Código
library(tidyverse)La primera habilidad que debes desarrollar es la de explorar los datos. El objetivo de este capítulo es presentar el flujo de trabajo de un científico de datos y las herramientas que se utilizan.
Al finalizar este capítulo, podré:
El primer paso es buscar los datos de acuerdo con el problema que se quiere resolver. En este paso, se busca entender la estructura de los datos, la cantidad de datos, la calidad de los datos, etc.
En esta parte es fundamental preguntarse “¿Cuál es el objetivo que quiero alcanzar con estos datos?”. Por eso, antes de buscar los datos, es importante clarificar el objetivo del proyecto.
Podemos identificar algunos pasos para clarificar este objetivo:
Las instrucciones detalladas de cada uno de estos pasos se darán en la Bitácora 1. Por ahora, nos enfocaremos en la búsqueda de datos. Para esto se pueden utilizar los siguientes recursos:
El tipo de datos que se pueden encontrar en estos sitios son:
Pueden ser útil para responder preguntas concretas. Se tiene que tener mucho cuidado con el sesgo en las preguntas. Por ejemplo: Encuestar personas de solo un cantón para responder preguntas nacionales o encuestar personas con ciertas características particulares (e.g., encuestas telefónicas). Otra fuente de sesgo son las preguntas tendenciosas, e.g., ¿Está usted de acuerdo que X marca de helado tenga tan mal sabor?
La idea es recolectar y medir información que responda a ciertas preguntas especificas. En estos casos se tiene que tener cuidado con el sesgo que se pueda introducir a los experimentos, especialmente en pruebas clínicas.
Una prueba doblemente ciega se realiza dando la droga correcta a un grupo de pacientes y un placebo (una pastilla de azúcar) a otro grupo. Ni los doctores, ni los pacientes saben que tipo de pastilla se le recetó.
Son los generados por algún proceso natural o humano. Por ejemplo: La temperatura de San José en los últimos 10 años, el precio de una acción, composición química de parcelas de suelos, etc.
El flujo de trabajo estándar para comenzar un proyecto de ciencia de datos es el siguiente:
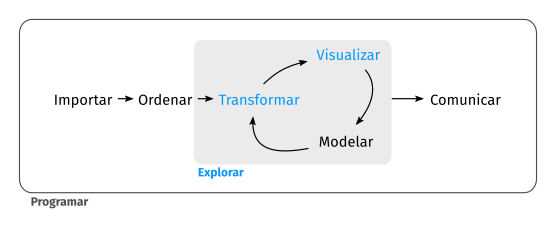
En R el paquete tidyverse es el más utilizado para el análisis de datos. Este paquete contiene una serie de paquetes que son útiles para el análisis de datos.
library(tidyverse)Para la mayoría de las aplicaciones se pueden usar los paquetes readr y readxl. Esto tienen las funciones las funciones read_csv() y read_excel() para importar datos en formato csv y excel, respectivamente. Si los datos se encuentran en formatos como SAS, SPSS o Stata, entonces el paquete haven es el más adecuado.
Por favor revisen la documentación de estos paquetes para ver las opciones que tienen estas funciones.
Una tabla de datos es una forma de organizar la información. Se tienen \(n\) individuos u observaciones que denotaremos \(I_1, I_2, \ldots, I_n\). Cada una de estas observaciones tiene una \(p\)-tupla de variables o características asociadas que llamaremos \((X_1,X_2,\ldots, X_p)\). Llamaremos \(x_{ij}\) al dato que corresponde al individuo \(i\) con la característica \(j\).
\[ \begin{array}{c|cccc} & C_1 & C_2 & \cdots & C_p \\ \hline I_1 & x_{11} & x_{12} & \cdots & x_{1p} \\ I_2 & x_{21} & x_{22} & \cdots & x_{2p} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ I_n & x_{n1} & x_{n2} & \cdots & x_{np} \\ \end{array} \]
Constantes: Indican algún parámetro de control, por ejemplo, valores de calibración en la maquina usada para la medición.
Binarias: Indican la presencias o ausencia de alguna característica. Usualmente se codifican usando Falso o Verdadero.
Discretas: Pueden tomar solamente un conjunto determinado de valores (textual o numérico). Por ejemplo, la variable color; negro, blanco, azul, etc, o la variable calificación; 1, 2, 3, 4, o 5.
Continuas: Pueden tomar cualquier valor en la recta real como la Temperatura.
Los datos pueden venir en diferentes formatos. Nuestro objetivo es llevar los datos a este formato ordenado (tidy data), que es el más adecuado para el análisis. Este formato es el más adecuado para el análisis de datos.
En general, existen tres reglas interrelacionadas que hacen que un conjunto de datos sea ordenado:

Muchas veces el conjunto de datos no viene en este formato. Para esto, lo mejor es usar las funciones del paquete tidyr: pivot_longer() y pivot_wider().
Presentaremos algunos elementos que se deben considerar cuando se está ordenando un conjunto de datos.
Se debe revisar el tipo de variable que queremos usar para el análisis. Las escalas de medida son:
Nominales: Son variables discretas que no tienen orden. Sabor de helado: Vainilla, Chocolate, Fresa, etc.
Ordinales: Variables discretas con cierto orden. Calificación de un hotel: Malo, Regular, Bueno, Muy Bueno. No se puede determinar la magnitud de la diferencia entre cada variable.
Intervalos: Son variables donde la diferencia entre las variables tiene sentido. Por ejemplo: si tomamos tres temperaturas en grados centígrados, \(5 \,^\circ\mathrm{C}\), \(10 \,^\circ\mathrm{C}\), \(15 \,^\circ\mathrm{C}\), la diferencia entre cada uno de los valores siempre es la misma. Esta tipo de escala se dice que no tiene un cero natural ya que \(0 \,^\circ\mathrm{C}\) no implica la ausencia absoluta de temperatura. Asimismo, \(10 \,^\circ\mathrm{C}\) no es siempre el doble de caliente que \(5 \,^\circ\mathrm{C}\). Se dice también que es una escala de suma y resta.
Racionales: Las diferencias entre dos valores son cuantificables y además esta escala posee un cero natural. Por ejemplo el dinero de una cuenta bancaria, ya que $5 se puede duplicar o triplicar preservando el sentido de la escala (a $10 o $15 respectivamente). Otro ejemplo es la temperatura en grados Kelvin, ya que multiplicar por dos un valor, si representa que la temperatura aumenta el doble. Este tipo de escala también se conoce como de multiplicación y división.
Cualquier base de datos puede contener inconsistencias que son necesarias de corregir. Recuerden: Datos basura implican resultados basura.
Nominales u ordinales: Usualmente se deben revisar que los valores sean consistentes en cada una de las variables. Por ejemplo la variable Universidad actual puede contener valores como:
UCR
Universidad de Costa Rica
U.C.R.
Universidad de C.R.
Todos esos valores se refieren al mismo objeto y deberían fusionarse a un valor Universidad de Costa Rica o UCR.
Intervalo o racionales: Este tipo de datos son más complicados de depurar ya que es permitido el uso de valores en la recta real. Se deben de considerar aspectos como:
Puntos extremos: Llamados en inglés outliers, son puntos que se salen de completamente de la “normalidad” de nuestros datos. Estos pueden ser provocados por errores de medición en el cual se usó un conjunto distinto de parámetros. También puede ser una observación real. Más adelante veremos algunas herramientas que nos ayudarán a determinar si un punto extremo es genuino o no.
Elementos no numéricos: Por ejemplo si se incluye a una categoría numérica el valor 50 o más o Fuera del rango.
Diferentes escalas: Es muy común equivocarse al comparar variables en diferentes escalas. Por ejemplo, si se tiene el precio de cierto producto recolectado durante años, este debería de ser primero deflatado a colones de hoy para poder comparar la evolución a través del periodo.
Todos estos problemas deberían de ser analizados caso por caso y tomando siempre en cuenta la opinión de un experto para decidir si la variable se interpola, se agregan nuevos valores o simplemente se elimina.
A veces, para hacer más interpretable nuestros resultados, es necesario transformar nuestros datos de base en otros que se ajusten más a cierta técnica en específico.
Estandarización: En general hay 3 tipos de estandarización:
Re-escalamiento: Es cambiar el intervalo original de nuestros datos hacia alguno que queramos.
\[\begin{align*} \frac{X^\prime - \min_{\text{nuevo}}}{\max_{\text{nuevo}} - \min_{\text{nuevo}}} & = \frac{X - \min_{\text{orig}}}{ \max_{\text{orig}} - \min_{\text{orig}}} \\ X^\prime & = \frac{X - \min_{\text{orig}}}{ \max_{\text{orig}} - \min_{\text{orig}}} (\textstyle \max\_{\text{nuevo}} - \min\_{\text{nuevo}}) + \min\_{\text{nuevo}} \\ \end{align*}\]
\(z\)-score: A cada variable se le sustrae la media empírica (\(\bar{X}\)) y se divide por la desviación estándar (\(s\)).
\[\begin{equation*} X^\prime = \frac{X - \bar{X} }{s} \end{equation*}\]
donde
\[\begin{equation*} \begin{aligned} \overline{X} &= \frac{1}{n} \sum_{i=1}^n X_i \\ s^2 &= \frac{1}{n-1} \sum_{i=1}^n {(X_i - \overline{X})}^2 \end{aligned} \end{equation*}\]
x <- c(10, 20, 30, 40, 50)
# Restar la media y dividir por la desviación estándar
z <- (x - mean(x)) / sd(x)
z[1] -1.2649111 -0.6324555 0.0000000 0.6324555 1.2649111import numpy as np
x = np.array([10, 20, 30, 40, 50])
# Restar la media y dividir por la desviación estándar (ddof=1 = insesgada)
z = (x - x.mean()) / x.std(ddof=1)
zarray([-1.26491106, -0.63245553, 0. , 0.63245553, 1.26491106])\[ X^\prime = \frac{X}{10^k} \quad k\in \mathbb{Z}. \]
Normalización: Ciertos modelos requieren que los valores sigan una distribución normal (gaussiana). Para normalizar estas variables se pueden aplicar transformaciones de tipo exponencial, logarítmicas o de Box-Cox. Una transformación de Box-Cox es:
\[\begin{align*} X^\prime &= \begin{cases} \frac{X^\lambda - 1}{\lambda} & \text{si } \lambda \neq 0, \\ \log(X) & \text{si } \lambda = 0. \end{cases} \end{align*}\]
Mapeo: Se refiere a convertir una variable nominal u ordinal en una numérica creando variables tontas (dummy) para este fin. Por ejemplo, observe como se convierte la siguiente tabla:
| Individuo | Altura |
|---|---|
| \(I_1\) | Bajo |
| \(I_2\) | Medio |
| \(I_3\) | Bajo |
| \(I_4\) | Alto |
| \(I_5\) | Medio |
a la representación usando variables tontas:
| Individuo | Bajo | Medio | Alto |
|---|---|---|---|
| \(I_1\) | 1 | 0 | 0 |
| \(I_2\) | 0 | 1 | 0 |
| \(I_3\) | 1 | 0 | 0 |
| \(I_4\) | 0 | 0 | 1 |
| \(I_5\) | 0 | 1 | 0 |
Discretización: Esta transformación es útil cuando variables continuas no tienen información por si solas: Por ejemplo en la siguiente tabla se observa como la variable empleado originalmente no representa correctamente si una empresa es grande o no a nivel general.
| Número de empleados |
|---|
| 101 |
| 149 |
| 203 |
| \(\vdots\) |
| 1028 |
| 1037 |
| 1100 |
Sin embargo, si se discretiza la variable podemos ver como la variable empleado originalmente no representa correctamente si una empresa es grande o no a nivel general. Observe que cuando discretizamos la variable, se pueden apreciar distintos segmentos más informativos.
| Número de empleados | Segmento |
|---|---|
| 101 | 100-500 |
| 149 | 100-500 |
| 203 | 100-500 |
| \(\vdots\) | \(\vdots\) |
| 1028 | 1000-1500 |
| 1037 | 1000-1500 |
| 1100 | 1000-1500 |
Ejercicio 2.1 Realice la lectura del capítulo Tidy Data del libro R4DS y realice todos los ejercicios que se presentan.
Ejercicio 2.2 Una herramienta muy útil para depurar y transformar datos es OpenRefine (http://openrefine.org/). Revisen y estudien este programa usando algunas tablas de datos.
El primer ejercicio que deben hacer cuando tengan sus datos limpios es el de visualizarlos. Esto lo que permite es comenzar a generar hipótesis sobre la pregunta de investigación. El capítulo Data Visualization del libro R4DS es un buen punto de partida para comenzar a aprender la gramática de gráficos de ggplot2.
