunta condicionada en \(\theta\) se describe como:
Una vez que observamos los datos, actualizamos nuestras creencias sobre \(\theta\) usando el teorema de Bayes. La distribución resultante se llama densidad posterior y se denota por \(\pi(\theta|X)\).
Teorema 4.1 Dada una muestra aleatoria compuesta por las observaciones \(X_1, X_2, \dots, X_n\), podemos definir la densidad posterior de \(\theta\) como:
Esta expresión nos da la densidad posterior de \(\theta\) dada la muestra observada.
Ejemplo 4.5 (Componentes eléctricos (cont.)) Supongamos que tenemos una muestra \(X = (X_1, X_2, \dots, X_n)\) donde cada observación \(X_i\) sigue una distribución exponencial. La función de verosimilitud para esta muestra está dada por:
\[
f_n(X|\theta) = \theta^n e^{-\theta y}.
\]
Aquí, \(y = \sum_{i=1}^n X_i\) representa la suma total de las observaciones y actúa como un estadístico para \(\theta\).
Para calcular la densidad posterior de \(\theta\), necesitamos considerar tanto la función de verosimilitud como la densidad previa. Desglosemos esto en dos partes: el numerador y el denominador de la densidad posterior \(\pi(\theta\vert X)\):
Numerador: El numerador se compone de la función de verosimilitud y la densidad previa:
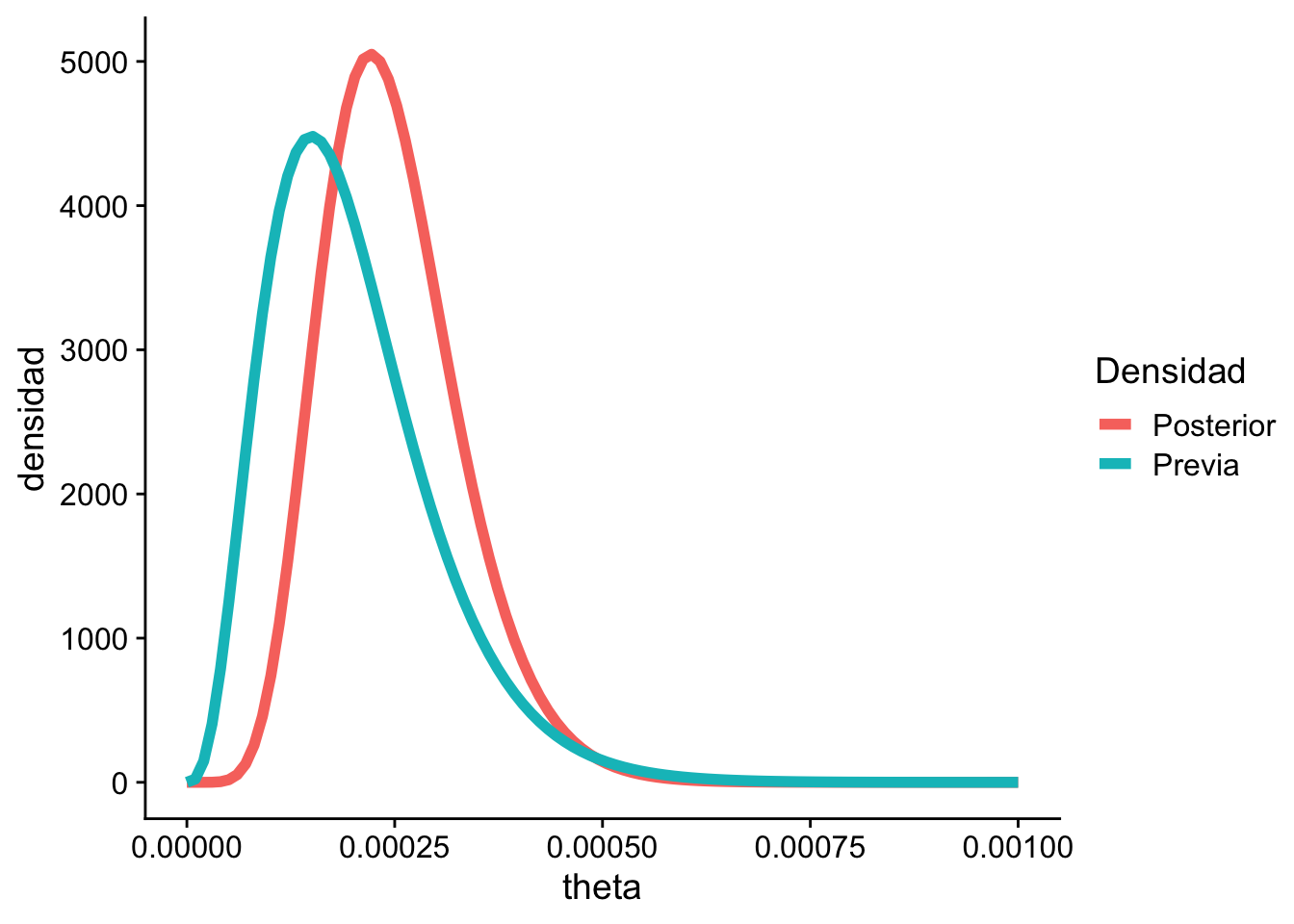
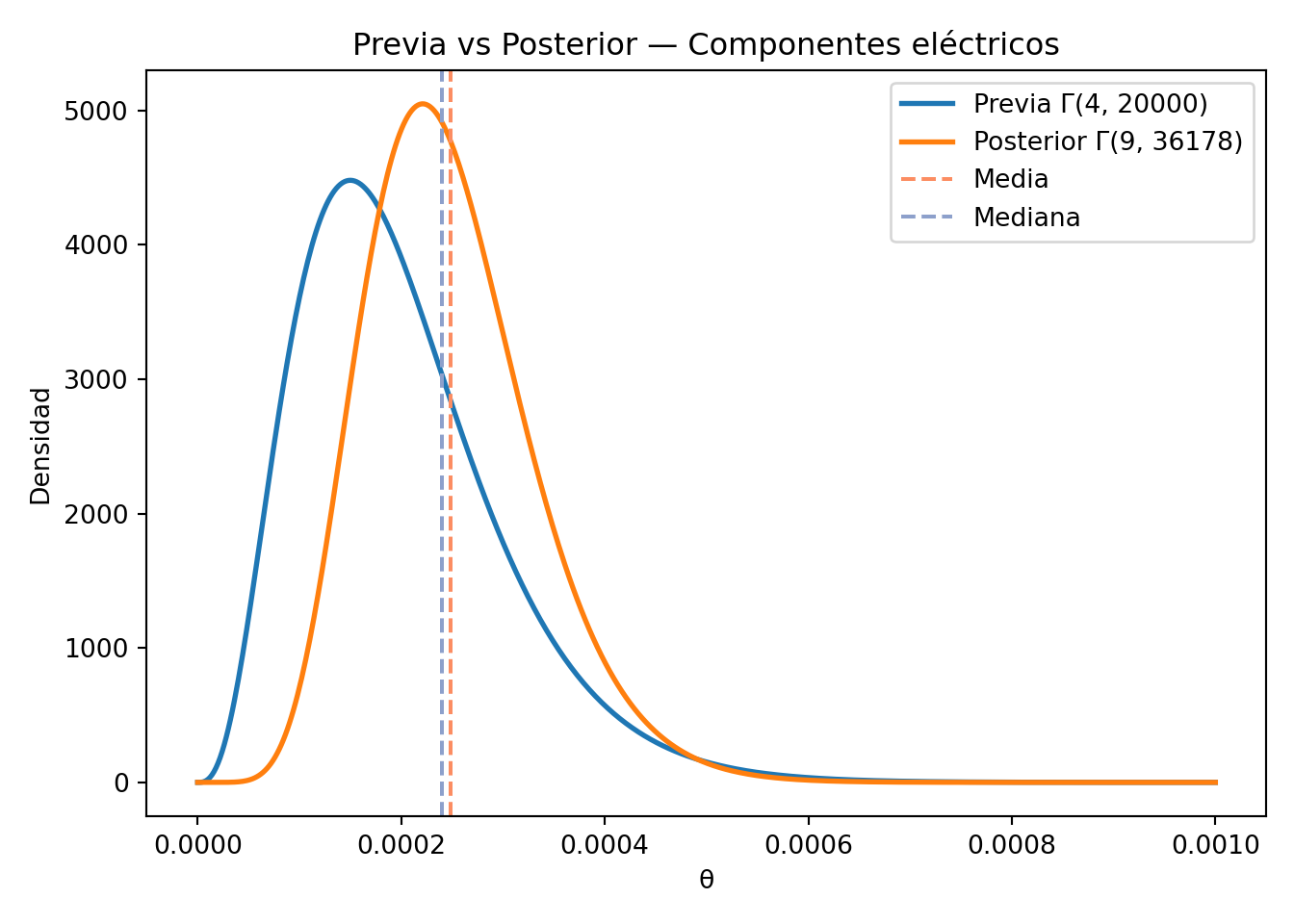
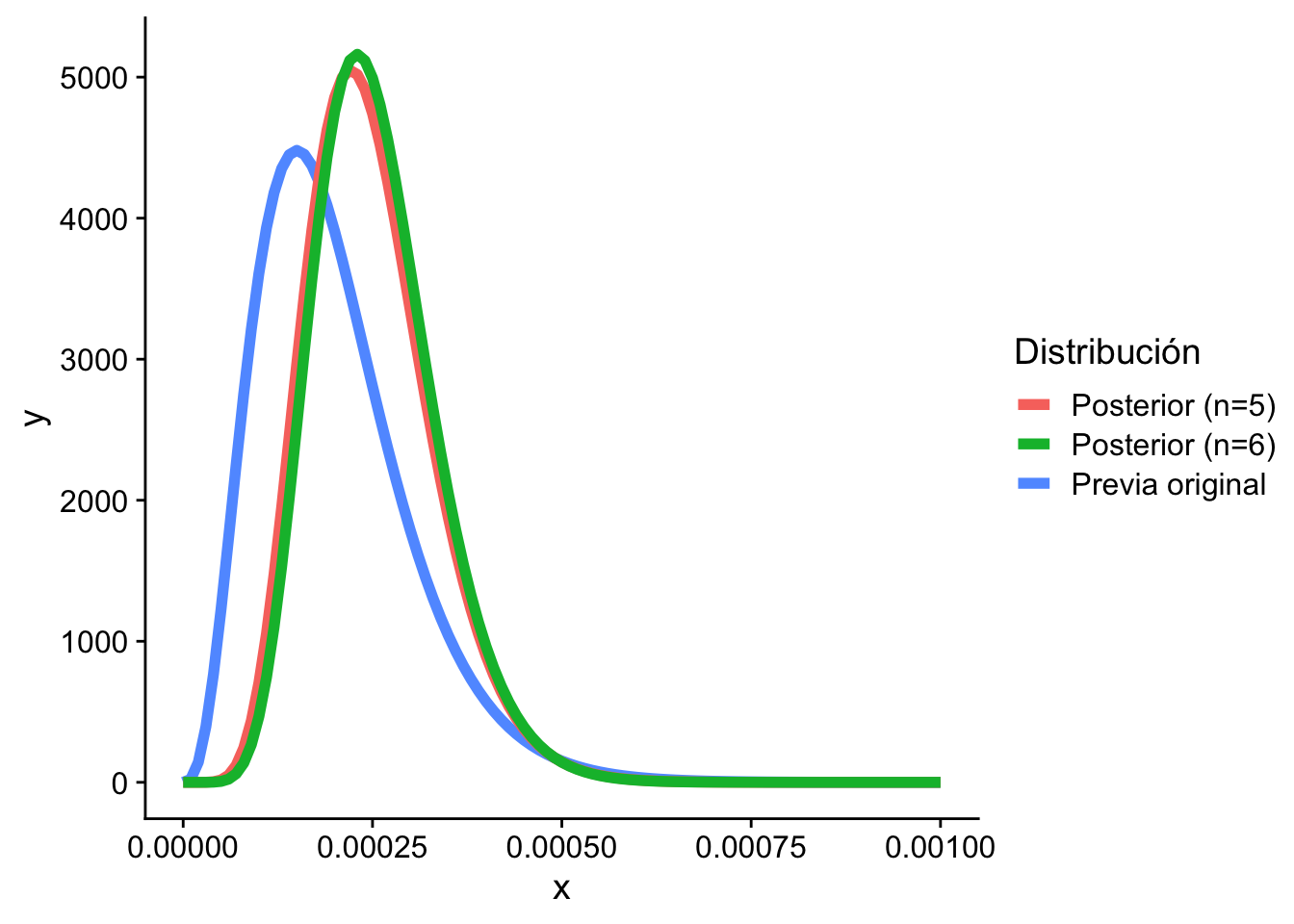
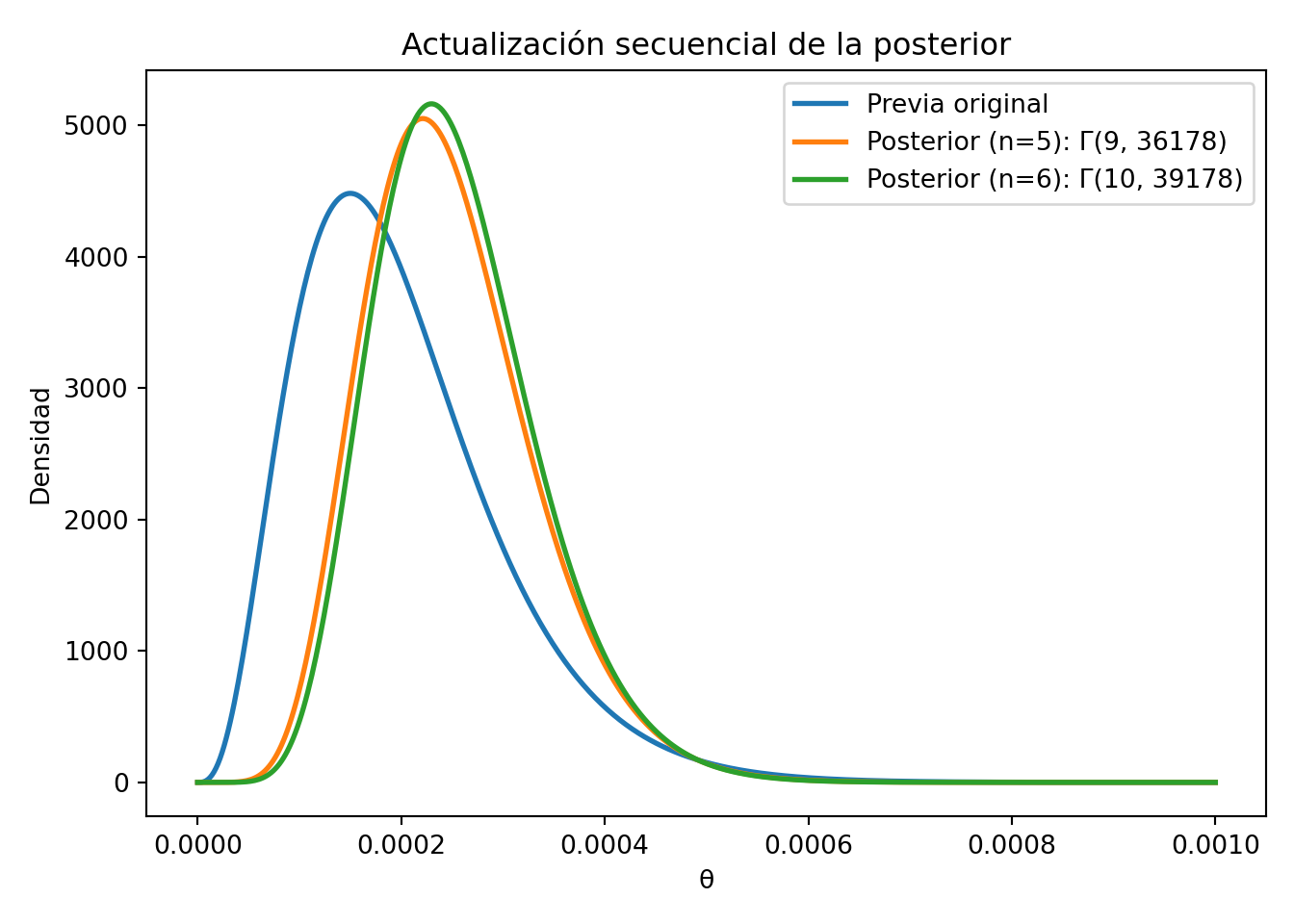
Esta densidad posterior sigue una distribución \(\Gamma(n+4, 20000+y)\).
Supongamos que observamos 5 tiempos de fallo: 2911, 3403, 3237, 3509, y 3118. Entonces, \(y = 16478\) y \(n = 5\). Con estos datos, la distribución posterior de \(\theta\) es \(\Gamma(9, 36178)\).
Figura 4.3
La distribución posterior es sensible al tamaño de la muestra. Es decir, que una muestra grande inicial, implica un efecto menor de la previa.
Observación. Le decimos Hiperparámetros a los parámetros de la previa o posterior.
4.3 Proceso de modelación de parámetros
De ahora en adelante vamos a entender un modelo como la unión de los siguientes componentes:
El conjunto de los datos \(X_1, \ldots, X_n\),
La función de densidad \(f\)
El parámetro de la densidad \(\theta\).
Estos dos últimos resumen el comportamiento de los datos.
Para identificar y trabajar con este modelo, lo desglosamos en las siguientes partes:
Información previa (\(\pi(\theta)\)): Esta es la información adicional o basada en la experiencia que tenemos sobre el modelo.
Verosimilitud: Los datos representan la información observada. La función de densidad \(f\) refina y mejora la información previa. La función \(f_n(X|\theta)\) se conoce como verosimilitud o función de verosimilitud y se define como:
Densidad posterior: Es una combinación de la información previa y los datos observados, proporcionando una versión más informada de la distribución del parámetro. Se calcula como:
Predicciones con datos nuevos: Si asumimos que los datos se obtienen secuencialmente, podemos calcular la distribución posterior de la siguiente manera:
Bajo la suposición de independencia condicional, no hay diferencia en la posterior si los datos se obtienen secuencialmente. Esta distribución nos ayuda a calcular probabilidades sobre datos nuevos. Por lo tanto:
Observación. En el caso de una función de verosimilitud, el argumento es \(\theta\) y los datos en \(X\) son fijos.
TipFlujo del proceso bayesiano
El proceso de inferencia bayesiana sigue siempre la misma estructura:
flowchart LR
A["Conocimiento previo\n π(θ)"] --> C["Distribución posterior\n π(θ|X)"]
B["Datos observados\n f_n(X|θ)"] --> C
C --> D["Estimador bayesiano\n δ*(X)"]
La posterior combina lo que sabíamos antes de ver los datos (previa) con la información aportada por los datos (verosimilitud). Cuantos más datos tengamos, menor será la influencia de la previa.
Ejemplo 4.6 (Proporción de componentes defectuosos) En ejemplos anteriores, abordamos los tiempos de vida de componentes defectuosos asumiendo un valor fijo para \(\theta\). Ahora, exploraremos cómo modelar este parámetro utilizando estadística bayesiana.
Consideremos un componente que puede ser defectuoso o no. Es natural modelar su comportamiento con una variable aleatoria \(X_i\) definida como:
Donde \(\theta\) representa la proporción de componentes defectuosos, con \(\theta \in [0,1]\). Una elección adecuada para modelar esta variable aleatoria es asumir que \(X_i \sim \mathrm{Bernoulli}(\theta)\).
Siguiendo los pasos anteriores, definamos
Distribución Previa (\(\pi(\theta)\)): Sin información previa sobre los componentes, asumimos que \(\theta\) sigue una distribución uniforme en el intervalo \([0,1]\):
\[
\pi(\theta) = 1_{\{0\leq\theta\leq 1\}}
\] Es importante notar que una distribución uniforme es equivalente a una distribución \(\mathrm{Beta}(1,1)\).
Función de Verosimilitud: Esta función representa la probabilidad de observar nuestros datos dados ciertos valores de \(\theta\):
\[
f_n(X\|\theta) = \theta^{\sum_{i=1}^{n} X_i}(1-\theta)^{n-\sum_{i=1}^{n} X_i} = \theta^{y}(1-\theta)^{n-y}
\] Donde \(y = \sum_{i=1}^{n} X_i\) es el número total de componentes que no fallaron.
Distribución Posterior: Combinando nuestra información previa (distribución previa) con la función de verosimilitud, obtenemos la distribución posterior de \(\theta\):
\[
\pi(\theta\|X) \propto \theta^y (1-\theta)^{n-y} = \theta^{y+1-1}(1-\theta)^{n-y+1-1}
\] De esta expresión, deducimos que, dada la información \(X\), \(\theta\) sigue una distribución \(\text{Beta}(y+1,n-y+1)\).
Observación. La distribución posterior anteriormente es exactamente
Sin embargo el operador \(\propto\) indica que el lado izquierdo es igual al lado derecho salvo por una constante que no depende de la variable (\(\theta\)). Esto es muy útil para evitar escribir mucho en las fórmulas.
Ejemplo 4.7 (Componentes eléctricos (cont.)) En el ejemplo Ejemplo 4.5, discutimos la modelación del tiempo de vida de componentes. Ahora supongamos que se nos presenta un nuevo dato, \(X_6\). Estamos interesados en determinar la probabilidad de que este nuevo componente tenga un tiempo de vida superior a 3000, es decir, \(P(X_6>3000|X_1,X_2,X_3,X_4,X_5)\).
Para calcular esta probabilidad, necesitamos determinar la función de densidad condicional \(f(X_6|X)\). Dado que la distribución posterior de \(\theta\) está dada por:
Observación. La vida media del componente se define como el tiempo en el cual la probabilidad de que el componente falle es del 50%. Matemáticamente, esto se expresa como:
\[
\dfrac{1}{2} = P(X_6>u|X)
\]
En este caso, lo que tendríamos es que \[\begin{align*}
\dfrac{1}{2} &= \int_{u}^{\infty} \dfrac{9.55\times10^{41}}{(X_6+36178)^{10}}\; dX_6 \\
&= \dfrac{ 9.55\times10^{41}}{-9(X_6+36178)^{9}}\Big|_{u}^{\infty} \\
&= \dfrac{ 9.55\times10^{41}}{9(u+36178)^{9}} \\
\end{align*}\]
Despejando tenemos que \[\begin{align*}
\dfrac{1}{2} &= \dfrac{ 9.55\times10^{41}}{9(u+36178)^{9}} \\
(u + 36178)^9 &= \dfrac{ 9.55\times10^{41}}{9\cdot 0.5} \\
u + 36178 &= \sqrt[9]{\dfrac{ 9.55\times10^{41}}{9\cdot 0.5}} \\
u &= \sqrt[9]{\dfrac{ 9.55\times10^{41}}{9\cdot 0.5}} - 36178 \\
u &= 2894
\end{align*}\]
En estadística bayesiana, las familias conjugadas desempeñan un papel fundamental al simplificar el proceso de actualización de nuestras creencias a medida que se obtienen nuevos datos. A continuación, se presenta una introducción detallada a este concepto.
Dada una muestra \(X_1, \dots, X_n\) que es independiente e idénticamente distribuida (i.i.d.) condicionalmente dado un parámetro \(\theta\) con densidad \(f(x\mid \theta)\), consideremos,\(\psi\) como la familia de posibles densidades previas sobre \(\Omega\).
Definición 4.1 Si, independientemente de los datos observados, la densidad posterior pertenece a la misma familia que \(\psi\), entonces decimos que \(\psi\) es una familia conjugada de previas.
Ejemplo 4.8
Para el Ejemplo Ejemplo 4.3, la familia Gamma es una familia conjugada para muestras exponenciales.
En el Ejemplo Ejemplo 4.6, la familia Beta es una familia conjugada para muestras según una Binomial.
Para el caso de datos que siguen una distribución Poisson, si \(X_1,\dots,X_n\sim\mathrm{Poisson}(\lambda)\),la familia Gamma es conjugada. La función de densidad de una Poisson es:
La verosimilitud, que es el producto de las densidades de los datos observados, se da por: \[\begin{equation*}
f_n(X|\lambda) = \prod_{i=1}^{n}e^{-\lambda}\dfrac{\lambda^{X_i}}{X_i!} = \dfrac{e^{-n\lambda}\lambda^{y}}{\prod_{i=1}^n X_i}.