Cómo ejemplo vamos a usar el conjunto de datos penguins del paquete palmerpenguins. Este conjunto de datos contiene información sobre tres especies de pingüinos: Adelie, Chinstrap, y Gentoo. Queremos visualizar la relación entre la masa corporal y la longitud de la aleta de los pingüinos y además se desea ajustar un modelo lineal a estos datos.
library(palmerpenguins)
library(ggthemes)
ggplot(data = penguins, mapping = aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = species)) +
geom_smooth(method = "lm") +
labs(
title = "Masa corporal y longitud de las aletas",
subtitle = "Dimensiones para Pingüinos Adelie, Chinstrap y Gentoo",
x = "Longitud de aleta (mm)",
y = "Masa corporal (g)",
color = "Especie",
shape = "Especie"
) +
scale_color_colorblind() +
cowplot::theme_cowplot()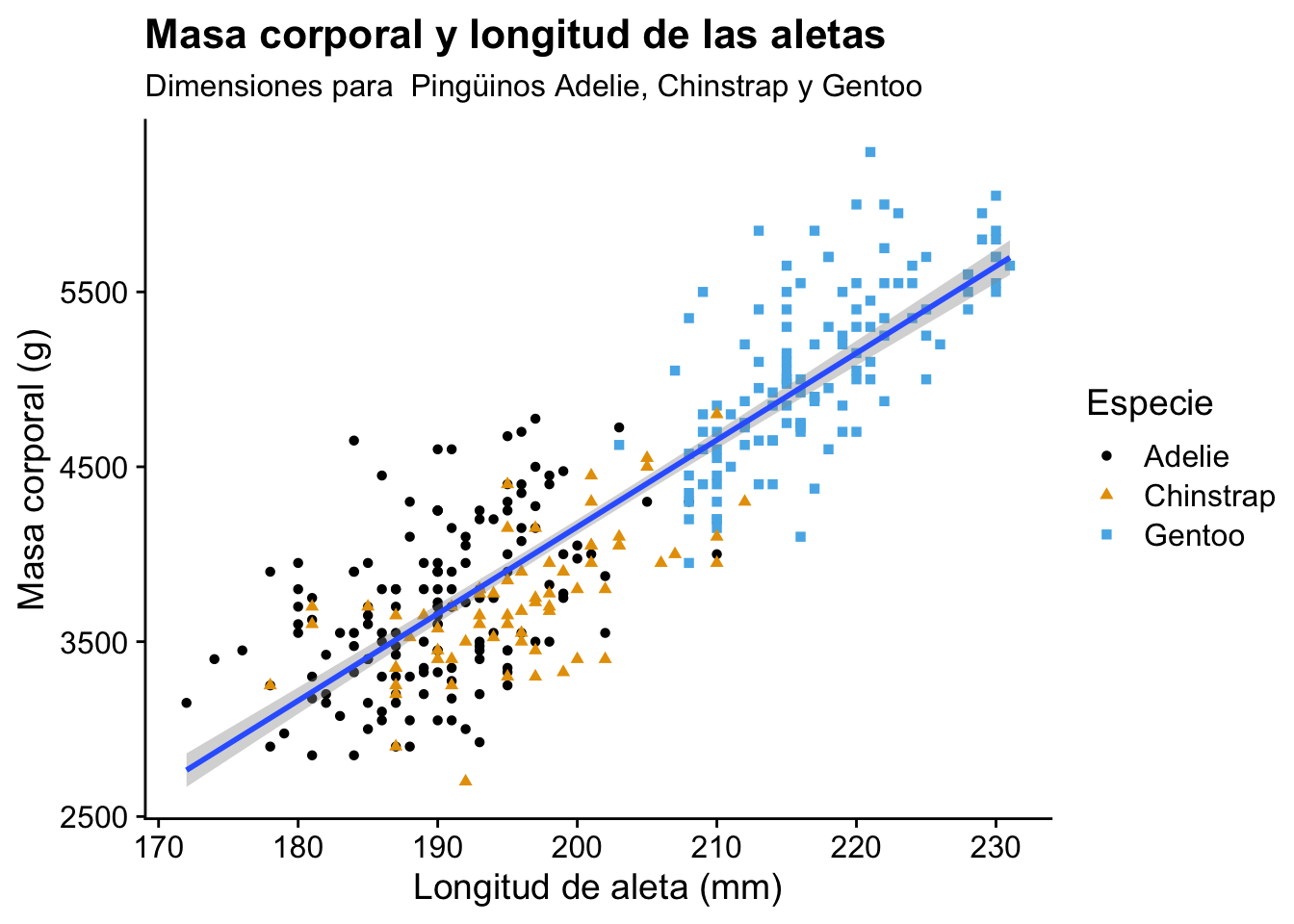
import numpy as np
import matplotlib.pyplot as plt
from palmerpenguins import load_penguins
import scipy.stats as stats
penguins = load_penguins().dropna(subset=["flipper_length_mm", "body_mass_g"])
especies = penguins["species"].unique()
colores = {"Adelie": "blue", "Chinstrap": "orange", "Gentoo": "green"}
marcadores = {"Adelie": "o", "Chinstrap": "s", "Gentoo": "^"}
fig, ax = plt.subplots(figsize=(8, 5))
for especie in especies:
datos_especie = penguins[penguins["species"] == especie]
ax.scatter(
datos_especie["flipper_length_mm"],
datos_especie["body_mass_g"],
label=especie,
color=colores[especie],
marker=marcadores[especie],
alpha=0.7,
)
x = penguins["flipper_length_mm"].values
y = penguins["body_mass_g"].values
slope, intercept, *_ = stats.linregress(x, y)
x_range = np.linspace(x.min(), x.max(), 100)
ax.plot(x_range, intercept + slope * x_range, color="gray", linewidth=2)[<matplotlib.lines.Line2D object at 0x1487a5880>]ax.set_xlabel("Longitud de aleta (mm)")Text(0.5, 0, 'Longitud de aleta (mm)')ax.set_ylabel("Masa corporal (g)")Text(0, 0.5, 'Masa corporal (g)')ax.set_title("Masa corporal y longitud de las aletas")Text(0.5, 1.0, 'Masa corporal y longitud de las aletas')ax.legend(title="Especie")<matplotlib.legend.Legend object at 0x1487a5a90>plt.tight_layout()
plt.show()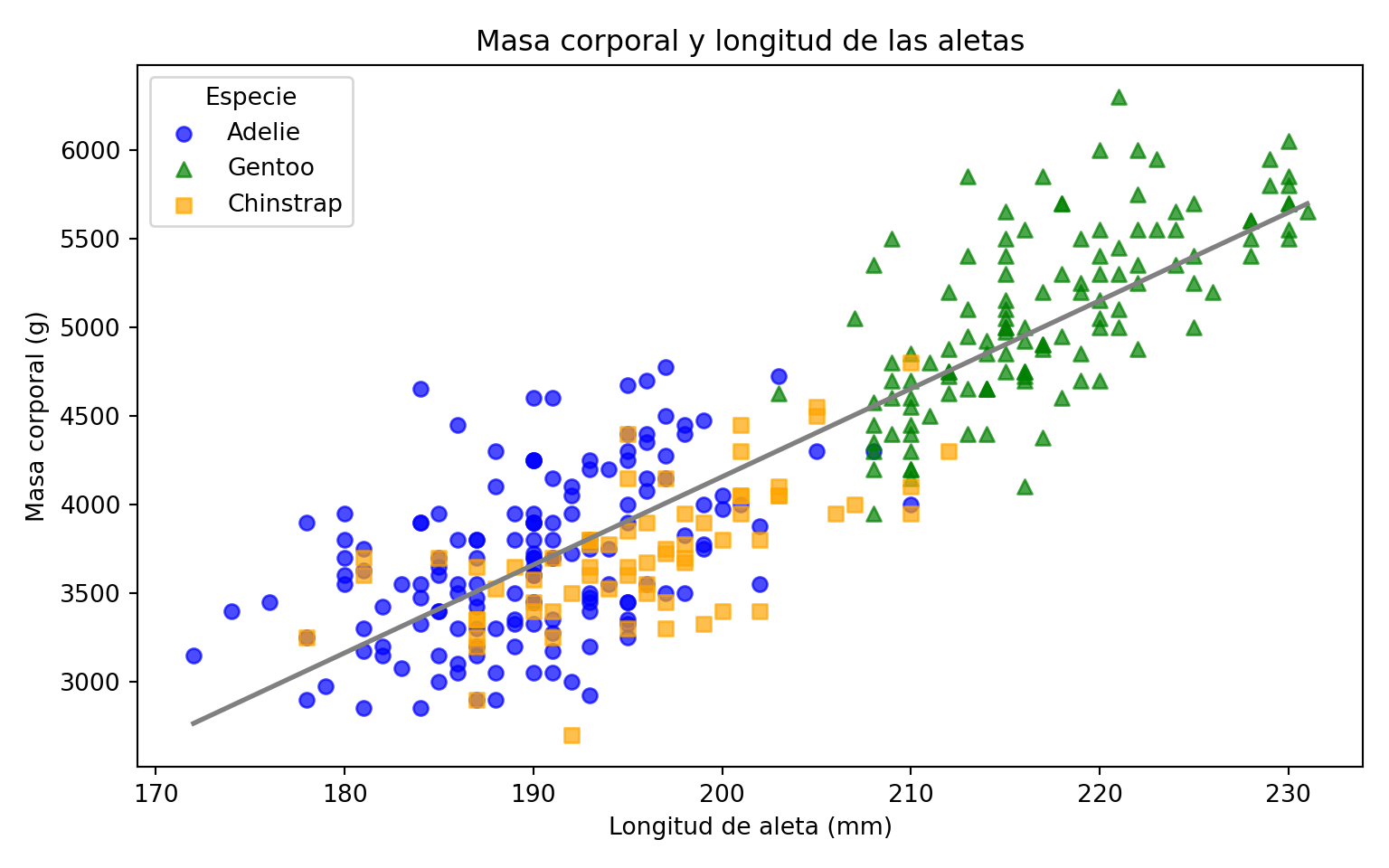
En esta etapa se pueden crear nuevas variables a partir de las variables existentes. Por ejemplo, se pueden crear variables categóricas a partir de variables numéricas.
Las funciones más comunes acá serían mutate(), select(), filter(), group_by(), summarize() y reframe() del paquete dplyr.
No existen reglas estrictas para construir estas nuevas variables. Estas deben ser construidas de acuerdo con el problema que se quiere resolver.
Algunas recomandaciones para estas construcciones son:
clean_names() del paquete janitor.filter() se pueden usar condiciones lógicas como ==, !=, >, <, >=, <=, %in%, !%in%, is.na(), is.null(), is.nan(), is.finite(), is.infinite().strings: Funciones como str_sub() y str_detect() del paquete stringr son útiles para el manejo de strings.fruit contiene nombre de varias frutas.str_view(fruit) [1] │ apple
[2] │ apricot
[3] │ avocado
[4] │ banana
[5] │ bell pepper
[6] │ bilberry
[7] │ blackberry
[8] │ blackcurrant
[9] │ blood orange
[10] │ blueberry
[11] │ boysenberry
[12] │ breadfruit
[13] │ canary melon
[14] │ cantaloupe
[15] │ cherimoya
[16] │ cherry
[17] │ chili pepper
[18] │ clementine
[19] │ cloudberry
[20] │ coconut
... and 60 moreUna expresión regular son “reglas” que permiten extraer subsecciones de ese texto. Digamos que quiero todas aquellas frutas que terminan en “berry”. Entonces la expresión regular sería berry$.
str_view(fruit, "berry$") [6] │ bil<berry>
[7] │ black<berry>
[10] │ blue<berry>
[11] │ boysen<berry>
[19] │ cloud<berry>
[21] │ cran<berry>
[29] │ elder<berry>
[32] │ goji <berry>
[33] │ goose<berry>
[38] │ huckle<berry>
[50] │ mul<berry>
[70] │ rasp<berry>
[73] │ salal <berry>
[76] │ straw<berry>Y si queremos extraer esos valores,
fruit %>%
str_subset("berry$") [1] "bilberry" "blackberry" "blueberry" "boysenberry" "cloudberry"
[6] "cranberry" "elderberry" "goji berry" "gooseberry" "huckleberry"
[11] "mulberry" "raspberry" "salal berry" "strawberry" El conjunto total de expresiones regulares esta en este sitio https://www.regular-expressions.info/tutorial.html
factor(). Para reordenar, eliminar, etc. se puede usar el paquete forcats.lubridate con las funciones ymd(), mdy(), dmy(), ymd_hms(), ymd_hm(), ymd_h(), ymd_hms() y ymd_hm().left_join() y full_join() del paquete dplyr. Para más información sobre las uniones de tablas pueden revisar el capítulo Joins.Los modelos son herramientas complementarias al ordenamiento, transformación y visualización. Una vez que haya hecho sus preguntas lo suficientemente precisas, puede usar un modelo para responderlas. Los modelos son fundamentalmente herramientas matemáticas o computacionales, por lo que generalmente se escalan bien.
En este libro se usarán modelos estadísticos más fundamentales de estimación inferencial, intervalos de confianza y pruebas de hipótesis. Del punto de vista bayesiano se revisarán intervalos de credibilidad y pruebas de hipótesis bayesianas.
Para comunicar la forma más sencilla es usar Quarto. Quarto es un formato de documentos que permite combinar texto, código y resultados.
---
title: "Diamond sizes"
date: 2022-09-12
format: pdf
---
```{r}
#| label: setup
#| include: false
library(tidyverse)
smaller <- diamonds |>
filter(carat <= 2.5)
```
We have data about ` r nrow(diamonds)` diamonds.
Only ` r nrow(diamonds) - nrow(smaller)` are larger than 2.5 carats.
The distribution of the remainder is shown below:
```{r}
#| label: plot-smaller-diamonds
#| echo: false
smaller |>
ggplot(aes(x = carat)) +
geom_freqpoly(binwidth = 0.01)
```Este tipo de código documentado funciona bien para las primeras etapas de un proyecto de ciencia de datos. Sin embargo, cuando se quiere comunicar los resultados de forma más formal, lo mejor es usar un lenguaje de marcado como Markdown o LaTeX.
Durante todo el proceso de ciencia de datos es importante usar un sistema de control de versiones. El más popular es git. Git es un sistema de control de versiones distribuido, gratuito y de código abierto diseñado para manejar todo, desde proyectos pequeños hasta muy grandes con velocidad y eficiencia.
Para sus proyectos quiero que sigan las siguientes recomendaciones:
Instalen ProjectTemplate. Este paquete permite crear un proyecto de ciencia de datos con una estructura estándar.
Aprendan git y GitHub. Para esto pueden usar el libro Happy Git and GitHub for the useR. Un tutorial más interactivo es Learn Git Branching.
Usen Conventional Commits. Este es un estándar para los mensajes de los commits. Esto permite que los mensajes de los commits sean más descriptivos y que se puedan generar automáticamente los mensajes de los cambios en el proyecto.
Usen precommit para verificar que los mensajes de los commits cumplan con una serie de pasos como formatea de texto, revisión de código basura, etc.
Usen mensajes para los commits significativos. Este artículo explica muy bien una serie de reglas para hacer esto más fácil.
Ahora que conocemos el flujo completo y las herramientas de versionamiento, es momento de profundizar en la etapa más crítica antes de modelar: entender qué nos dicen los datos. El análisis exploratorio (AED) es el puente entre datos limpios y modelos confiables — un AED descuidado produce modelos incorrectos sin importar qué tan sofisticado sea el método estadístico.
Antes de modelar, es imprescindible entender la estructura de los datos mediante el análisis exploratorio. Esta etapa se ubica dentro del paso “Visualizar” del flujo de trabajo y es el puente entre ordenar los datos y construir un modelo. Un AED descuidado lleva a modelos incorrectos.
El análisis exploratorio de datos nos permite además:
Comprobación de errores.
Revisar los supuestos de los datos.
Selección preliminar del modelo a usar.
Determinar las relaciones entre las distintas variables.
Podemos clasificar el AED en dos categorías: No gráficos y los gráficos.
Antes de calcular medidas estadísticas complejas o construir gráficos, es necesario conocer la distribución básica de cada variable. Las herramientas no gráficas —tablas de frecuencias y medidas resumen— permiten hacer este diagnóstico rápidamente incluso para conjuntos de datos grandes donde una gráfica sería lenta de generar o difícil de interpretar.
En este tipo de arreglos es usado principalmente para variables categóricas o variables continuas con pocos valores distintos. En este contaremos las ocurrencias de cada una de las categorías de las variables y las ordenaremos en un arreglo rectangular. Además, podemos calcular la proporción o peso que representa cada una de las categorías con respecto al total.También se puede agregar los totales marginales de cada variable. Supongamos que tenemos una tabla de datos con las variables genero (Masculino o Femenino) y el grupo de edad (21, 42], (42, 62] y (62, 82] de ciertos individuos. La tabla de frecuencias nominales y relativas con algunos datos ficticios sería:
| Genero | Grupo de Edad | Frecuencia | Porcentaje |
|---|---|---|---|
| F | (21,42] | 13 | 21.67% |
| F | (42,62] | 11 | 18.33% |
| F | (62,82] | 12 | 20.00% |
| M | (21,42] | 7 | 11.67% |
| M | (42,62] | 5 | 8.33% |
| M | (62,82] | 12 | 20.00% |
| Total | 60 | 100% |
Al tener los datos cargados y limpios, la primera pregunta natural es: ¿en torno a qué valor se concentran? Las medidas de tendencia central responden exactamente eso. Estas tres medidas —media, mediana y moda— describen el “centro” de los datos de formas distintas, y elegir la correcta depende de la forma de la distribución.
Asumamos que la serie de datos para una variable es \(x_1,\ldots,x_n\).
\[ \hat{\mu} = \bar{x} = \frac{1}{n} \sum_{i=1}^n x_i. \]
Esta pondera todos los datos en caso de tengan una ponderación igualitaria. Existen otros tipos de medias donde se puede dar más valor a ciertos datos dependiendo de ciertas características.
Mediana empírica: Esta es otra medida de tendencia central y se obtiene ordenando \(x_1,\ldots,x_n\) y tomando justamente el valor que se encuentre en la mitad de la lista. El valor de la mediana dependerá del valor de \(n\):
\[ \hat{m} = \frac{x_{\frac{n}{2}} + x_{\frac{n}{2}+1}}{2} \]
\[ \hat{m} = x_{\frac{n+1}{2}} \]
En caso de distribuciones simetricas, la media y la mediana empíricas coinciden. Para datos asimetricamente unimodales, la media se encuentra más cerca de la cola más larga.
La mediana es robusta, es decir, cambiar unos pocos valores extremos no afecta su valor.
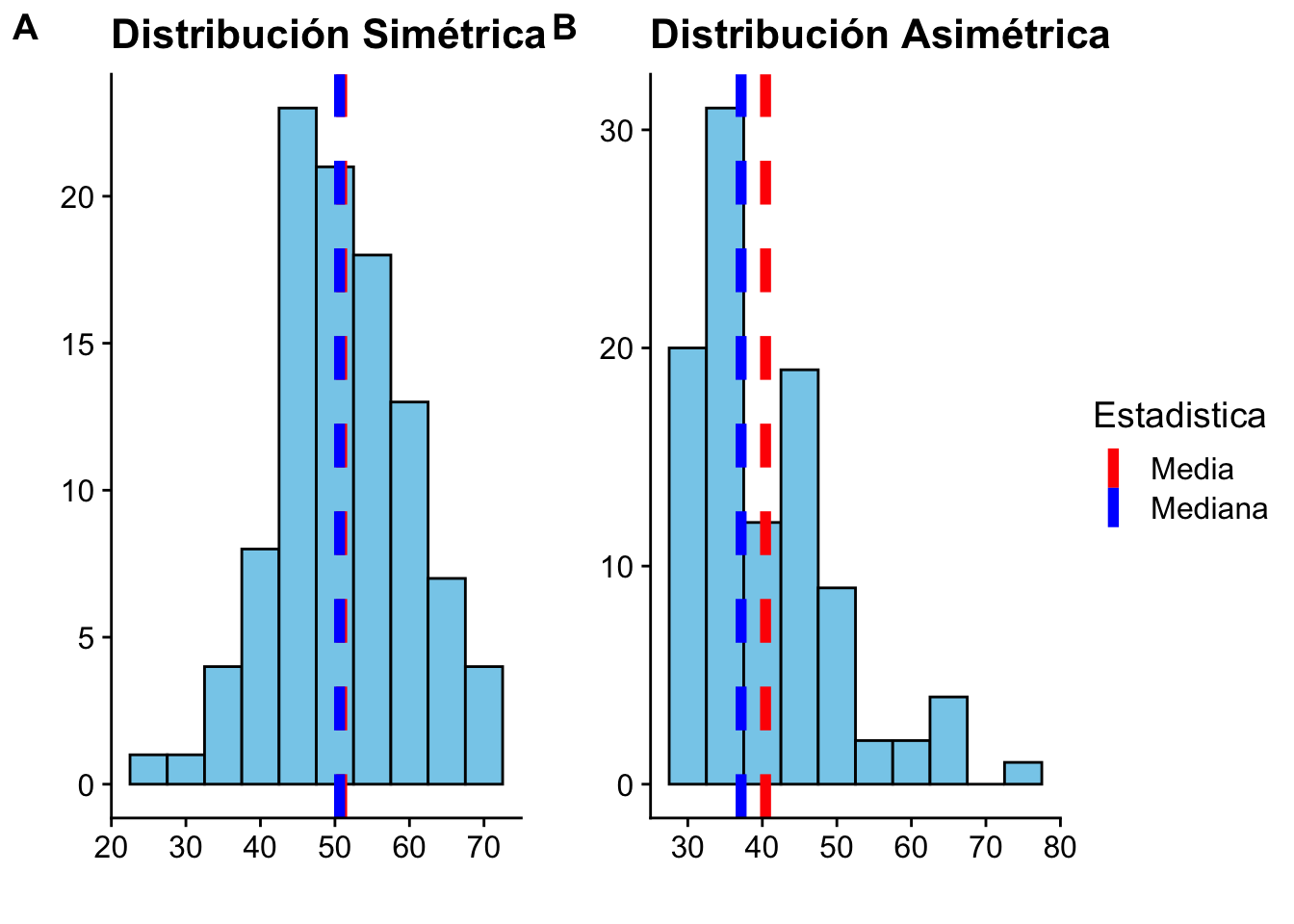
(array([ 2., 0., 3., 4., 6., 14., 18., 13., 9., 4., 11., 8., 5.,
2., 1.]), array([27.92528902, 30.92354305, 33.92179708, 36.92005111, 39.91830514,
42.91655917, 45.9148132 , 48.91306723, 51.91132126, 54.90957529,
57.90782932, 60.90608335, 63.90433738, 66.90259141, 69.90084544,
72.89909947]), <BarContainer object of 15 artists>)
<matplotlib.lines.Line2D object at 0x1480f88f0>
<matplotlib.lines.Line2D object at 0x14886c650>
Text(0.5, 1.0, 'Distribución Simétrica')
Text(0.5, 0, '')
Text(0, 0.5, '')
(array([36., 27., 15., 6., 7., 7., 1., 0., 0., 0., 0., 0., 0.,
0., 1.]), array([30.22484849, 33.99031488, 37.75578126, 41.52124765, 45.28671404,
49.05218043, 52.81764682, 56.5831132 , 60.34857959, 64.11404598,
67.87951237, 71.64497876, 75.41044514, 79.17591153, 82.94137792,
86.70684431]), <BarContainer object of 15 artists>)
<matplotlib.lines.Line2D object at 0x148812030>
<matplotlib.lines.Line2D object at 0x144a33440>
Text(0.5, 1.0, 'Distribución Asimétrica')
Text(0.5, 0, '')
Text(0, 0.5, '')<matplotlib.legend.Legend object at 0x1488123f0>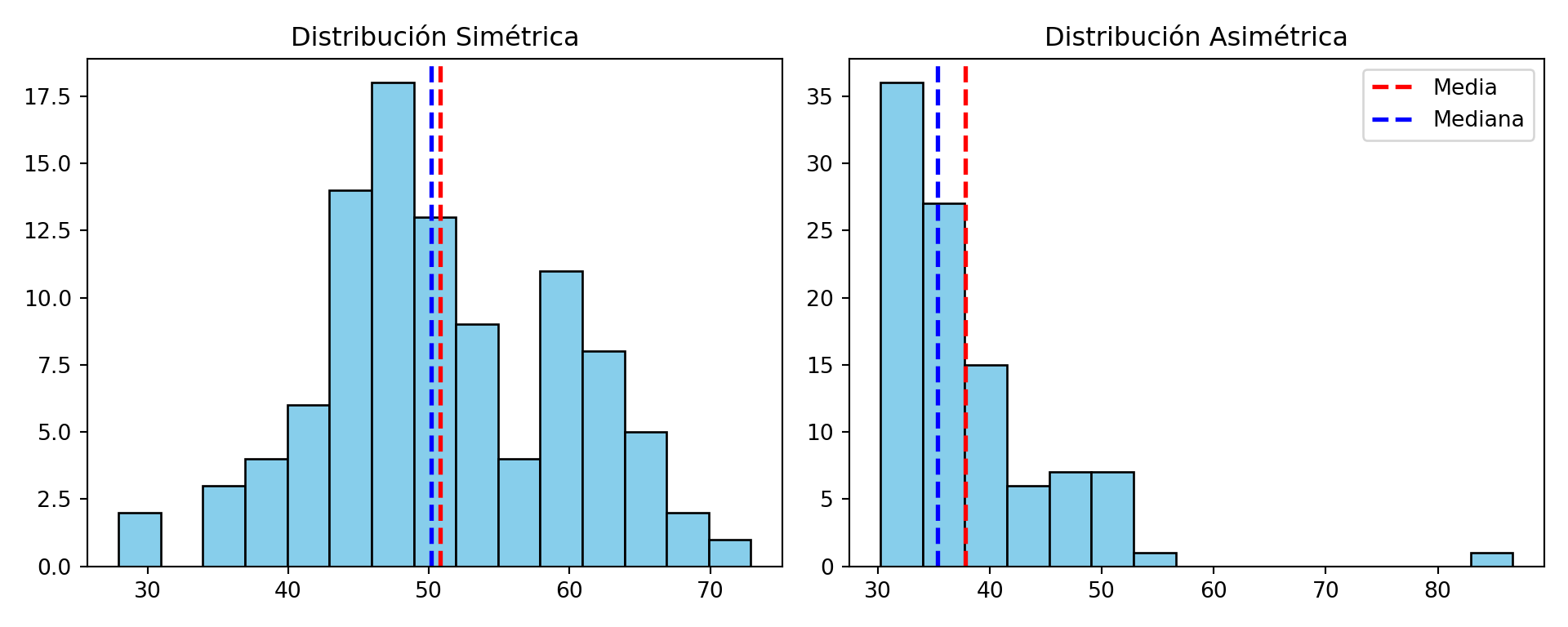
Mide que tan lejos se encuentran los datos, los unos de los otros.
\[\begin{equation*} \begin{aligned} \hat{\sigma}^2 & = \frac{1}{n} \sum_{i=1}^n {(X_i - \hat{\mu})}^{2}.\ \text{Sesgado} \\ \hat{s}^2 & = \frac{1}{n-1} \sum_{i=1}^n {(X_i - \hat{\mu})}^{2}.\ \text{Insesgado} \end{aligned} \end{equation*}\]
\[ s = \sqrt{\hat{s}^2} = \sqrt{\frac{1}{n-1} \sum_{i=1}^n {(X_i - \hat{\mu})}^2}\,. \]
El valor \(s\) mide cuanto en promedio los datos se alejan de la media.
\[ \mathbb{P}(X \leq q) = \alpha, \quad 0 < \alpha < 1 \]
\[ q(\alpha) = F^{-1}(\alpha) = \inf\{x \colon F(x) \geq \alpha\} \]
Definimos \(Q_1, Q_2, Q_3\) de la siguiente forma:
\[ \mathbb{P}(X \leq Q_1)=0.25, \quad \mathbb{P}(X \leq Q_2)=0.5, \quad \mathbb{P}(X \leq Q_3)=0.75 \]
La función fivenum genera los 5 números de Tukey que representan
\[ \{\min X,\; Q_1,\; Q_2,\; Q_3,\; \max X\}. \]
El IQR se define como:
\[ \text{IQR} = Q_3 - Q_1 \]
Al igual que la mediana, el IQR es una medida robusta de esparcimiento. Para encontrar “outliers” en los datos se puede comparar el \(Q_1\) y \(Q_3\) con el mínimo y máximo de los datos.
| Medida | Fórmula | Robusta |
|---|---|---|
| Media \(\bar{x}\) | \(\frac{1}{n}\sum x_i\) | No |
| Mediana \(\hat{m}\) | Valor central ordenado | Sí |
| Varianza \(s^2\) | \(\frac{1}{n-1}\sum(x_i-\bar{x})^2\) | No |
| IQR | \(Q_3 - Q_1\) | Sí |
Las medidas robustas (mediana, IQR) no se ven afectadas significativamente por outliers.
\[ \hat{\gamma}_1 = \frac{\frac{1}{n}\sum_{i=1}^n (X_i - \bar{X})^3}{s^3} \]
Sin embargo esta medida para distribuciones normales es 3. Por lo que para normalizarlo, se puede definir la curtosis de exceso como:
\[\begin{equation*} \gamma_2 = \frac{\mu_4}{\sigma^4} - 3 = \kappa - 3. \end{equation*}\]
Teóricamente para dos v.a \(X\), \(Y\) se puede calcular el nivel de relación que existe entre estas. A esa medida se denomina Covarianza. Esta medida depende de la escala de cada variable.
\[\begin{align*} \sigma_{xy} &= \text{Cov}(X,Y) = \mathbb{E}[(X - \mathbb{E}(X))(Y - \mathbb{E}(Y))] \\ &=\mathbb{E}(XY) - \mathbb{E}(X)\mathbb{E}(Y) \\ \hat{\sigma}_{xy}&= \frac{1}{n-1}\sum_{i=1}^n (X_i - \overline{X})(Y_i - \overline{Y}) \end{align*}\]
Ahora, se define la correlación como la covarianza estandarizada en el intervalo \([-1,1]\), donde la relación positiva perfecta es 1, y la relación perfecta negativa -1.
\[\begin{align*} \rho &= Corr(X,Y)= \frac{Cov(X,Y)}{\sigma_x \sigma_y} \\ \hat{\rho} &= \frac{\sum_{i=1}^{n} (X_i - \overline{X})(Y_i - \overline{Y})}{\sqrt{\sum_{i=1}^{n} (X_i - \overline{X})^2}\sqrt{\sum_{i=1}^{n} (Y_i - \overline{Y})^2}} \\ \end{align*}\]
El histograma es la primera herramienta visual para entender la forma de una distribución: ¿los datos se concentran en el centro o en los extremos? ¿hay valores atípicos? ¿la distribución es simétrica o asimétrica? Sin esta visión global, cualquier medida resumen puede ser engañosa.