\end{equation*}\] Si la previa de \(\lambda\) está definida por \(\pi(\lambda)\propto\lambda^{\alpha-1}e^{-\beta\lambda}\), entonces la posterior es: \[\begin{equation*}
\pi(\lambda|X) \propto \lambda^{y+\alpha-1}e^{-(\beta+n)\lambda} \implies \lambda|X \sim \Gamma(y+\alpha,\beta+n)
\end{equation*}\]
En el caso de datos que siguen una distribución normal, \(X_1,\dots,X_n\sim N(\theta,\sigma^2)\), la familia normal es conjugada si la varianza \(\sigma^2\) es conocida. Si \(\theta \sim N(\mu_0,V_0^2)\) entonces la posterior para \(\theta\) data la muestra es \(\sim N(\mu_1, V_1^2)\) donde,
Este resultado nos muestra cómo la información previa (representada por \(\mu_0\) y \(V_0^2\)) se combina con la información de la muestra (representada por \(\bar{X}_n\)) para producir una estimación posterior de \(\theta\).
En resumen, la tabla a continuación muestra algunas de las familias conjugadas más comunes en estadística bayesiana.
Ejemplo 4.9 Considere un conjunto de datos que sigue una distribución \(\mathrm{Poisson}(\lambda)\). Supongamos que nuestra creencia previa sobre \(\lambda\) está dada por:
Esta previa de \(\lambda\) sigue una distribución \(\Gamma(1,2)\).
Si tenemos una muestra aleatoria de tamaño \(n\), nos interesa determinar cuántas observaciones necesitamos para que la varianza de nuestra estimación de \(\lambda\) sea, a lo sumo, 0.01.
Para abordar esta pregunta, primero definimos \(y\) como la suma de nuestras observaciones, es decir,\(y=\sum_{i=1}^{n}X_i\). Utilizando el teorema de Bayes, podemos expresar nuestras distribuciones de la siguiente manera:
Para este caso, la distribución posterior es \(\lambda|x \sim \Gamma(y+1,n+2)\). La varianza de la distribución Gamma está dada por: \[\begin{equation*}
\mathrm{Var}(\lambda) = \dfrac{\alpha}{\beta^2} = \dfrac{y+1}{(n+2)^2}.
\end{equation*}\]