Es una combinación de la tabla de contingencias y los diagramas de tallo y hoja pero para cualquier tipo de variable. Este gráfico proporciona el conteo o a totalidad de los datos:
\[ B_j =(x_0 + (j-1)h,x_0 +jh)\quad j\in\mathbb{Z} \quad h>0 \]
Cuento cuantas observaciones caen en cada intervalo \(B_j\), llame ese numero \(n_j\).
Divida cada \(n_j\) entre el total de observaciones \(n\) y defina:
\[ f_j = \frac{n_j}{n} \]
Finalmente definimos el histograma como función \(dx\). \(F\) es la densidad verdadera (desconocida) de \(x\)
\[ \hat{f}_n(x) = \frac{1}{nh}\sum_{i=1}^n \sum_{j} \mathbf{1}(X_i \in B_j)\,\mathbf{1}(x \in B_j) \] donde \(\mathbf{1}(X_i \in B_j) = 1\) si \(X_i \in B_j\) y \(0\) en caso contrario.
El ancho de la caja afecta la presentación de los datos; ya que, pueden mostrar distribuciones muy planas o muy picadas. El histograma es un estimador no paramétrico de la densidad.
# Generar datos de ejemplo
set.seed(123)
datos <- rnorm(1000, mean = 50, sd = 10)
# Definir origen y ancho del intervalo
# Un poco menor que el mínimo valor para incluir todos los datos
x0 <- min(datos) - 0.5
# Ancho de intervalo elegido
h <- 5
# Crear el histograma ggplot2 ajusta automáticamente los intervalos, pero para
# este ejemplo, definiremos el ancho de bin manualmente
ggplot(data.frame(datos), aes(x = datos)) +
geom_histogram(
binwidth = h,
color = "black",
fill = "skyblue",
boundary = x0
) +
xlab("Valor") +
ylab("Frecuencia relativa") +
ggtitle("Histograma con Ancho de Intervalo Definido") +
cowplot::theme_cowplot()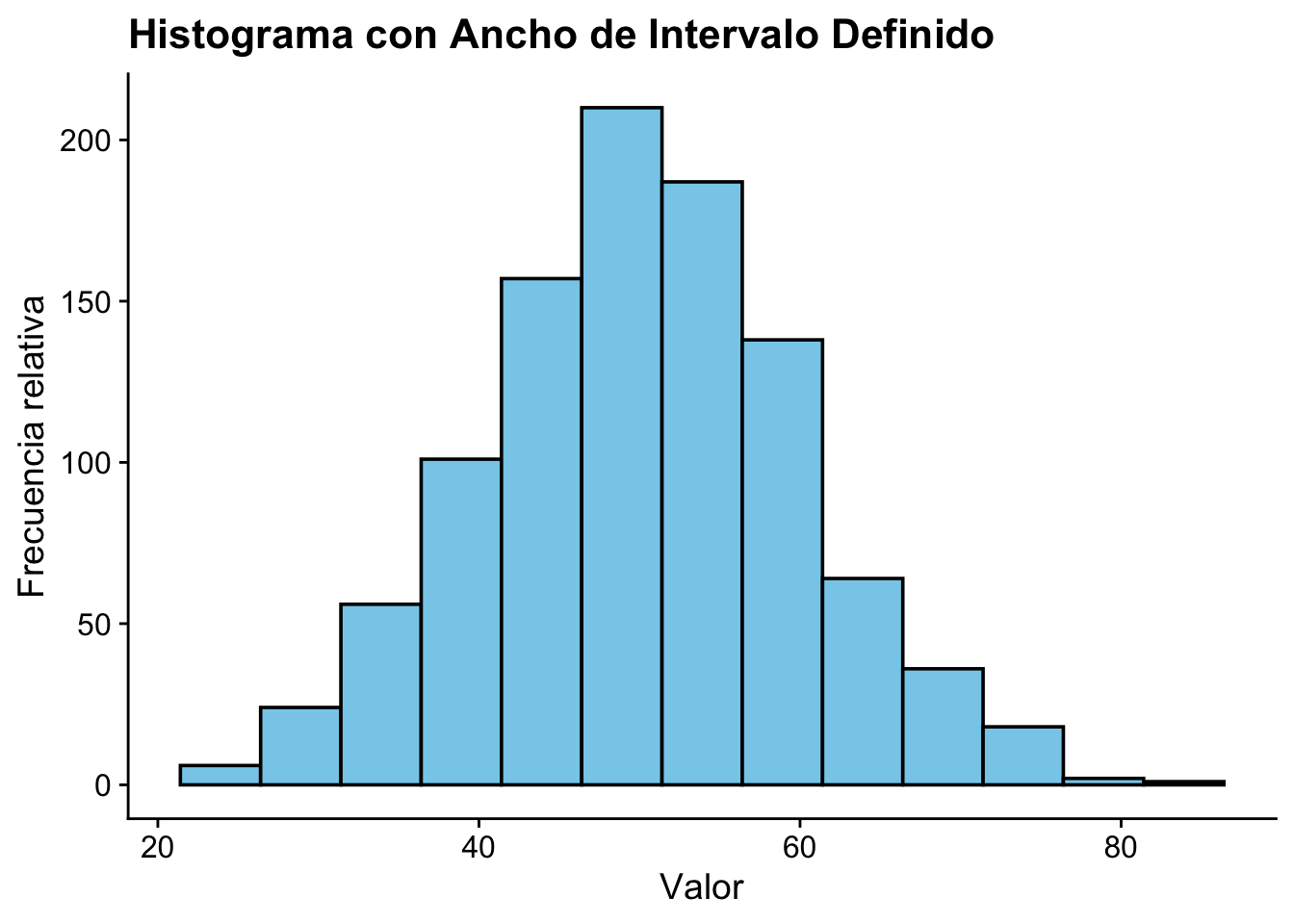
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(123)
datos = rng.normal(loc=50, scale=10, size=1000)
x0 = datos.min() - 0.5 # origen: un poco menor que el mínimo
h = 5 # ancho de intervalo
bins = np.arange(x0, datos.max() + h, h)
plt.figure(figsize=(7, 4))<Figure size 700x400 with 0 Axes>plt.hist(datos, bins=bins, color="skyblue", edgecolor="black")(array([ 4., 8., 25., 50., 94., 168., 203., 172., 137., 96., 30.,
12., 1.]), array([16.51718635, 21.51718635, 26.51718635, 31.51718635, 36.51718635,
41.51718635, 46.51718635, 51.51718635, 56.51718635, 61.51718635,
66.51718635, 71.51718635, 76.51718635, 81.51718635]), <BarContainer object of 13 artists>)plt.xlabel("Valor")Text(0.5, 0, 'Valor')plt.ylabel("Frecuencia relativa")Text(0, 0.5, 'Frecuencia relativa')plt.title("Histograma con Ancho de Intervalo Definido")Text(0.5, 1.0, 'Histograma con Ancho de Intervalo Definido')plt.tight_layout()
plt.show()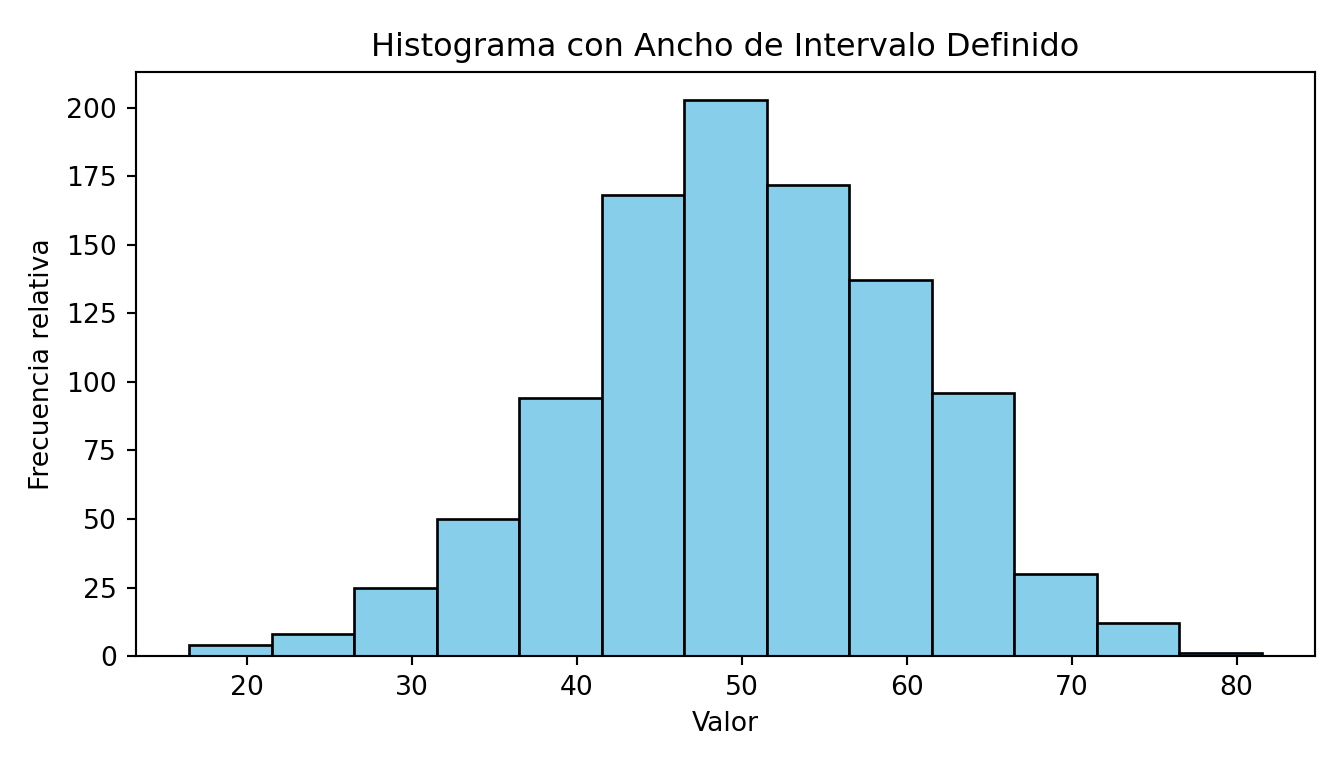
Mientras el histograma muestra la forma completa de la distribución, el boxplot la resume en cinco números y es especialmente útil para comparar grupos entre sí. Su fortaleza está en que es resistente a outliers por estar basado en cuantiles, no en la media.
Son gráficos que resumen casi de inmediato elementos de la distribución de una muestra como el IQR, la mediana, la asimetría y los outlers. Estos no logran percibir la multimodalidad.
datos <- c(
-3.2,
-1.7,
-0.4,
0.2,
0.3,
1.2,
1.5,
1.8,
2.4,
3.0,
4.3,
6.8,
9.0
)
ggplot() +
geom_boxplot(aes(y = datos))import matplotlib.pyplot as plt
datos = [-3.2, -1.7, -0.4, 0.2, 0.3, 1.2, 1.5, 1.8, 2.4, 3.0, 4.3, 6.8, 9.0]
fig, ax = plt.subplots(figsize=(3, 5))
ax.boxplot(datos, vert=True){'whiskers': [<matplotlib.lines.Line2D object at 0x1489bf2f0>, <matplotlib.lines.Line2D object at 0x148a37560>], 'caps': [<matplotlib.lines.Line2D object at 0x148a37860>, <matplotlib.lines.Line2D object at 0x148a37b90>], 'boxes': [<matplotlib.lines.Line2D object at 0x1489fcbf0>], 'medians': [<matplotlib.lines.Line2D object at 0x148a37e90>], 'fliers': [<matplotlib.lines.Line2D object at 0x148a70200>], 'means': []}ax.set_ylabel("Valor")Text(0, 0.5, 'Valor')plt.tight_layout()
plt.show()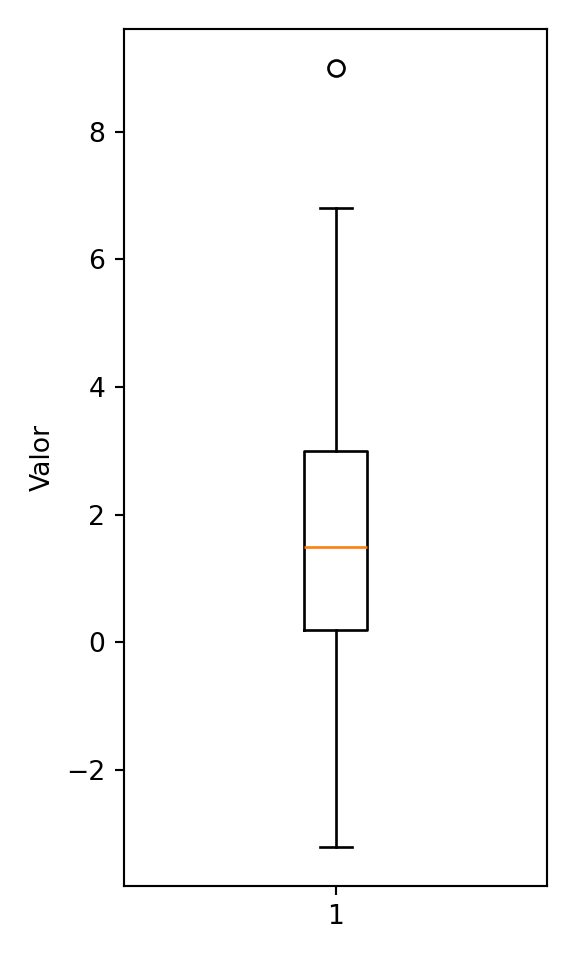

Tukey definió que un punto extremo es aquel que estuvieron fuera del rango:
\[ (Q_1 - 1.5 \times \text{IQR},\; Q_3 + 1.5 \times \text{IQR}) \]
Esta regla fue basada en la distribución normal donde alrededor 1 de 100 puntos se declararían como extremos.
Observación. ¿Que pasaría si la regla fuera 2 IQR?
Entonces en el ejemplo,
\[\begin{align*} Q_3 + 1.5\times IQR &= 3.0 + 1.5 \times 2.8 = 7.2 \\ Q_1 - 1.5\times IQR &= 0.2 - 1.5 \times 2.8 = -4.0 \end{align*}\]
Entonces el bigote superior sería al valor máximo que sea menor a 7.2 y el bigote inferior sería el valor mínimo que sea mayor a -4. En este caso serían 6.8 y -3.2 respectivamente.
Muchos métodos estadísticos asumen que los datos siguen una distribución normal. El QQ-plot es la herramienta estándar para verificar ese supuesto visualmente antes de aplicar cualquier modelo paramétrico. Si los puntos se desvían de la recta de referencia, el supuesto de normalidad no se sostiene y el modelo puede ser incorrecto.
Los quantile-quantile (QQ) plots son herramientas gráficas utilizadas para evaluar si una muestra sigue una distribución teórica específica. Comúnmente, se emplean para comparar si una muestra se ajusta a una distribución gaussiana (normal).
Nota Importante: Un QQ-plot no se limita solo a dibujar pares ordenados de datos de la muestra contra valores teóricos esperados bajo una distribución específica. Esta técnica es fundamental en estadística ya que muchos modelos, como los de regresión, asumen normalidad en los residuos. Es crucial verificar este supuesto para validar adecuadamente un modelo estadístico.
Lo primero es seleccionar los cuantiles muestrales tal y como lo explicamos anteriormente. Es decir, cuál es el punto de corte de modo que podamos acumular cierta probabilidad.
Los puntos teóricos se pueden seleccionar de la siguiente manera:
\[ p_i = \frac{i - \frac{1}{2}}{n} \]
O alternativamente, usando:
\[ p_{i,\alpha,\beta} = \frac{i-\alpha}{n+1-\alpha-\beta} \]
Donde \(\alpha, \beta \in \mathbb{R}\).
Según Hyndman (1996), es crucial analizar el comportamiento de \(p_{i,\alpha,\beta}\) para distintos valores de \(\alpha\) y \(\beta\). En este estudio, se demuestra que establecer \(\alpha=\beta=\frac{1}{2}\) cumple con varias propiedades deseables para la estimación de cuantiles. Por otro lado, Blom (1958) sugiere que \(\alpha=\beta=\frac{3}{8}\) ofrece un mejor ajuste para distribuciones normales, aunque no satisface todas las condiciones ideales.
Para datos que se aproximan a una distribución normal, se utiliza la fórmula:
\[ p_i=\frac{i-\frac{3}{8}}{n-\frac{1}{4}} \]
Ahora, el objetivo es comparar los datos con otra distribución teórica. Para ello, se usa la recta \(y = x\) como referencia. La lógica detrás es simple: si los puntos de nuestra muestra se alinean cercanamente a la recta \(y = x\), entonces se puede inferir que los datos siguen la distribución teórica.
Ejemplo 2.1 Siguiendo con el ejemplo anterior, se muestra cómo realizar un QQ-plot en con las funciones base de R con un conjunto de datos y compararlos con una distribución normal teórica:
datos <- c(-3.2, -1.7, -0.4, 0.2, 0.3, 1.2, 1.5, 1.8, 2.4, 3.0, 4.3, 6.8, 9.0)
qqnorm(datos, col = "blue", pch = 19)
qqline(datos, col = "red")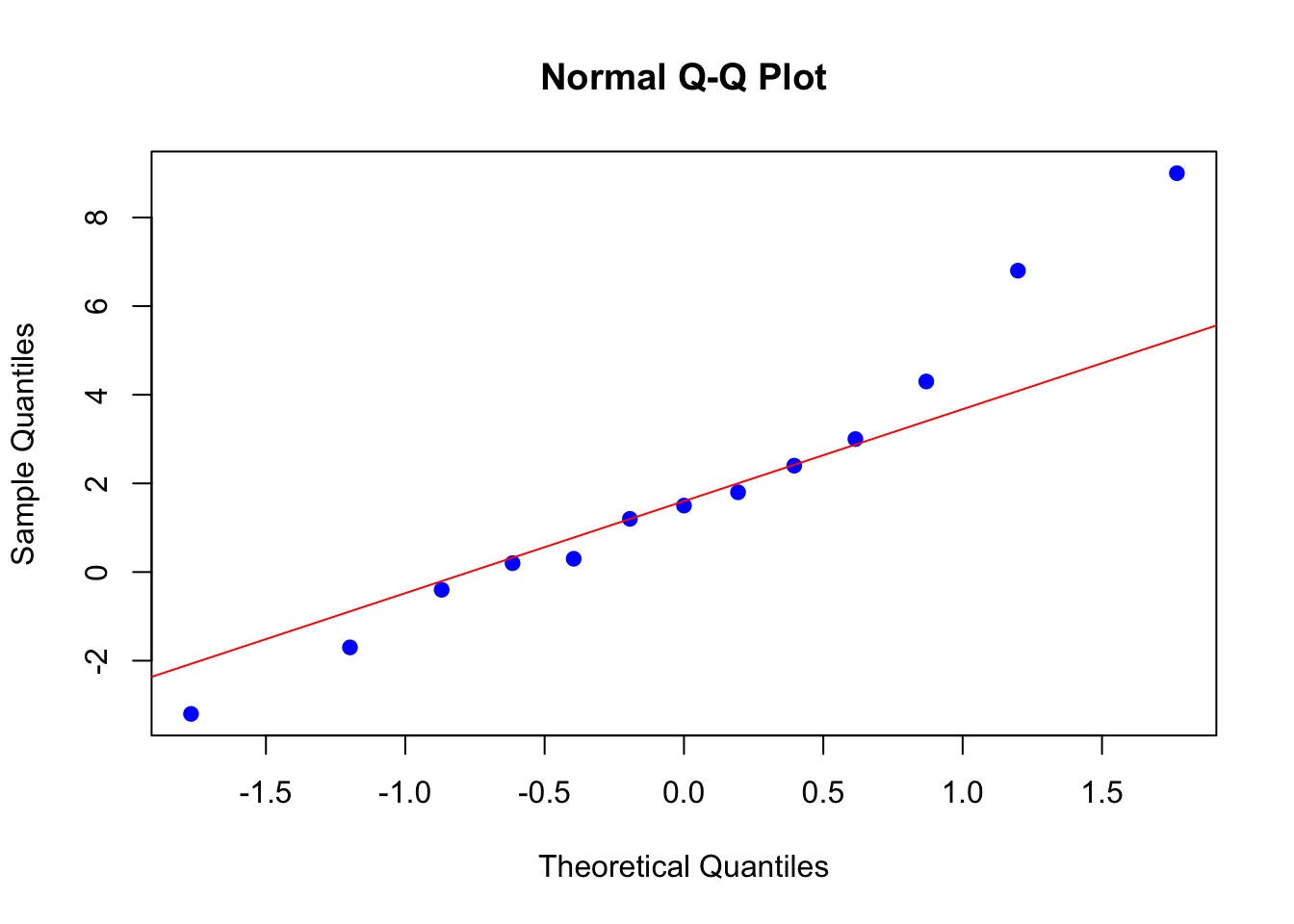
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
datos = np.array([-3.2, -1.7, -0.4, 0.2, 0.3, 1.2, 1.5, 1.8, 2.4, 3.0, 4.3, 6.8, 9.0])
fig, ax = plt.subplots(figsize=(5, 5))