Por lo tanto, necesitamos al menos 8 observaciones para alcanzar la varianza deseada de 0.01 en nuestra estimación de \(\lambda\).
TipIdeas clave: Familias conjugadas
Una familia conjugada garantiza que la posterior pertenece a la misma familia que la previa, lo que simplifica enormemente los cálculos.
Los parámetros de la posterior (hiperparámetros) se actualizan sumando los suficientes estadísticos de los datos a los hiperparámetros previos.
La tabla anterior resume las familias conjugadas más utilizadas en la práctica.
El uso de previas impropias (\(\alpha = \beta = 0\)) es una estrategia cuando no se tiene información previa; en muchos casos produce una posterior propia y válida.
Retomemos el caso normal para entender cómo se construye la posterior en este caso.
Teorema 4.2 Si \(X_1,\dots,X_n \sim N(\theta, \sigma^2)\) con \(\sigma^2\) conocido y la previa es \(\theta \sim N(\mu_0,V_0^2)\), entonces \(\theta|X\sim N(\mu_1,V_1^2)\) donde \[\begin{equation*}
\mu_1 = \dfrac{\sigma^2\mu_0 + nV_0^2 \bar{X}_n}{\sigma^2 + nV_0^2}, \quad V_1^2 = \dfrac{\sigma^2V_0^2}{\sigma^2 + nV_0^2}
\end{equation*}\]
Demostración. Construyamos cada elemento por separado:
Si \(V_0^2\) y \(\sigma^2\) son fijos, entonces \(W_1 \xrightarrow[n\to \infty]{}0\) (la importancia de la media empírica crece conforme aumenta \(n\)).
Si \(V_0^2\) y \(n\) son fijos, entonces \(W_2 \xrightarrow[\sigma^2\to \infty]{}0\) (la importancia de la media empírica decrece conforme la muestra es menos precisa).
Si \(\sigma^2\) y \(n\) son fijos, entonces \(W_2 \xrightarrow[V_0^2\to \infty]{}1\) (la importancia de la media empírica crece conforma la previa es menos precisa).
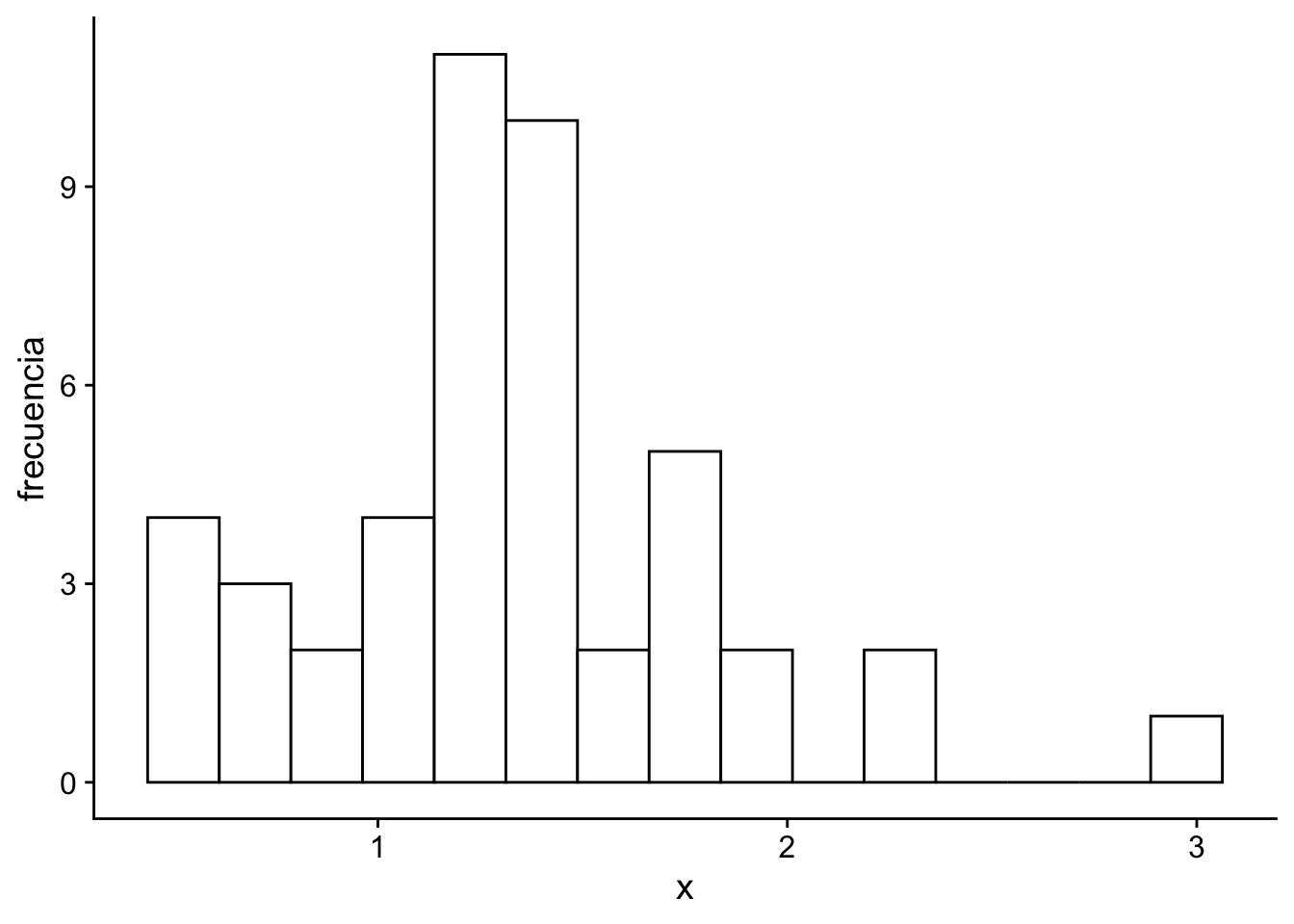
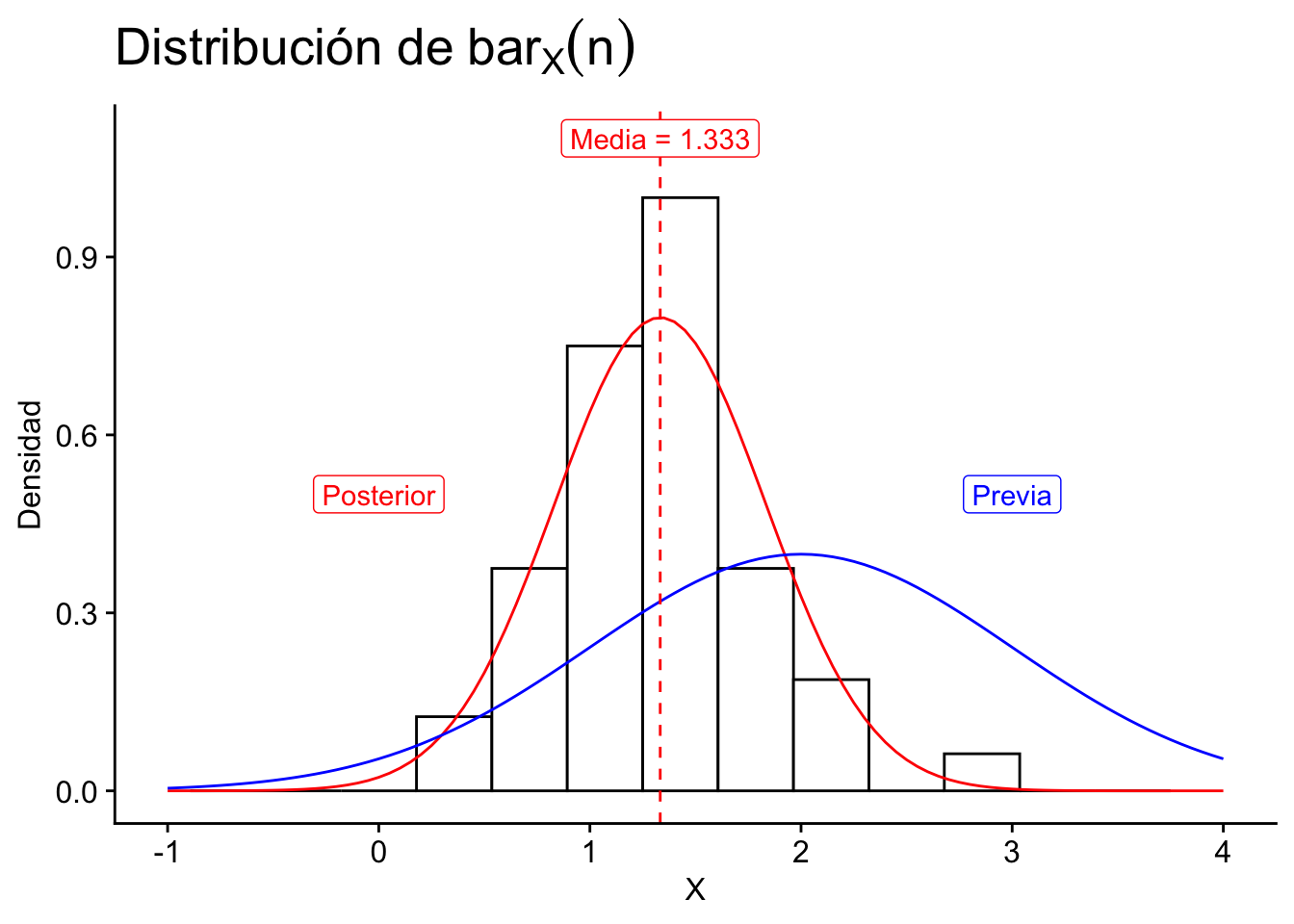
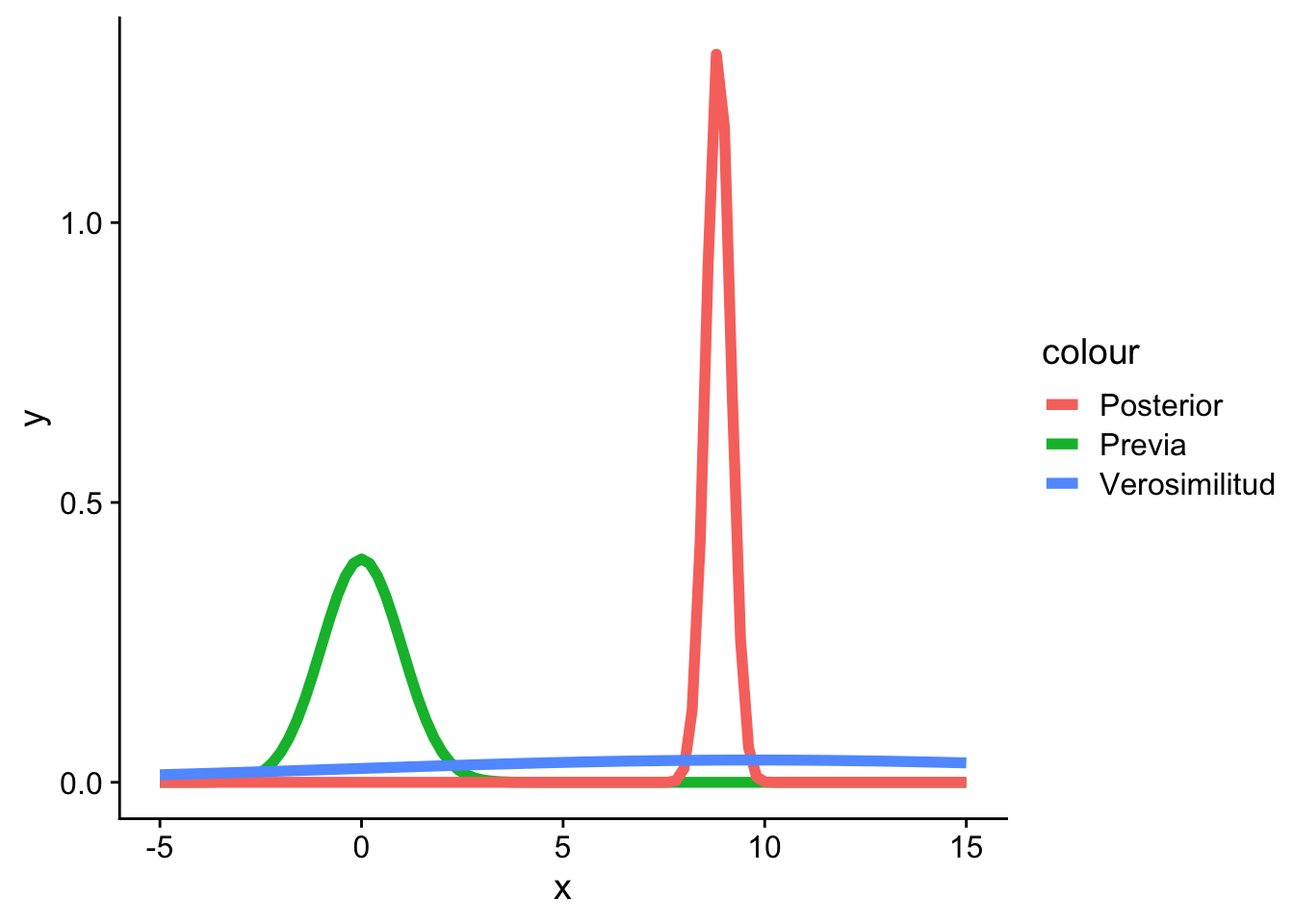