(osm, osr), (slope, intercept, r) = stats.probplot(datos, dist="norm")
ax.scatter(osm, osr, color="blue", zorder=3)<matplotlib.collections.PathCollection object at 0x1489a2270>x_line = np.array([osm.min(), osm.max()])
ax.plot(x_line, slope * x_line + intercept, color="red", linewidth=2)[<matplotlib.lines.Line2D object at 0x148ab21e0>]ax.set_xlabel("Cuantiles teóricos (Normal)")Text(0.5, 0, 'Cuantiles teóricos (Normal)')ax.set_ylabel("Cuantiles muestrales")Text(0, 0.5, 'Cuantiles muestrales')ax.set_title("QQ-plot (funciones base)")Text(0.5, 1.0, 'QQ-plot (funciones base)')plt.tight_layout()
plt.show()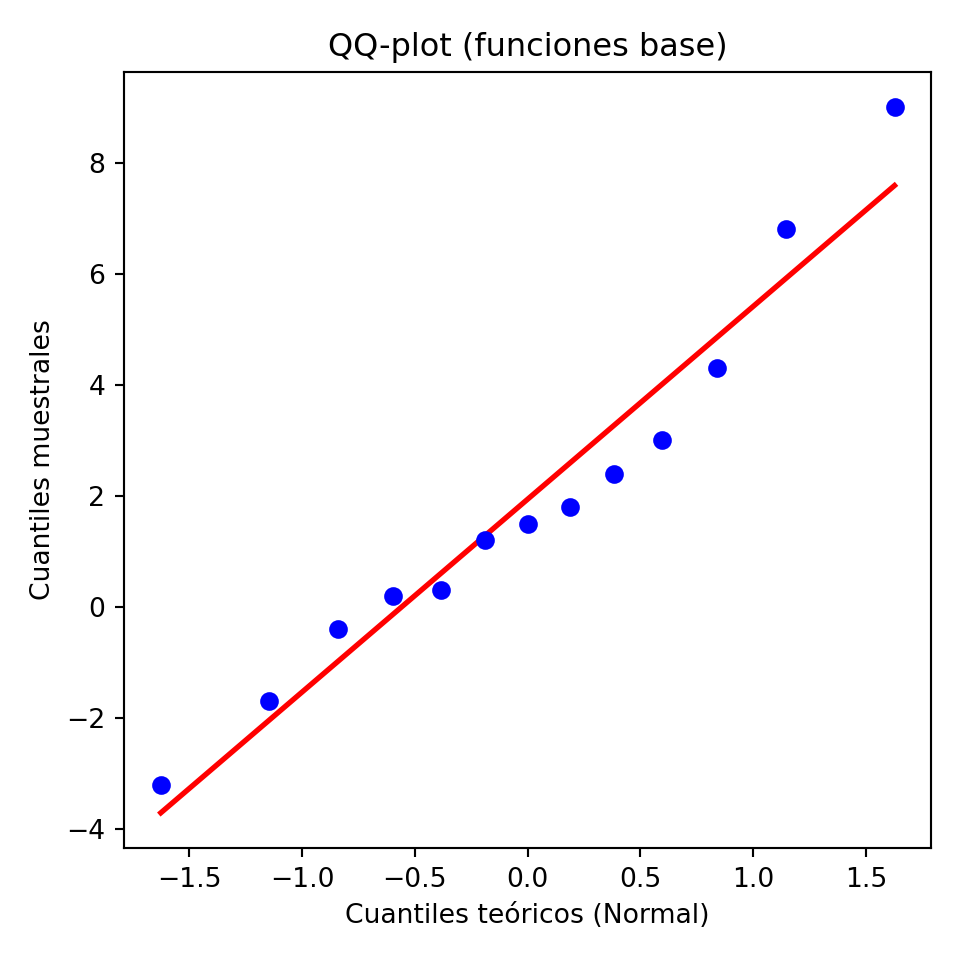
Si lo queremos hacer en ggplot2, podemos usar la función geom_qq:
df <- data.frame(y = datos)
ggplot(df, aes(sample = y)) +
geom_qq(color = "blue") +
geom_qq_line(color = "red") +
cowplot::theme_cowplot()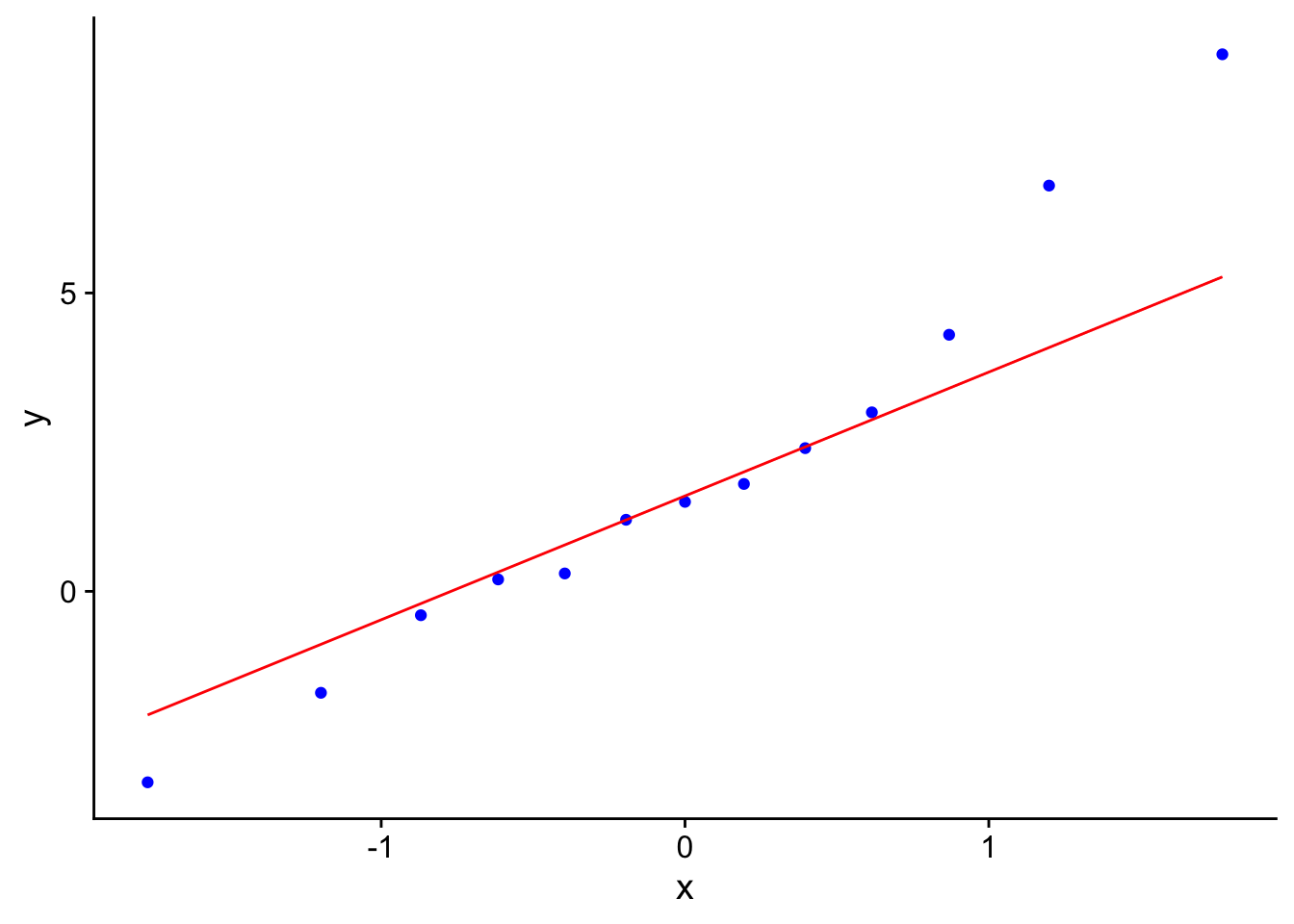
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
datos = np.array([-3.2, -1.7, -0.4, 0.2, 0.3, 1.2, 1.5, 1.8, 2.4, 3.0, 4.3, 6.8, 9.0])
fig, ax = plt.subplots(figsize=(5, 5))
(osm, osr), (slope, intercept, r) = stats.probplot(datos, dist="norm")
ax.scatter(osm, osr, color="blue", zorder=3)<matplotlib.collections.PathCollection object at 0x148aec200>x_line = np.array([osm.min(), osm.max()])
ax.plot(x_line, slope * x_line + intercept, color="red", linewidth=2)[<matplotlib.lines.Line2D object at 0x148a2cb60>]ax.set_xlabel("Cuantiles teóricos (Normal)")Text(0.5, 0, 'Cuantiles teóricos (Normal)')ax.set_ylabel("Cuantiles muestrales")Text(0, 0.5, 'Cuantiles muestrales')ax.set_title("QQ-plot: datos vs. Normal")Text(0.5, 1.0, 'QQ-plot: datos vs. Normal')plt.tight_layout()
plt.show()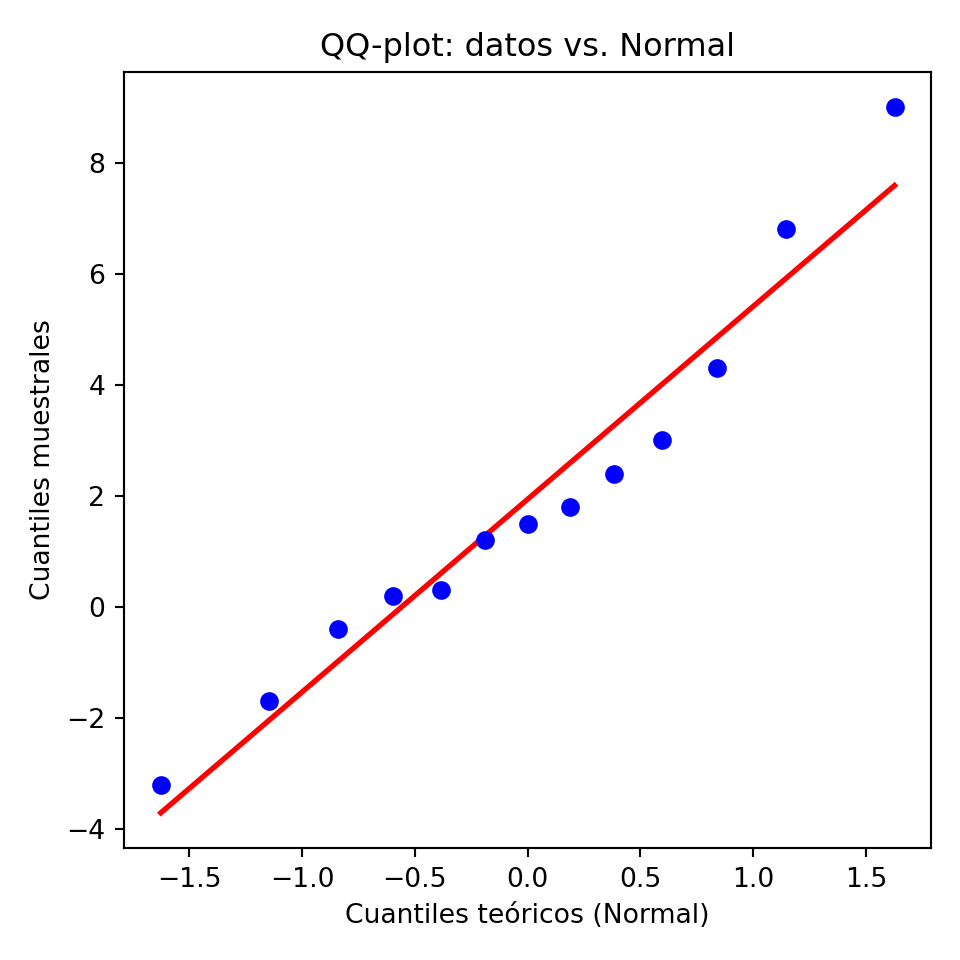
Ejemplo 2.2 A continuación, se muestra cómo realizar un QQ-plot en R con un conjunto de datos lognormales y compararlos con una distribución normal teórica:
set.seed(123)
datos_lognormales <- rlnorm(100, meanlog = 0, sdlog = 1)
qqnorm(datos_lognormales, col = "blue", pch = 19)
qqline(datos_lognormales, col = "red")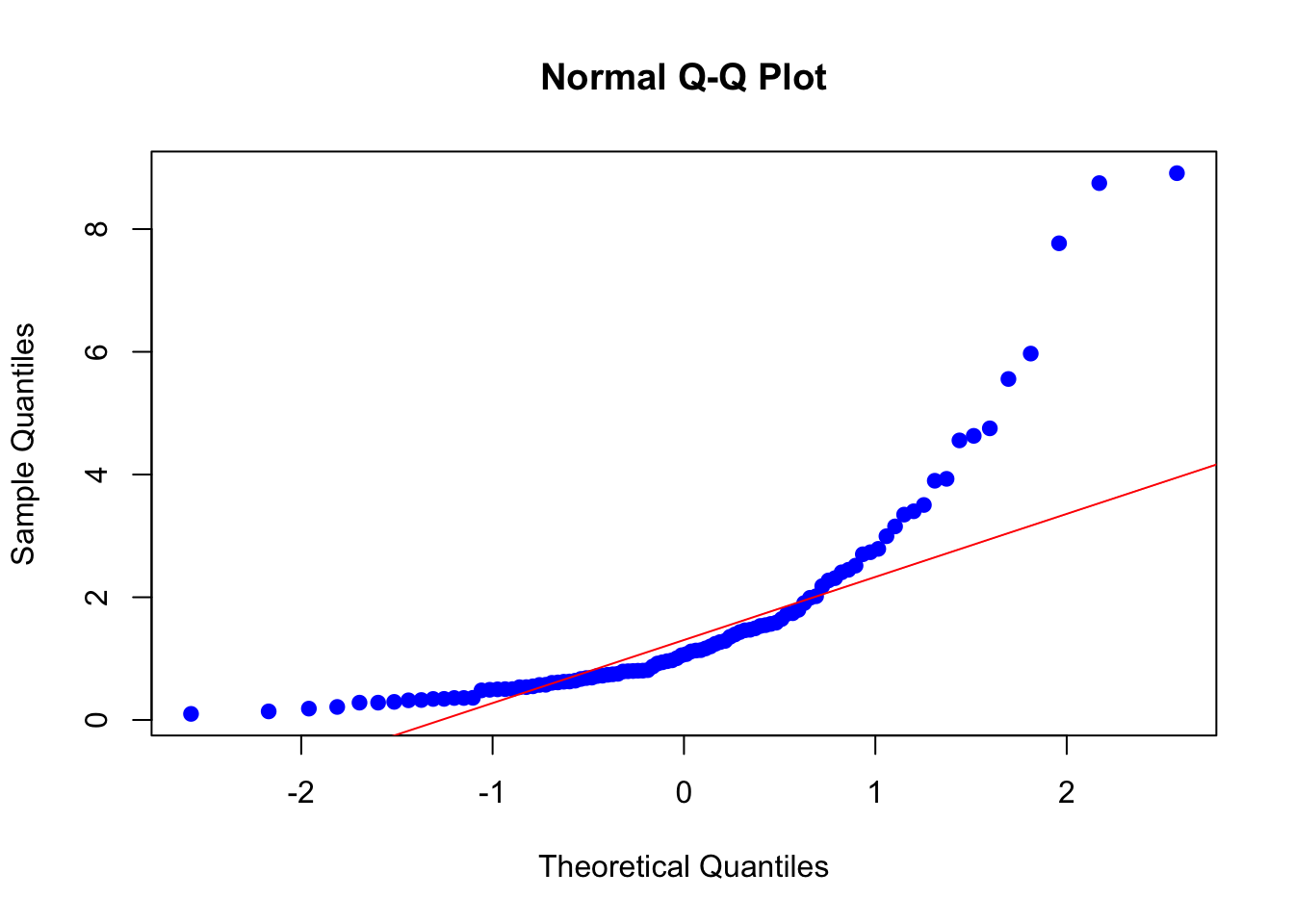
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
rng = np.random.default_rng(123)
datos_lognormales = rng.lognormal(mean=0, sigma=1, size=100)
fig, ax = plt.subplots(figsize=(5, 5))
(osm, osr), (slope, intercept, r) = stats.probplot(datos_lognormales, dist="norm")
ax.scatter(osm, osr, color="blue", zorder=3)<matplotlib.collections.PathCollection object at 0x148bd5700>x_line = np.array([osm.min(), osm.max()])
ax.plot(x_line, slope * x_line + intercept, color="red", linewidth=2)[<matplotlib.lines.Line2D object at 0x148bd44a0>]ax.set_xlabel("Cuantiles teóricos (Normal)")Text(0.5, 0, 'Cuantiles teóricos (Normal)')ax.set_ylabel("Cuantiles muestrales")Text(0, 0.5, 'Cuantiles muestrales')ax.set_title("QQ-plot: datos lognormales vs. Normal")Text(0.5, 1.0, 'QQ-plot: datos lognormales vs. Normal')plt.tight_layout()
plt.show()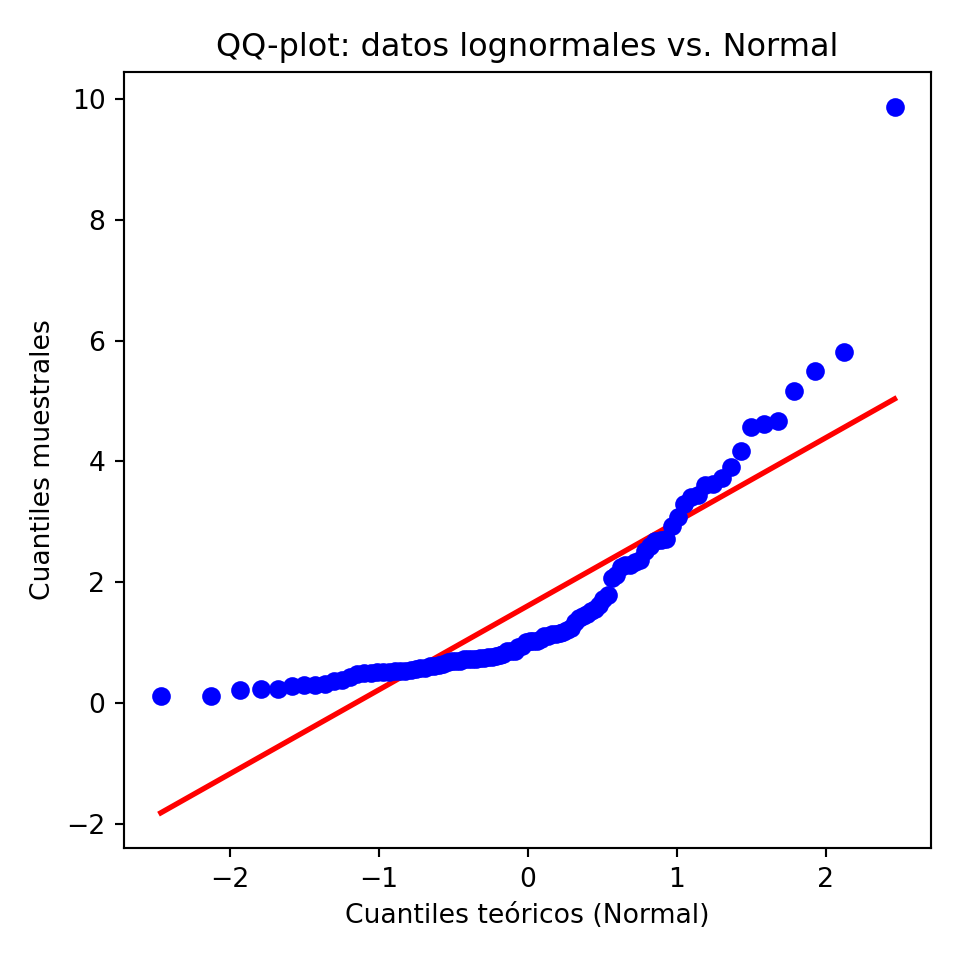
En este artículo, exploraremos la construcción y los principios detrás de varios tipos de gráficos utilizando el paquete ggplot2 en R. Los gráficos son herramientas fundamentales en el análisis de datos para explorar, entender y presentar los datos de manera visual.
Los gráficos de barras son esenciales para comparar cantidades entre categorías distintas. Aquí algunos puntos clave y buenas prácticas para su creación:
Ejemplo 2.3
library(ggplot2)
# Datos de ejemplo
datos <- data.frame(
Categoria = c("A", "B", "C", "D"),
Valor = c(23, 45, 10, 30)
)
ggplot(datos, aes(x = Categoria, y = Valor)) +
geom_bar(stat = "identity", fill = "skyblue", color = "black") +
cowplot::theme_cowplot() +
labs(title = "Gráfico de Barras", x = "Categoría", y = "Valor")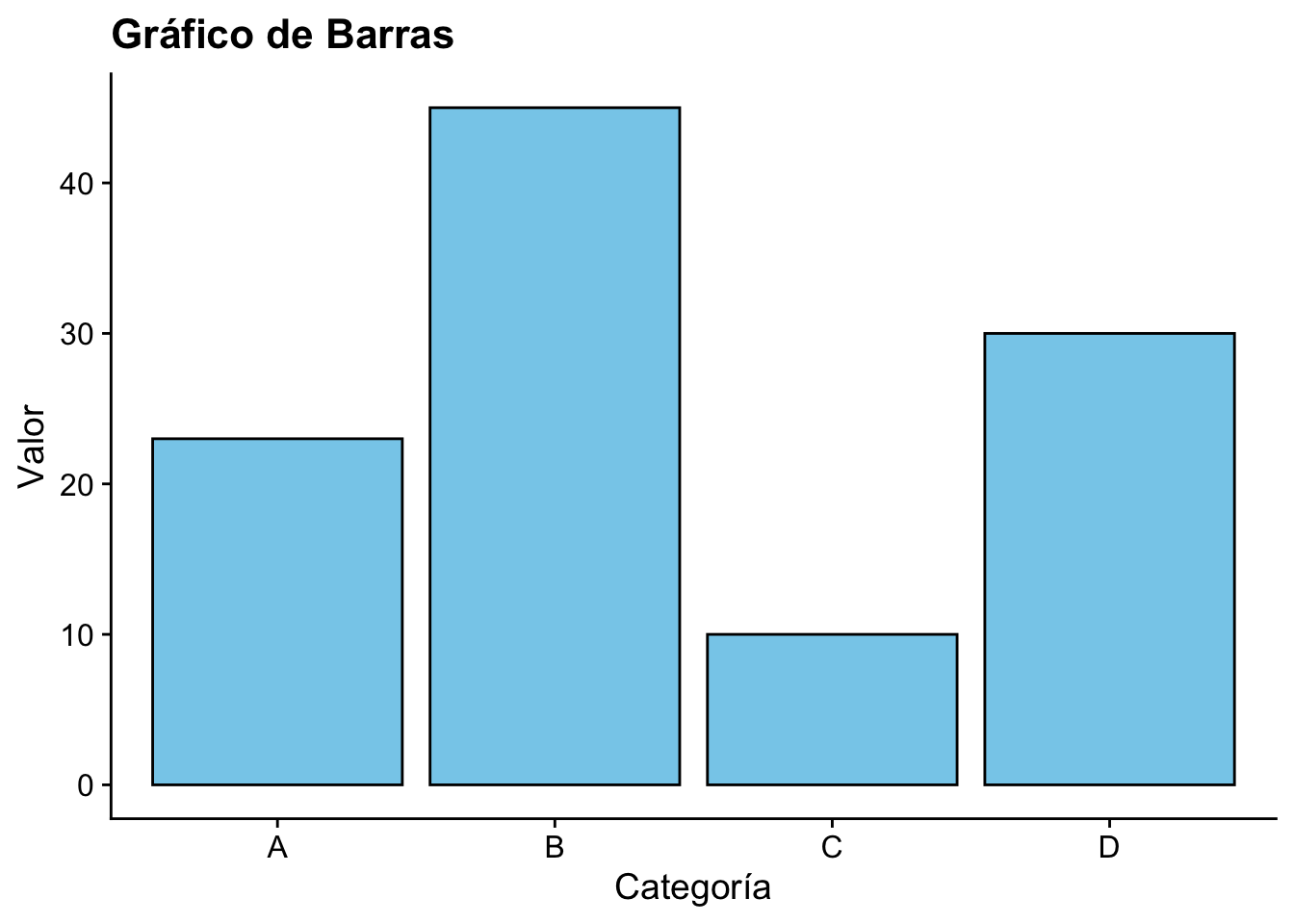
import matplotlib.pyplot as plt
categorias = ["A", "B", "C", "D"]
valores = [23, 45, 10, 30]
fig, ax = plt.subplots(figsize=(5, 4))
ax.bar(categorias, valores, color="skyblue", edgecolor="black")<BarContainer object of 4 artists>ax.set_xlabel("Categoría")Text(0.5, 0, 'Categoría')ax.set_ylabel("Valor")Text(0, 0.5, 'Valor')ax.set_title("Gráfico de Barras")Text(0.5, 1.0, 'Gráfico de Barras')ax.set_ylim(0, max(valores) * 1.2) # base cero(0.0, 54.0)plt.tight_layout()
plt.show()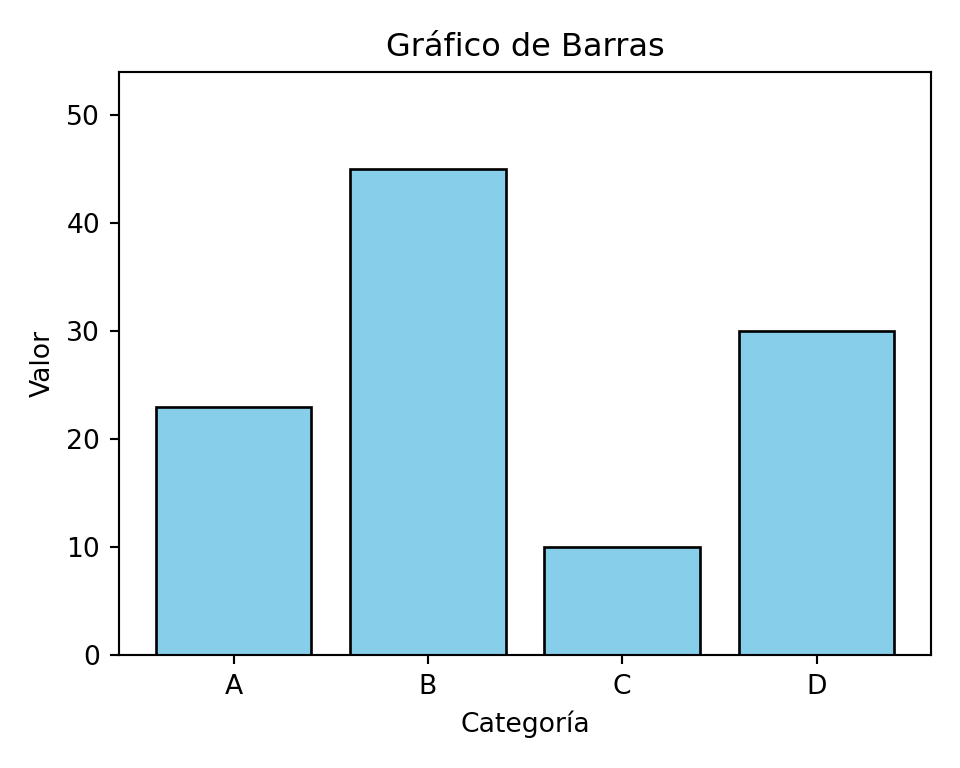
Los gráficos de líneas son una herramienta fundamental en la visualización de datos, especialmente útiles para mostrar tendencias o cambios a lo largo del tiempo. Este tipo de gráfico conecta puntos de datos individuales con líneas, lo que facilita la percepción de la dirección y el ritmo de cambio en los datos.
Se debe considerar lo siguiente:
Ejemplo 2.4
library(ggplot2)
# Datos de ejemplo: Ventas mensuales a lo largo de un año
ventas <- data.frame(
Mes = factor(1:12, labels = month.abb),
Ventas = c(120, 150, 130, 170, 160, 180, 200, 220, 210, 230, 240, 260)
)
# Gráfico de líneas
ggplot(ventas, aes(x = Mes, y = Ventas, group = 1)) +
geom_line(color = "blue", linewidth = 1) + # Línea azul
geom_point(color = "red", size = 2) + # Puntos rojos
cowplot::theme_cowplot() +
scale_y_continuous(limits = c(0, 300)) + # Manteniendo la base cero
labs(
title = "Ventas Mensuales a lo Largo del Año",
x = "Mes",
y = "Ventas ($)"
) +
theme(legend.position = "none")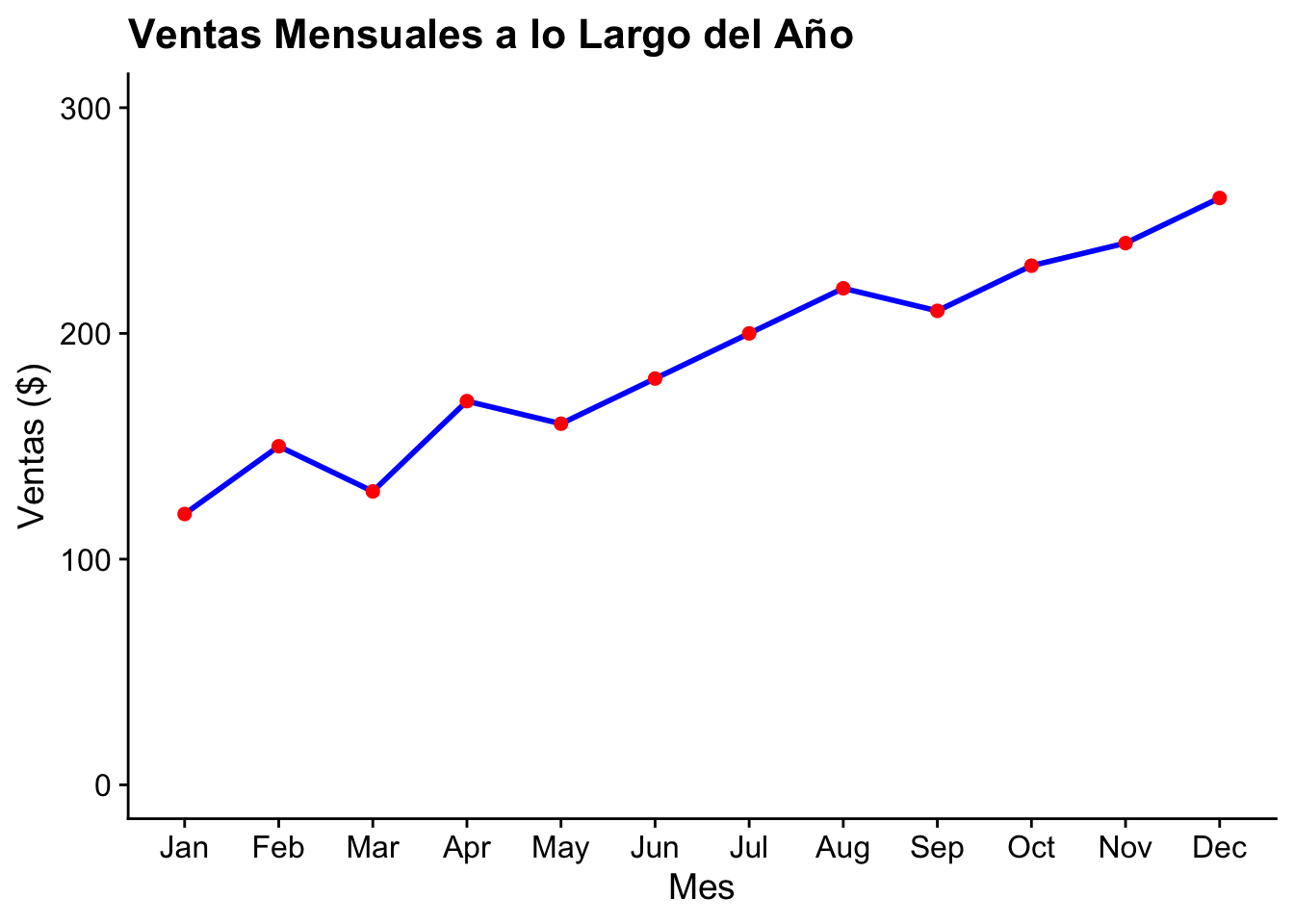
import matplotlib.pyplot as plt
meses = [
"Jan",
"Feb",
"Mar",
"Apr",
"May",
"Jun",
"Jul",
"Aug",
"Sep",
"Oct",
"Nov",
"Dec",
]
ventas = [120, 150, 130, 170, 160, 180, 200, 220, 210, 230, 240, 260]
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(
meses,
ventas,
color="blue",
linewidth=2, # Línea azul
marker="o",
markerfacecolor="red",
markersize=6,
) # Puntos rojos[<matplotlib.lines.Line2D object at 0x148ab23f0>]ax.set_ylim(0, 300) # base cero(0.0, 300.0)ax.set_xlabel("Mes")Text(0.5, 0, 'Mes')ax.set_ylabel("Ventas ($)")Text(0, 0.5, 'Ventas ($)')ax.set_title("Ventas Mensuales a lo Largo del Año")Text(0.5, 1.0, 'Ventas Mensuales a lo Largo del Año')plt.tight_layout()
plt.show()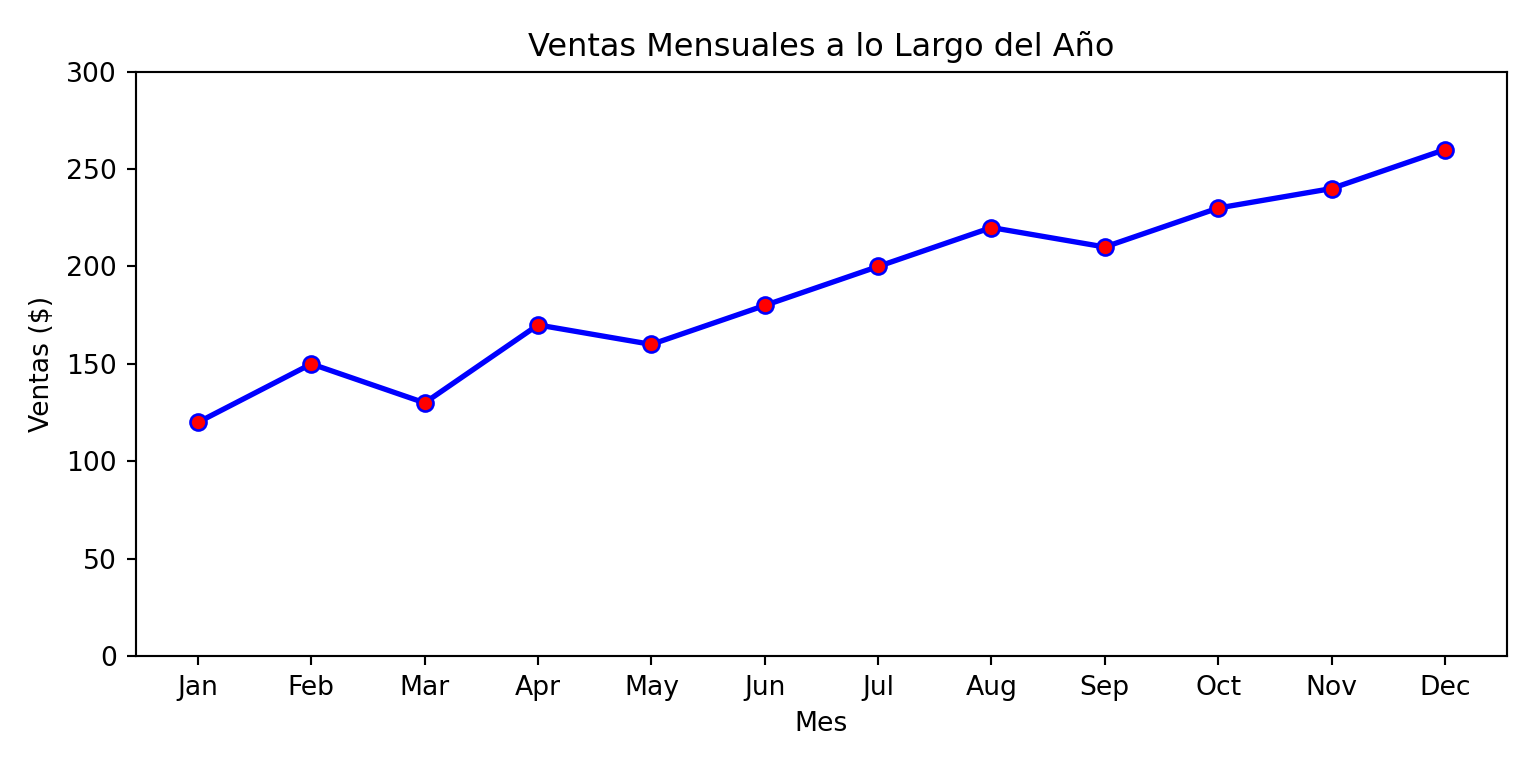
Los gráficos de dispersión son esenciales en estadística para explorar la relación entre dos variables cuantitativas, permitiendo identificar patrones, tendencias y posibles correlaciones.