Ejemplo 4.10 Consideremos el conjutno de datos que vienen de una distribución normal \(N(\theta, \sigma^2)\) con varianza conocida \(\sigma^2=0.25\). Si asumimos que la media poblacional \(\theta\) tiene una distribución previa \(N(\mu_{0}, V_{0}^2)\) con \(\mu_0=2\) y \(V_0^2=1\). Se nos pide usar actualizar nuestr previa con los siguientes datos:
Código
x <-c(1.28,0.72,1.17,1.31,1.16,1.45,1.08,1.22,0.60,1.32,1.32,1.47,1.24,1.44,0.71,0.51,0.49,1.49,1.38,1.33,1.20,0.86,0.78,0.57,0.95,1.79,2.20,2.27,1.78,1.87,1.83,2.94,1.26,1.16,1.73,1.45,1.31,1.51,1.80,1.47,1.15,1.06,0.97,2.01,1.12,1.39)ggplot(data.frame(x = x), aes(x = x)) +geom_histogram(fill ="white", color ="black", bins =15) +xlab("x") +ylab("frecuencia") + cowplot::theme_cowplot()
Figura 4.8
Entonces \(\bar{X}_n = 1.329\) y tenemos que \(n = 46\)
Comparando la previa, la verosimilitud y la posterior, tenemos que:
Figura 4.9
Ejemplo 4.11 (Determinación de n) Sean \(X_1,\dots, X_n \sim N(\theta,1)\) y \(\theta\sim N(\mu_0,4)\). Sabemos que \[
V_1^2 = \dfrac{\sigma^2V_0^2}{\sigma^2 + nV_0^2}.
\] Buscamos que \(V_1\leq 0.01\), entonces \[
\dfrac{4}{4n+1}\leq 0.01 \implies n\geq 99.75 \text{ (al menos 100 observaciones)}
\]
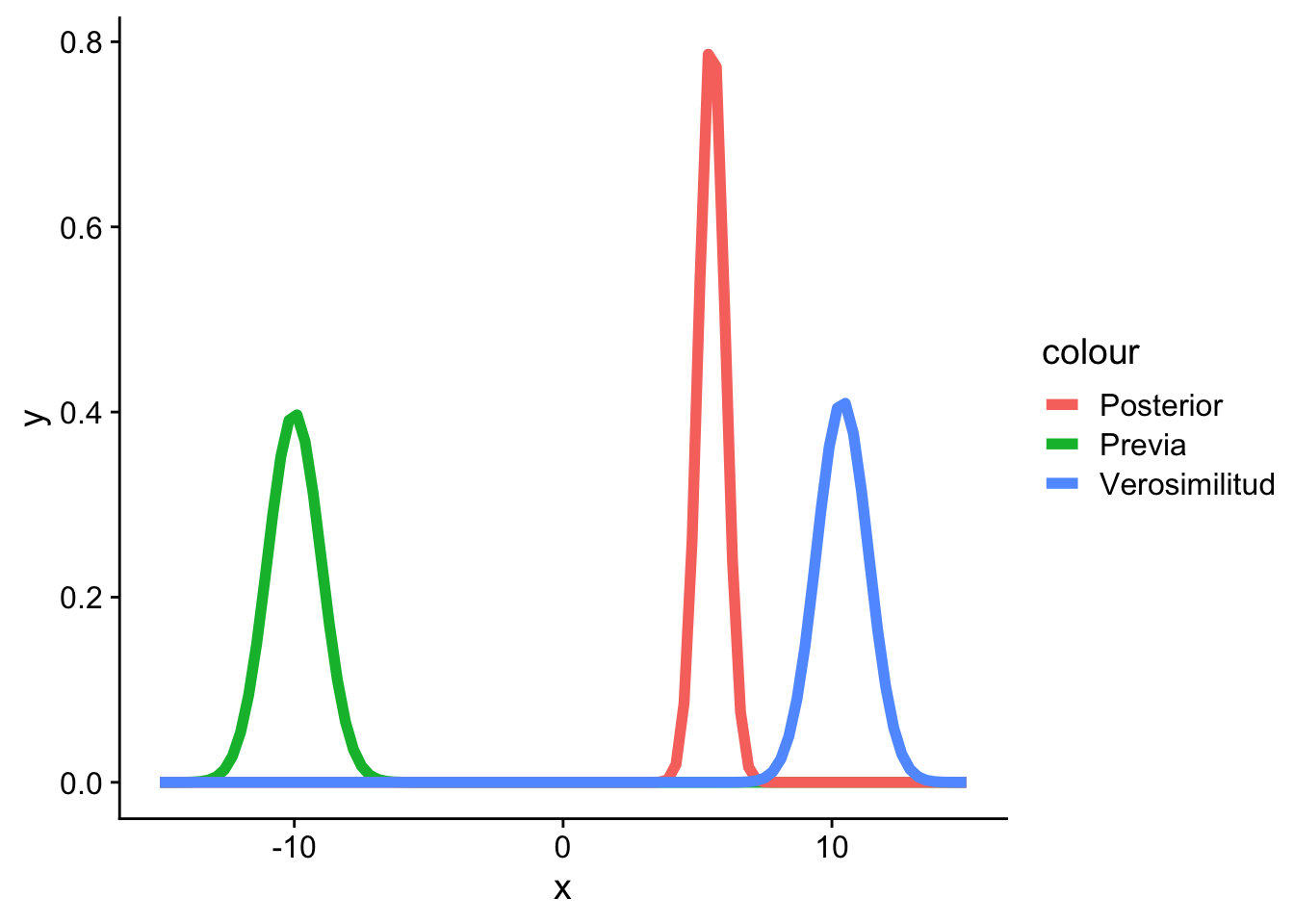
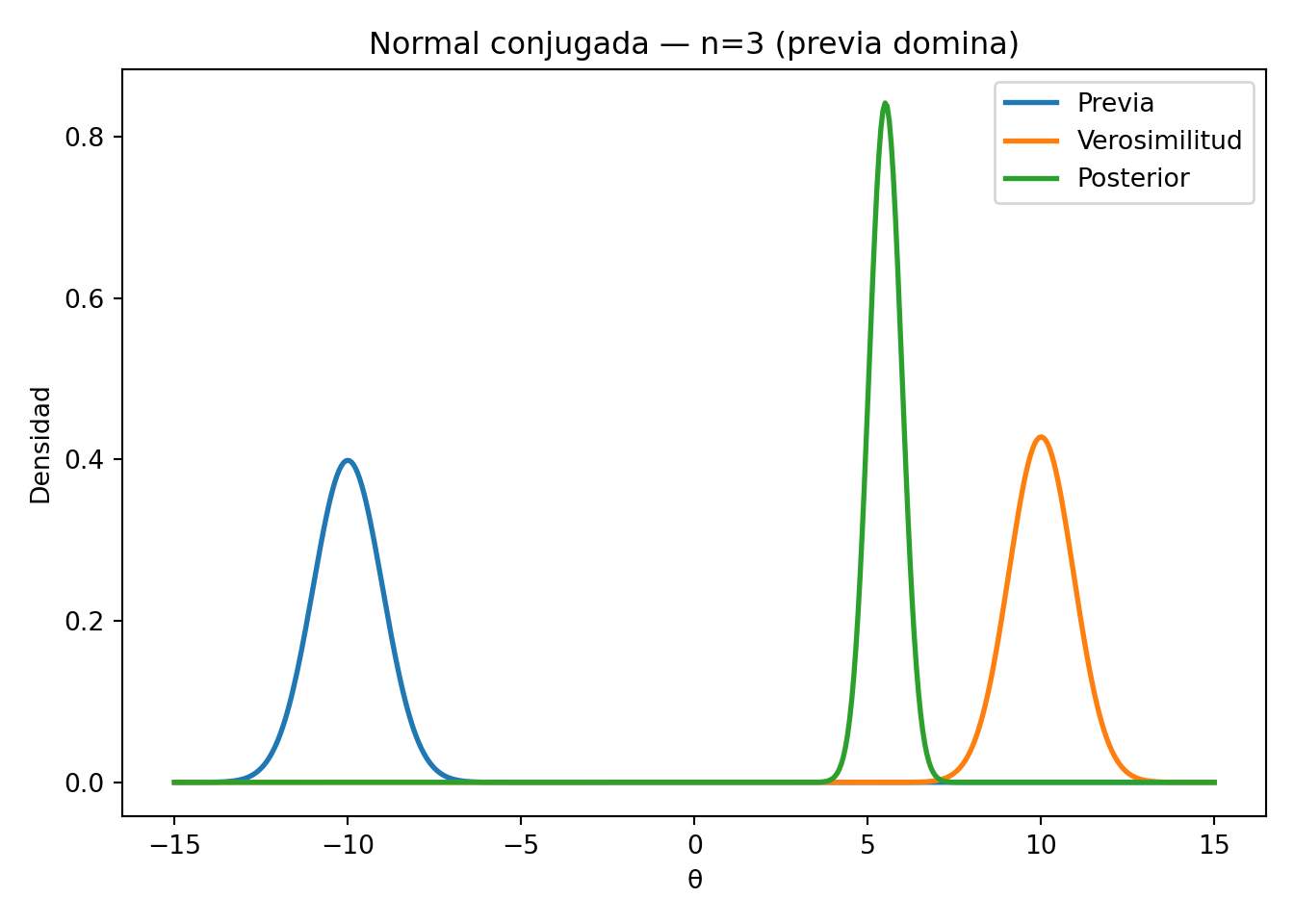
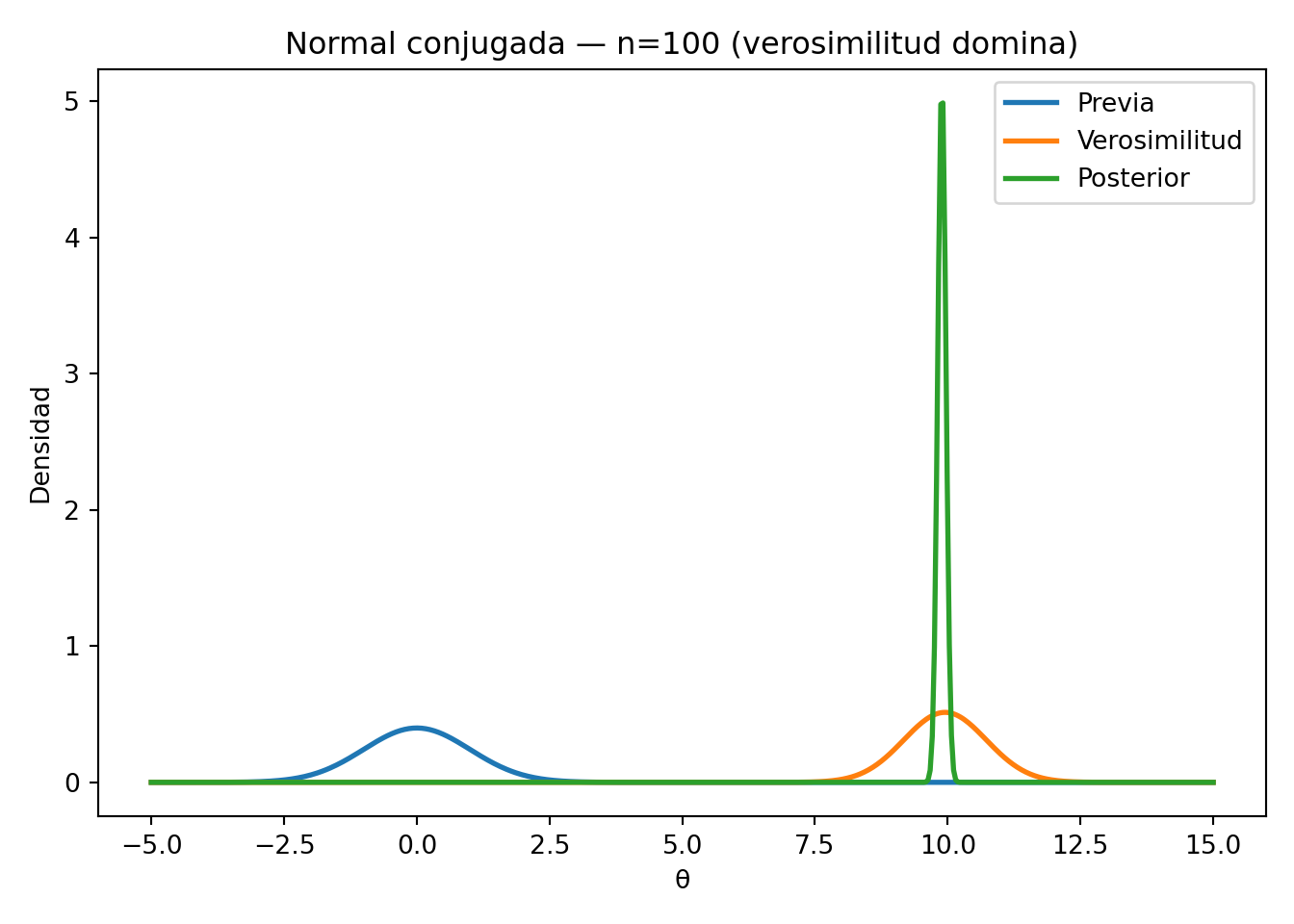
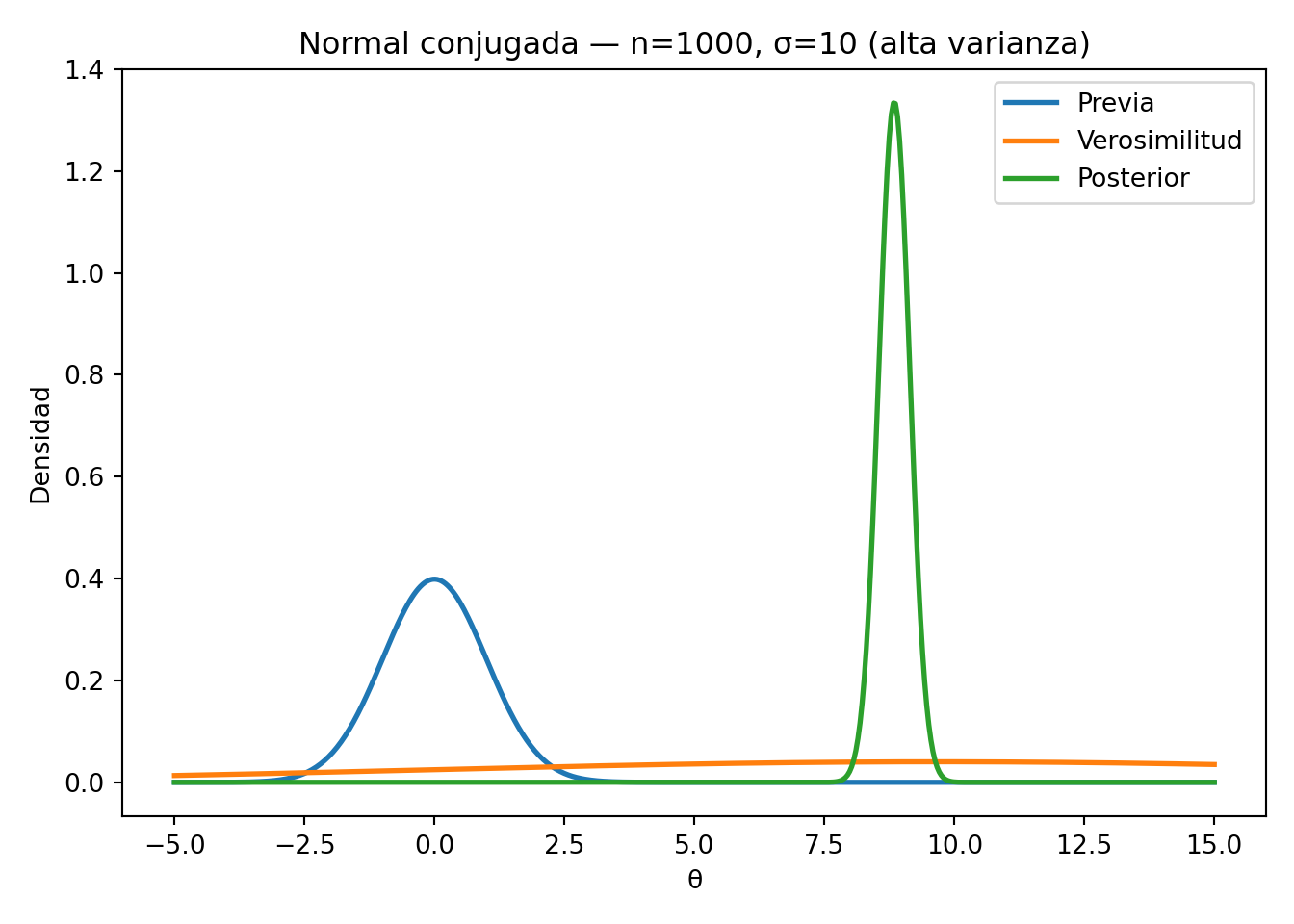
4.4.1 Ejemplo computacional: familia conjugada Normal
Los siguientes ejemplos ilustran cómo el tamaño de la muestra y la varianza de los datos determinan si la posterior se acerca más a la previa o a la verosimilitud.
Definición 4.2 Sea \(\pi\) una función positiva cuyo dominio está en \(\Omega\). Si la ingtegral de \(\pi(\theta)\) sobre \(\Omega\) es infinity, i.e. \(\int\pi(\theta)\;d\theta=\infty\); entonces decimos que \(\pi\) es una densidad impropia. Por ejemplo \(\theta \sim \text{Unif}(\mathbb{R})\), \(\lambda \sim \text{Unif}(0,\infty)\).
Observación. Una técnica para seleccionar distribuciones impropia es sustituir los hiperparámetros previos por 0.
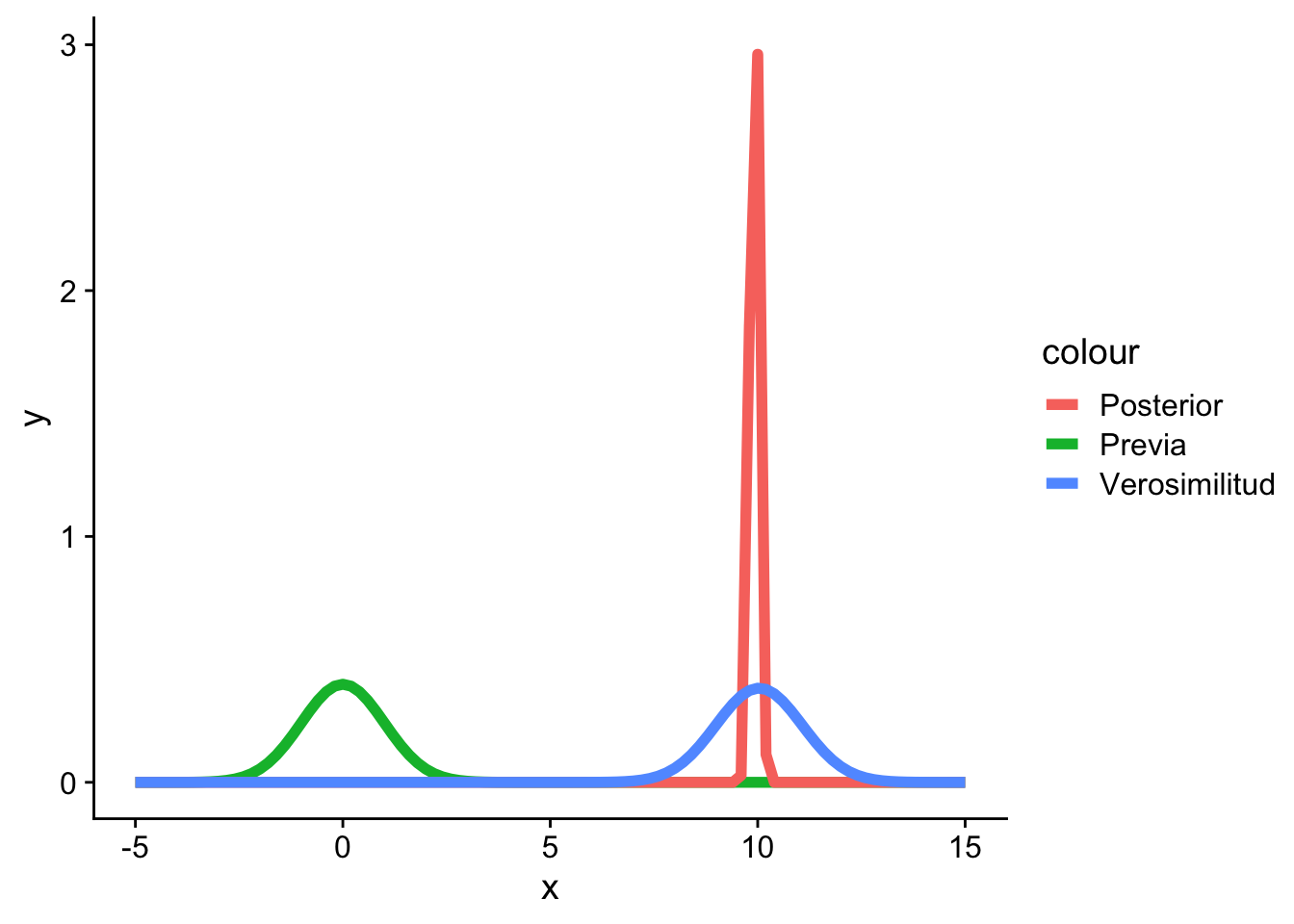
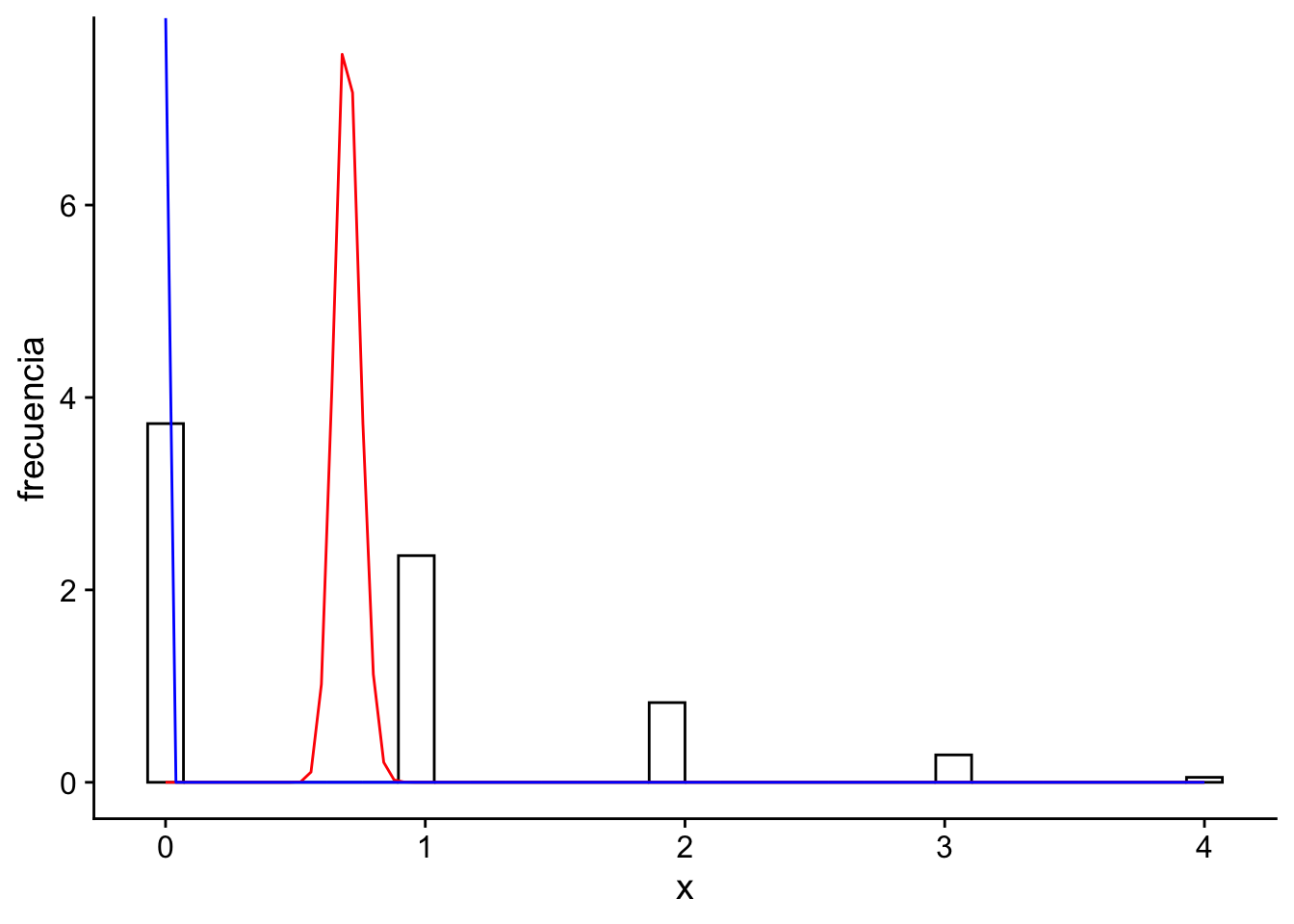
Ejemplo 4.12 La siguiente tabla muestra el número de soldados prusianos muertos por una patada de caballo en 14 unidades de combate por 20 años, para contar 280 unidades. La siguiente tabla resume, cuántas de esas unidades tuvieron este tipo de muertes:
Unidades
Ocurrencias
144
0
91
1
32
2
11
3
2
4
Verosimilitud: Podemos modelar el número de muertes como una distribución Poisson: \(X_1 = 0, X_2 = 1, X_3 = 1,\dots, X_{280} = 0 \sim \text{Poisson}(\lambda)\).
Previa: Para hacer que la posterior conjugue, entonces \(\lambda \sim \Gamma(\alpha, \beta)\).
Posterior: De acuerdo a lo que hemos visto anteriormente \(\lambda|X \sim \Gamma(y+\alpha, n+\beta) = \Gamma(196 + \alpha, 280 + \beta)\).
El problema acá es que no sabemos cuál valor de \(\alpha\) o \(\beta\) deberíamso tomar. Una opción es tomar \(\alpha = \beta = 0\), lo cual nos da una distribución impropia. En este caso:
Por teorema de Bayes, \[
\theta|X \sim \Gamma(196,280)
\]
Gráficamente tenemos la versoimilitud, la previa y la posterior:
Figura 4.16
4.6 Funciones de pérdida
Una vez que obtenemos la distribución posterior \(\pi(\theta|X)\), surge la pregunta: ¿cómo resumir toda esa distribución en un único número que sirva como estimación de \(\theta\)? La respuesta depende del contexto del problema: no es lo mismo subestimar que sobreestimar un parámetro. Las funciones de pérdida formalizan este costo asimétrico y nos permiten seleccionar el estimador que minimiza el error esperado según las consecuencias de equivocarse.
Definición 4.3 Sean \(X_1,\dots, X_n\) datos observables cuyo modelo está indexado por \(\theta\in\Omega\). Un estimador de \(\theta\) es cualquier estadístico \(\delta(X_1,\dots, X_n)\).
Definición 4.4
Estimador \(\to \delta(X_1,\dots,X_n)\).
Estimación o estimado: \(\delta(X_1,\dots,X_n)(\omega) = \delta(\overbrace{x_1,\dots,x_n}^{datos})\)
Definición 4.5 Una función de pérdida es una función de dos variables: \[
L(\theta,a), \quad \theta \in\Omega
\] con \(a\) un número real. Es decir, es lo que se pierde cuando el parámetro es \(\theta\) y se quiere estimar con el valor \(a\).
Asuma que \(\theta\) tiene una previa. La pérdida esperada es \[
\mathbb{E}[L(\theta,a)] = \int_{\Omega}L(\theta, a) \pi(\theta)\;d\theta
\] la cual es una función de \(a\), que a su vez es función de \(X_1,\dots,X_n\). Asuma que \(a\) se selecciona el minimizar esta esperanza. A ese estimador \(a = \delta^*(X_1,\dots, X_n)\) se le llama estimador bayesiano, si ponderamos los parámetros con respecto a la posterior.
La mediana es el punto de \(m\) tal que \(F_{\theta\mid X}(m) = \dfrac{1}{2}\).
Observación. Bajo la función de pérdida absoluta, el estimador bayesiano es la mediana posterior.
Ejemplo 4.14 Para el caso Bernoulli. \[
\dfrac{1}{\text{Beta}(\alpha+y, \beta+n-y)}\int_{-\infty}^{X_{0.5}}\theta^{\alpha+y-1} (1-\theta)^{\beta+n-y-1}\;d\theta = \dfrac12
\] Encontrar el valor que \(X_{0.5}\) que resuelve esta ecuación es díficil y se debe hacer usando métodos numéricos.
Por ejemplo, si tuvieramos que la posterior fuera una \(\mathrm{Beta}(22,18)\) entonces podríamos resolverlo en R de la siguiente forma
La función de pérdida 0-1 penaliza cualquier error de estimación de forma uniforme: no importa cuán lejos esté la estimación del verdadero valor, la pérdida es siempre 1 si hay error y 0 si se acierta exactamente. Formalmente, para un parámetro continuo se define mediante un umbral \(\epsilon > 0\):
Para minimizar esta expresión, debemos maximizar\(P(a - \epsilon < \theta < a + \epsilon \mid X)\), es decir, encontrar el valor \(a\) alrededor del cual la densidad posterior concentra la mayor probabilidad en un intervalo de radio \(\epsilon\).
Tomando el límite cuando \(\epsilon \to 0\), la integral se aproxima por continuidad como:
Ejemplo 4.15 (Pérdida 0-1 en el caso Bernoulli) Sea \(X_1, \dots, X_n \sim \text{Ber}(\theta)\) y \(\theta \mid X \sim \text{Beta}(\alpha + y,\, \beta + n - y)\). La moda de una distribución \(\text{Beta}(a, b)\) con \(a > 1\) y \(b > 1\) es:
\[
\text{Moda} = \frac{a - 1}{a + b - 2}.
\]
Por lo tanto, el estimador bayesiano bajo pérdida 0-1 es:
\[
\delta^*(X_1, \dots, X_n) = \frac{\alpha + y - 1}{\alpha + \beta + n - 2}.
\]
Si la previa es uniforme (\(\alpha = \beta = 1\)), entonces:
\[
\delta^* = \frac{y}{n} = \bar{X}_n,
\]
es decir, bajo previa uniforme y pérdida 0-1, el estimador bayesiano coincide con el estimador de máxima verosimilitud.
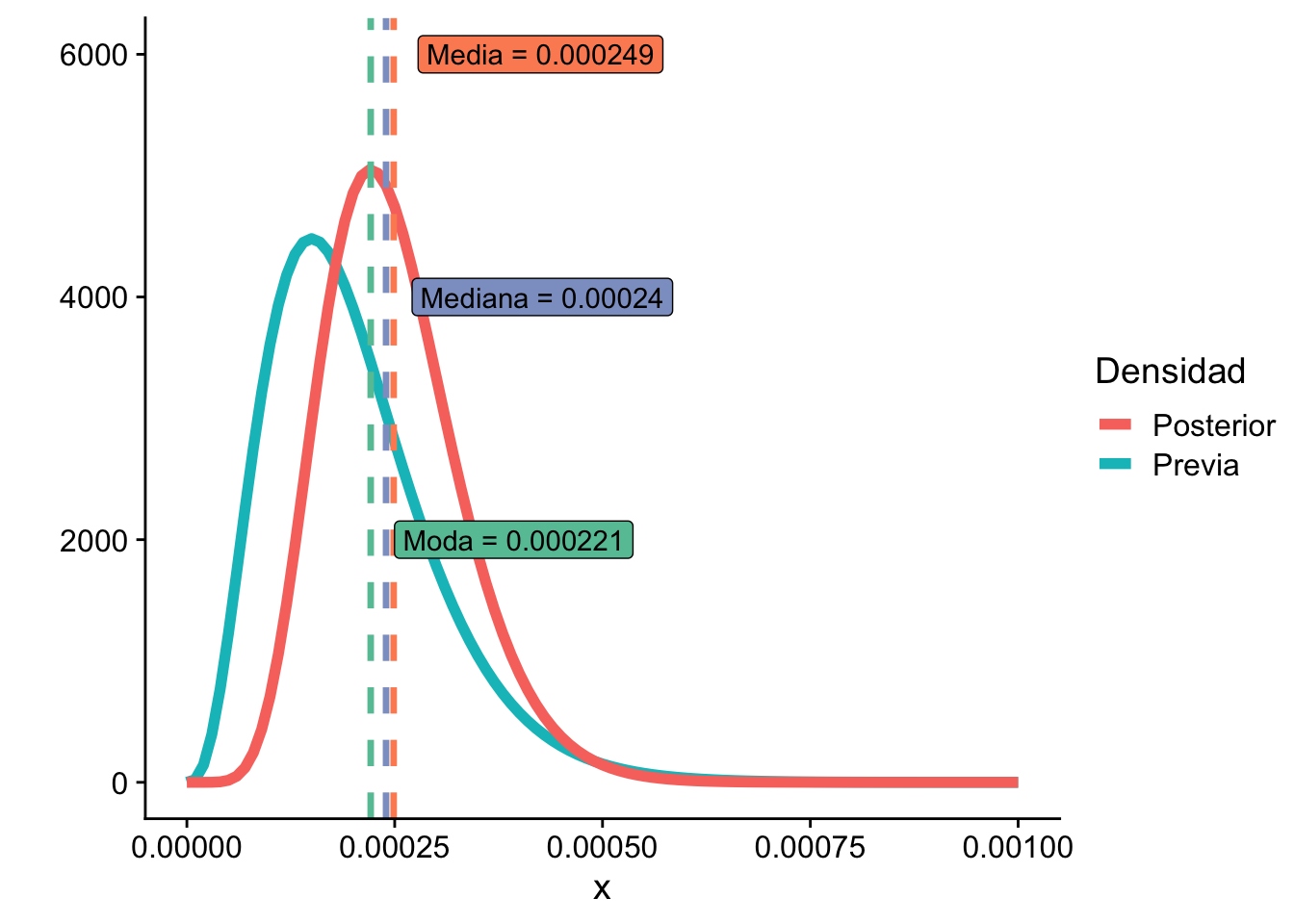
Retomando el ejemplo de los componentes eléctricos, la distribución posterior fue \(\theta|X \sim \Gamma(9, 36178)\). Calculamos los estimadores bajo cada función de pérdida.