Variables Cuantitativas: Los gráficos de dispersión son ideales para comparar dos variables cuantitativas, donde cada punto representa un par de valores.
Correlación: Una de las principales utilidades de los gráficos de dispersión es evaluar la presencia y dirección de una correlación entre las variables.
Identificación de Outliers: Permiten identificar valores atípicos que podrían influir en el análisis.
Escala Adecuada: Asegúrate de que ambos ejes reflejen adecuadamente el rango de datos para cada variable, evitando distorsiones.
Marcadores Diferenciados: Si el gráfico incluye categorías (datos agrupados), utiliza colores o formas de marcadores diferentes para distinguir entre grupos.
Evitar Sobrecarga: Demasiados puntos sobre una pequeña área pueden hacer que el gráfico sea difícil de leer. Considera usar transparencia o jittering si es necesario.
Análisis Complementario: A menudo, los gráficos de dispersión revelan la necesidad de análisis estadísticos adicionales, como ajustes de línea o modelos de regresión.
library(ggplot2)
# Datos de ejemplo
set.seed(42)
X <- rnorm(100)
Y <- X + rnorm(100, mean = 0.1)
datos <- data.frame(
X = X,
Y = Y,
Categoria = as.factor(sample(c("Grupo 1", "Grupo 2"), 100, replace = TRUE))
)
ggplot(datos, aes(x = X, y = Y, color = Categoria)) +
# Transparencia para manejar la sobreposición
geom_point(alpha = 0.7) +
theme_minimal() +
labs(title = "Gráfico de Dispersión con Categorías") +
# Colores personalizados
scale_color_manual(values = c("Grupo 1" = "blue", "Grupo 2" = "red"))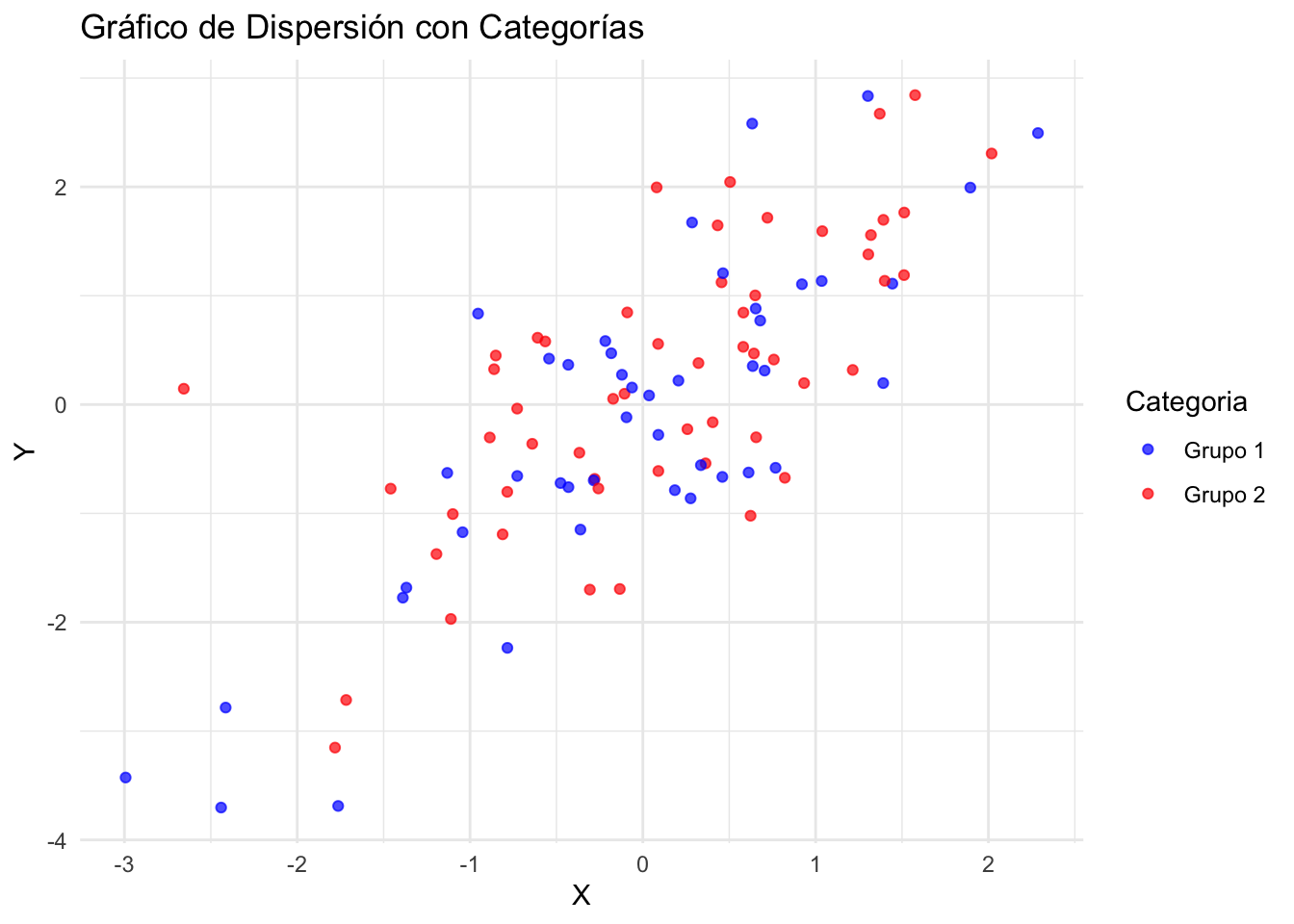
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(42)
X = rng.standard_normal(100)
Y = X + rng.normal(0.1, 1, 100)
categorias = rng.choice(["Grupo 1", "Grupo 2"], size=100)
colores = {"Grupo 1": "blue", "Grupo 2": "red"}
fig, ax = plt.subplots(figsize=(6, 5))
for grupo in ["Grupo 1", "Grupo 2"]:
mask = categorias == grupo
ax.scatter(X[mask], Y[mask], color=colores[grupo], alpha=0.7, label=grupo)<matplotlib.collections.PathCollection object at 0x148a1d0d0>
<matplotlib.collections.PathCollection object at 0x1489bdd00>ax.set_title("Gráfico de Dispersión con Categorías")Text(0.5, 1.0, 'Gráfico de Dispersión con Categorías')ax.legend()<matplotlib.legend.Legend object at 0x148b8f050>plt.tight_layout()
plt.show()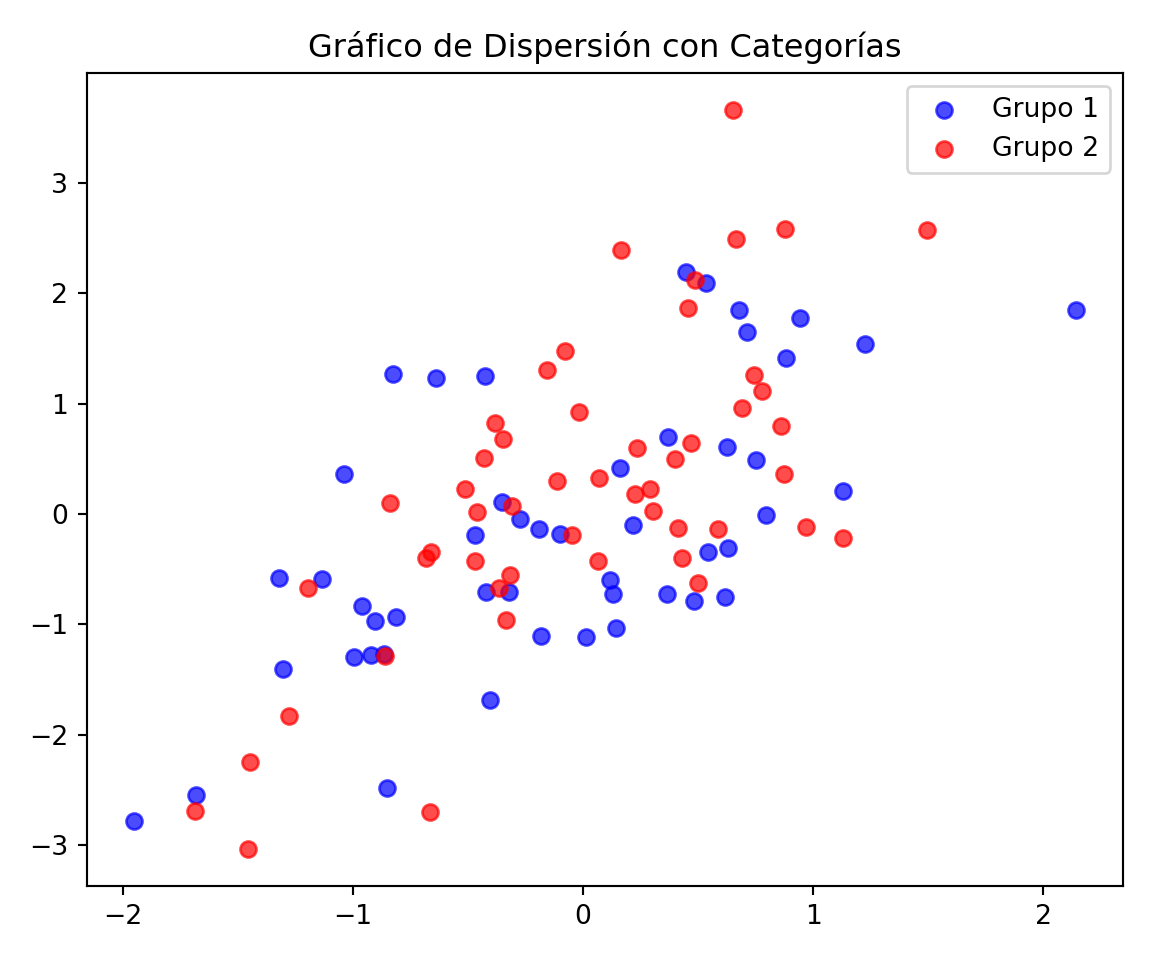
Nunca use gráficos de pastel. Los gráficos de barras son superiores en casi todos los aspectos. Los gráficos de barras son más fáciles de leer, menos engañosos y menos susceptibles a la manipulación.
| Concepto | Definición | Herramienta R |
|---|---|---|
| Tidy data | Cada variable = columna, cada obs. = fila, cada valor = celda | tidyr::pivot_longer/wider() |
| Escala nominal | Categorías sin orden | factor() |
| Escala ordinal | Categorías con orden | factor(..., ordered=TRUE) |
| Escala intervalo | Diferencias con sentido, sin cero natural | — |
| Escala racional | Diferencias + cero natural | — |
| Re-escalamiento | \(X' = \frac{X - \min}{\max - \min}(\max_n - \min_n) + \min_n\) | scales::rescale() |
| Z-score | \(X' = (X - \bar{X})/s\) | scale() |
| Box-Cox | \(X' = (X^\lambda - 1)/\lambda\) si \(\lambda \neq 0\), \(\log X\) si \(\lambda = 0\) | MASS::boxcox() |
| Media \(\bar{x}\) | \(\frac{1}{n}\sum x_i\) — no robusta | mean() |
| Mediana \(\hat{m}\) | Valor central de datos ordenados — robusta | median() |
| Varianza \(s^2\) | \(\frac{1}{n-1}\sum(x_i-\bar{x})^2\) — no robusta | var() |
| IQR | \(Q_3 - Q_1\) — robusto | IQR() |
| Asimetría \(\hat{\gamma}_1\) | \(\frac{\frac{1}{n}\sum(x_i-\bar{x})^3}{s^3}\) | moments::skewness() |
| Curtosis de exceso \(\gamma_2\) | \(\frac{\mu_4}{\sigma^4} - 3\) | moments::kurtosis() |
| Correlación \(\hat{\rho}\) | \(\frac{\sum(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum(x_i-\bar{x})^2\sum(y_i-\bar{y})^2}} \in [-1,1]\) | cor() |
| Histograma | Estimador no paramétrico de densidad con intervalos de ancho \(h\) | geom_histogram() |
| Boxplot | Resumen de 5 números + outliers (regla Tukey: \(\pm 1.5 \times IQR\)) | geom_boxplot() |
| QQ-plot | Cuantiles muestrales vs. teóricos — alineación = buen ajuste | geom_qq() + geom_qq_line() |