Tiempo medio estimado (pérdida absoluta): 100.8 unidades
Código
# Pérdida 0-1: moda posterior (MAP)# La moda de Γ(α, β) es (α - 1) / β para α ≥ 1(theta_moda <- (alpha -1) / beta)
[1] 0.0002211289
Código
cat("Tiempo medio estimado (pérdida 0-1 / MAP):",round(1/ theta_moda, 1),"unidades\n")
Tiempo medio estimado (pérdida 0-1 / MAP): 4522.2 unidades
Observación. Los tres estimadores difieren porque la distribución Gamma no es simétrica. En distribuciones asimétricas siempre se cumple: moda \(\leq\) mediana \(\leq\) media (cuando la cola es hacia la derecha), o la relación inversa cuando la cola es hacia la izquierda. Cuanto más asimétrica sea la posterior, mayor será la discrepancia entre ellos.
Código
from scipy.stats import gamma as gamma_distfrom scipy.optimize import minimize_scalarimport numpy as npalpha_py =9beta_py =36178# Pérdida cuadrática: media posteriortheta_media_py = alpha_py / beta_pyprint(f"Media posterior (pérdida cuadrática): θ = {theta_media_py:.6f} → 1/θ = {1/ theta_media_py:.1f} unidades")
Ejemplo 4.16 Suponga que se tiene un examen con ítemes malos (proporción: \(\theta\)), \(\theta \in [0,1]\). Se decide usar una función de pérdida cuadrática. El tamaño de muestra son \(n=100\) ítemes, de los cuales \(y=10\) están malos.
\[
X_1,\dots,X_n\sim \text{Ber}(\theta)
\]
Usemos diferentes previas para ver su efecto en los estimadores
Primer previa. \(\alpha = \beta = 1\) (Beta). El estimador bayesiano corresponde a
Las previas son muy diferentes una de la otra, pero el estimador final es muy parecido debido a la cantidad de datos. Compare esto con la media empírica \(\bar{X}_n = \dfrac{10}{100} = 0.1\).
4.7.2 Consistencia
Definición 4.6 Un estimador de \(\theta\)\(\delta(X_1,\dots, X_n)\) es consistente si \[
\delta(X_1,\dots, X_n)\xrightarrow[n\to \infty]{\mathbb{P}}\theta.
\]
Bajo pérdida cuadrática, \(\mathbb{E}[\theta|X] = W_1\mathbb{E}[\theta] + W_2\bar{X}_n = \delta^*\). Sabemos, por ley de grandes números, que \(\bar{X}_n \xrightarrow[n\to \infty]{\mathbb{P}}\theta\). Además, \(W_1\xrightarrow[n\to \infty]{}0\) y \(W_2\xrightarrow[n\to \infty]{}1\).
En los ejemplos que hemos analizado \[
\delta^* \xrightarrow[n\to \infty]{\mathbb{P}}\theta
\]
Teorema 4.3 Bajo condiciones mencionadas anteriormente, los estimadores bayesianos son consistentes.
De forma general podemos definir un estimador de la siguiente forma
Definición 4.7 (Estimador) Si \(X_1,\dots, X_n\) es una muestra en un modelo indexado por \(\theta\), \(\theta \in \Omega\) (\(k\)-dimensiones), sea
\[
h:\Omega \to H \subset \mathbb{R}^d.
\]
Defina \(\psi = h(\theta)\). Un estimador de \(\psi\) es una función o estadístico \(\delta(X_1,\dots, X_n) \in H\).
Observación. Ojo, la definición de estimador solo requiere que el parámetro \(\psi\) y el estimador \(\delta\) pertenenzca el mismo espacio. Puede ser que un \(\delta_1\) sea mejor que un \(\delta_2\).
Ejemplo 4.17\(X_1,\dots, X_n \sim \text{Exp}(\theta)\), \(\theta|X \sim \Gamma(\alpha,\beta) = \Gamma (4,8.6)\). La característica de interés es \(\psi = \dfrac{1}\theta\), el valor esperado del tiempo de fallo.
Por otro lado, vea que \(\mathbb{E}(\theta|X) = \dfrac{4}{8.6}\). El estimador plug-in correspondería a \[
\dfrac{1}{\mathbb{E}(\theta|X)} = \dfrac{8.6}{4} = 2.15.
\]
4.8 Caso de estudio: horas de sueño en estudiantes
Suponga que se que quiere averiguar si los estudiantes de cierto colegio duermen más de 8 horas o menos de 8 horas.
Para esto primero cargaremos el siguiente paquete,
Código
library(LearnBayes)
Suponga que se hace una encuesta a 27 estudiantes y se encuentra que 11 dicen que duermen más de 8 horas diarias y el resto no. Nuestro objetivo es encontrar inferencias sobre la proporción \(p\) de estudiantes que duermen al menos 8 horas diarias. El modelo más adecuado es
\[
f(x \vert p) \propto p^s (1-p)^f
\]
donde \(s\) es la cantidad de estudiantes que duermen más de 8 horas y \(f\) los que duermen menos de 8 horas.
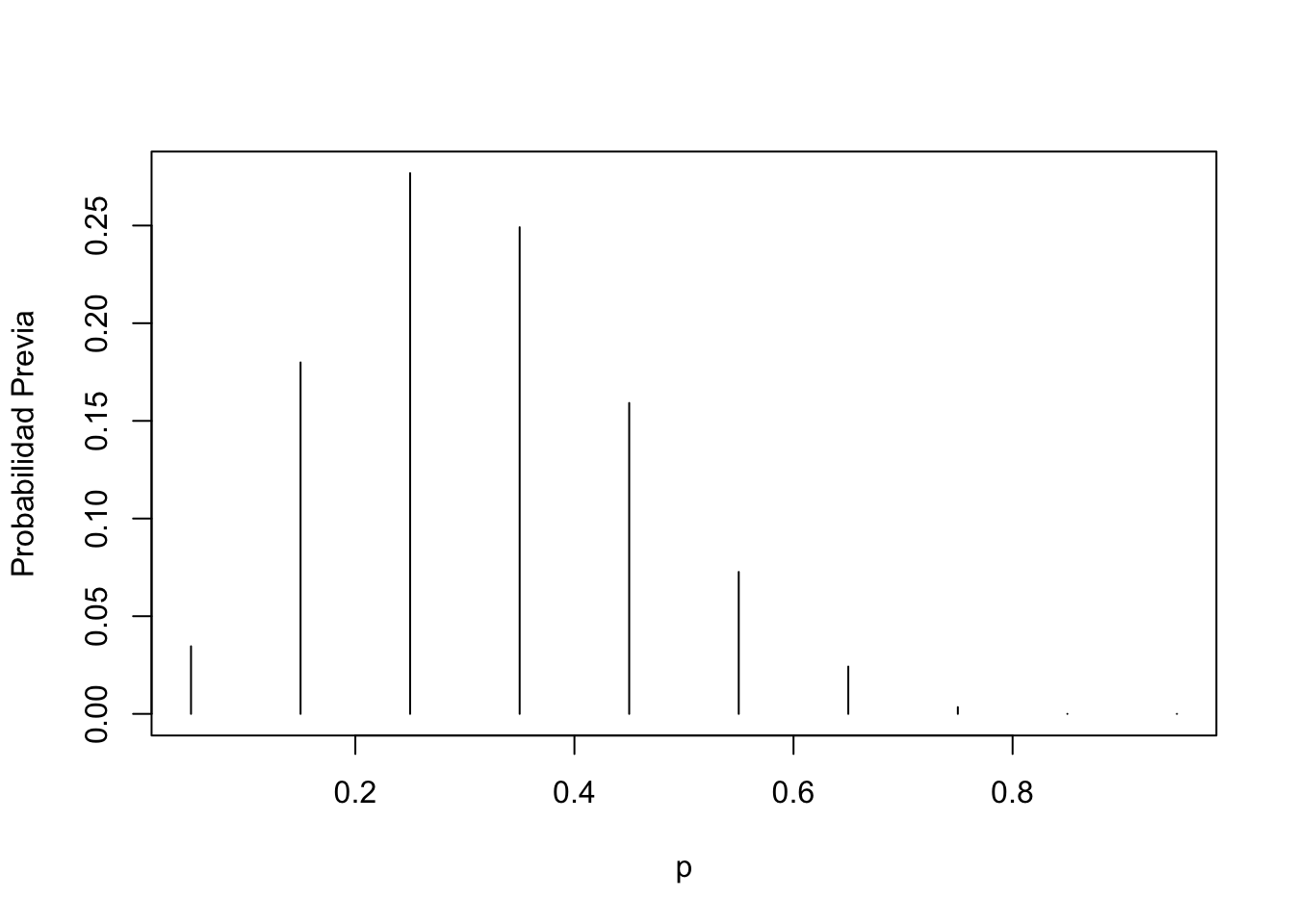
Una primera aproximación para la previa es usar una distribución discreta. En este caso, el investigador asigna una probabilidad a cierta cantidad de horas de sueño, según su experiencia. Así, por ejemplo:
Código
p <-seq(0.05, 0.95, by =0.1)prior <-c(1, 5.2, 8, 7.2, 4.6, 2.1, 0.7, 0.1, 0, 0)prior <- prior /sum(prior)plot(p, prior, type ="h", ylab ="Probabilidad Previa")
Figura 4.18
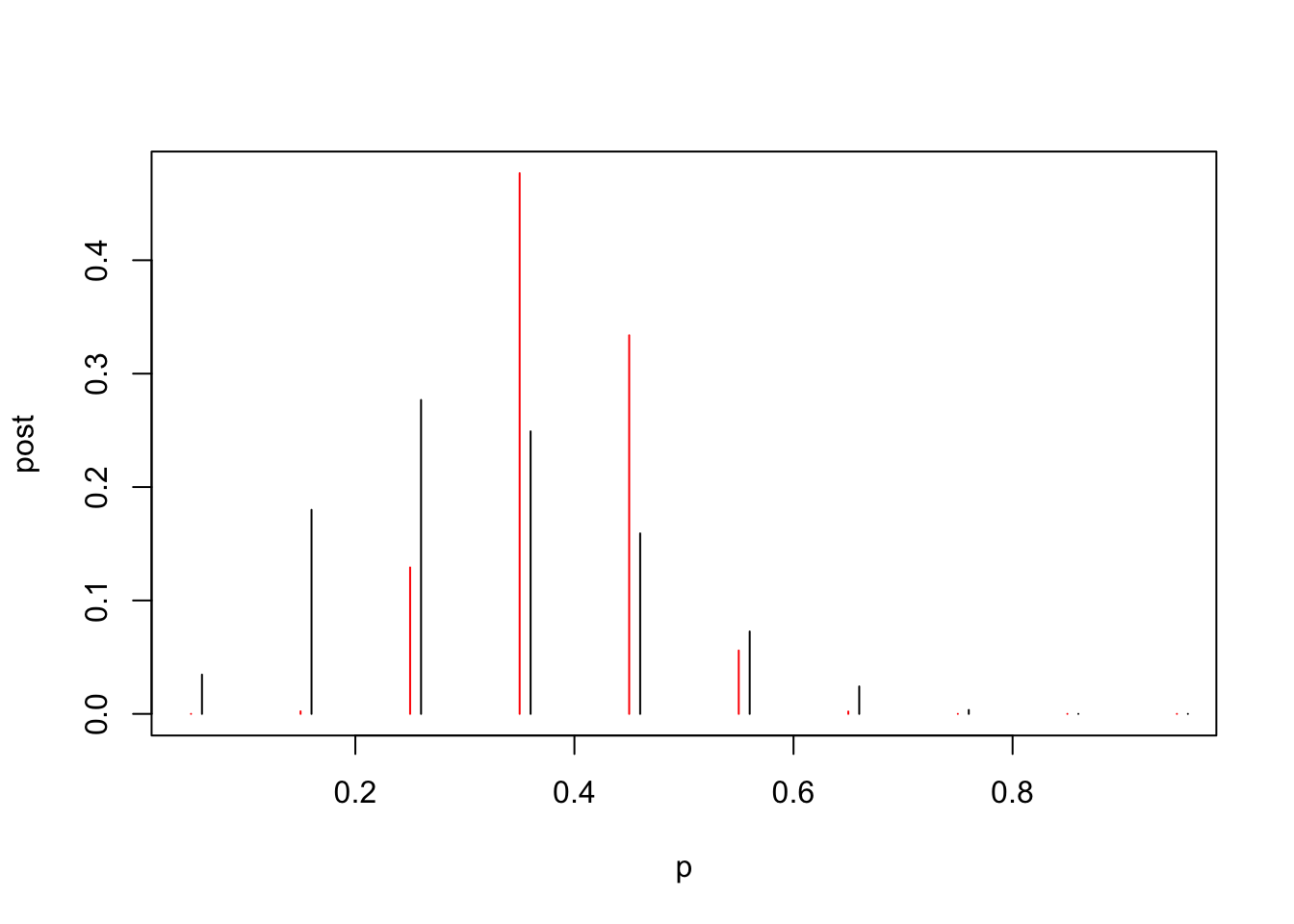
El paquete LearnBayes tiene la función pdisc que estima la distribución posterior para una previa discreta binomial. Recuerde que el valor 11 representa la cantidad de estudiantes con más de 8 horas de sueño y 16 lo que no duermen esa cantidad.
Código
data <-c(11, 16)post <-pdisc(p, prior, data)round(cbind(p, prior, post), 2)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.500 6.500 7.500 7.385 8.500 12.500
Código
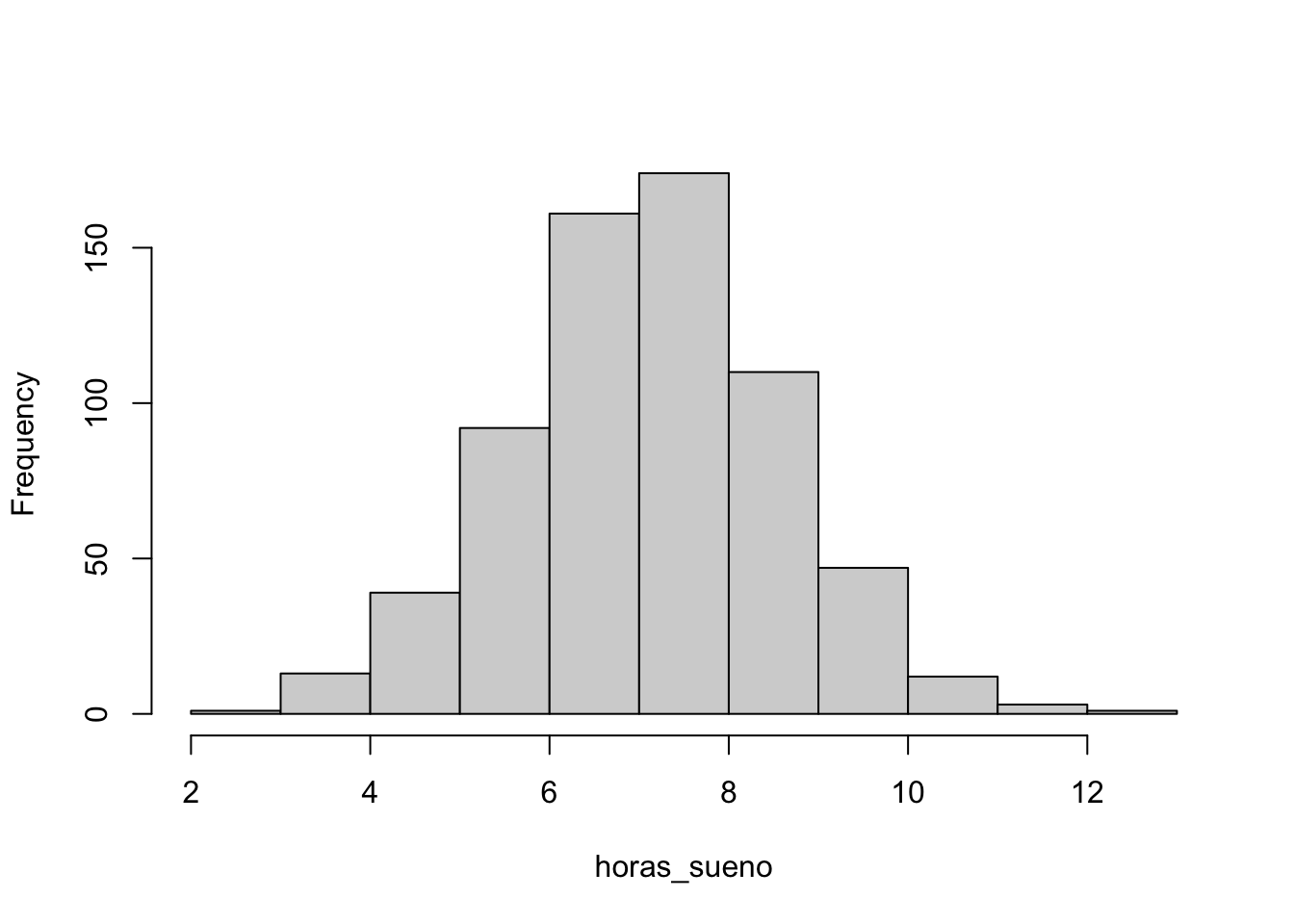
hist(horas_sueno, main ="")
Figura 4.20
Ahora supongamos que se tiene quiere ajustar una previa continua a este modelo. Para esto usaremos una distribución Beta con parámetros \(\alpha\) y \(\beta\), de la forma
El ajuste de los parámetro de la Beta depende mucho de la información previa que se tenga del modelo. Una forma fácil de estimarlo es a través de cuantiles con los cuales se puede reescribir estos parámetros. Para una explicación detallada revisar https://stats.stackexchange.com/a/237849
En particular, suponga que se cree que el \(50\%\) de las observaciones la proporción será menor que 0.3 y que el \(90\%\) será menor que 0.5.
Para esto ajustaremos los siguientes parámetros
Código
quantile2 <-list(p = .9, x = .5)quantile1 <-list(p = .5, x = .3)(ab <-beta.select(quantile1, quantile2))
[1] 3.26 7.19
Código
a <- ab[1]b <- ab[2]s <-11f <-16
En este caso se obtendra la distribución posterior Beta con paramétros \(\alpha + s\) y \(\beta + f\),
Código
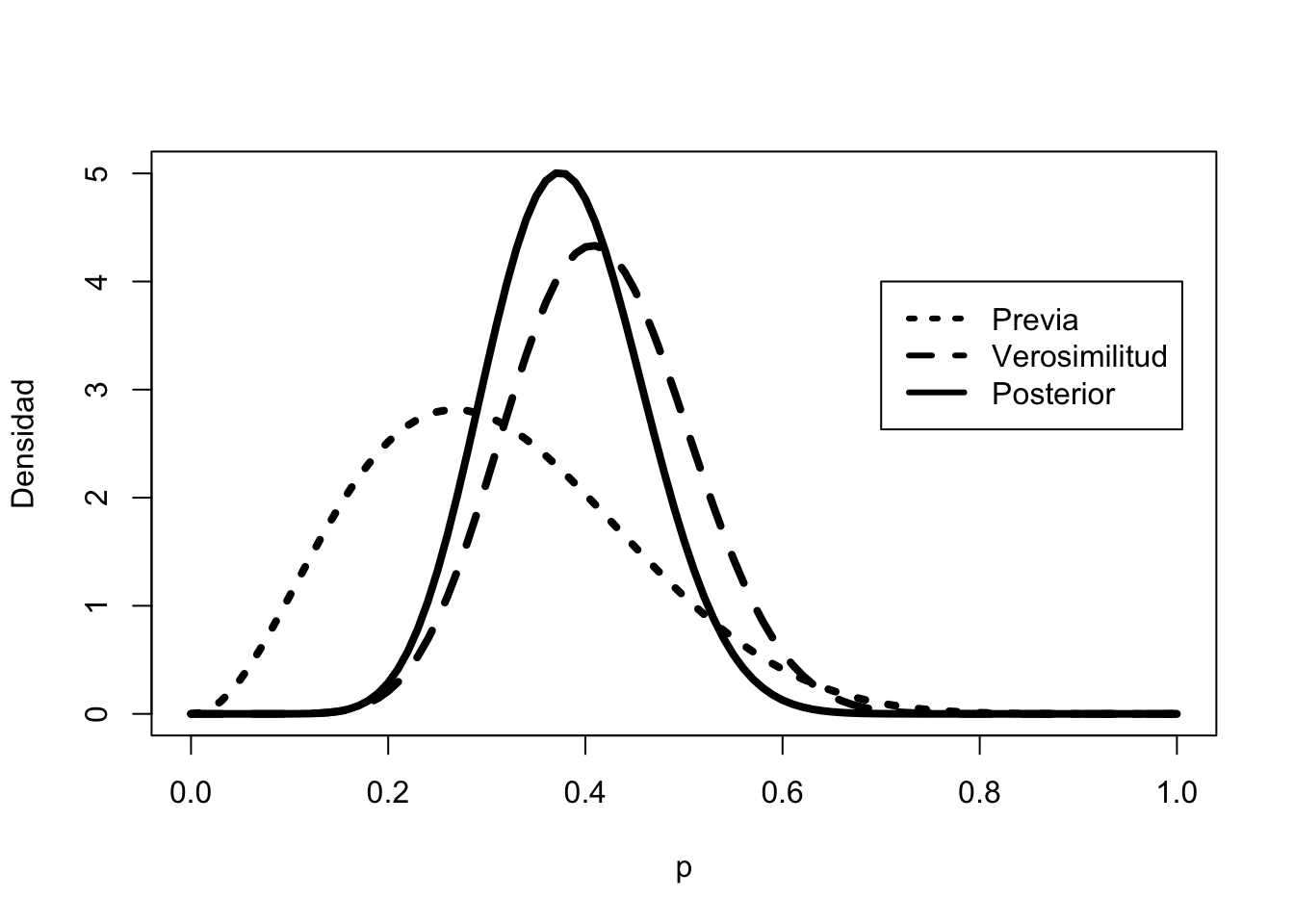
curve(dbeta(x, a + s, b + f),from =0,to =1,xlab ="p",ylab ="Densidad",lty =1,lwd =4)curve(dbeta(x, s +1, f +1), add =TRUE, lty =2, lwd =4)curve(dbeta(x, a, b), add =TRUE, lty =3, lwd =4)legend( .7,4,c("Previa", "Verosimilitud", "Posterior"),lty =c(3, 2, 1),lwd =c(3, 3, 3))
Figura 4.21
Código
(p_hat <-11/27)
[1] 0.4074074
Código
(p_posterior <- (a + s) / (a + s + b + f))
[1] 0.3807744
4.9 Resumen del capítulo
En este capítulo se estudió el enfoque bayesiano para la estimación de parámetros. Los conceptos centrales son: