Recordar las definiciones de error de tipo I (\(\alpha\)) y tipo II (\(\beta\)) y de región crítica.
Comprender por qué no se pueden minimizar \(\alpha\) y \(\beta\) simultáneamente y qué compromiso resuelve el cociente de verosimilitud.
Aplicar el criterio de Neyman-Pearson para construir la prueba más potente entre dos hipótesis simples.
Calcular\(\alpha\) y \(\beta\) tanto analíticamente como numéricamente (R/Python) para los casos exponencial, normal y Bernoulli.
Analizar el efecto del tamaño de muestra \(n\) sobre la potencia \(1-\beta\).
En los capítulos anteriores estimamos parámetros desconocidos de una población. Ahora daremos un paso distinto: decidir entre dos afirmaciones sobre esa población. Este capítulo aborda el caso más simple —dos hipótesis puntuales— y sienta la base para las pruebas con hipótesis compuestas que veremos después.
11.1 Hipótesis simples
Ejemplo 11.1 Supongamos que tenemos un sistema en el que se registran los tiempos de servicio de los clientes, \(X_1,\dots, X_n\). El administrador del sistema no está seguro de la distribución con la que se atienden a los clientes. Se consideran dos posibilidades:
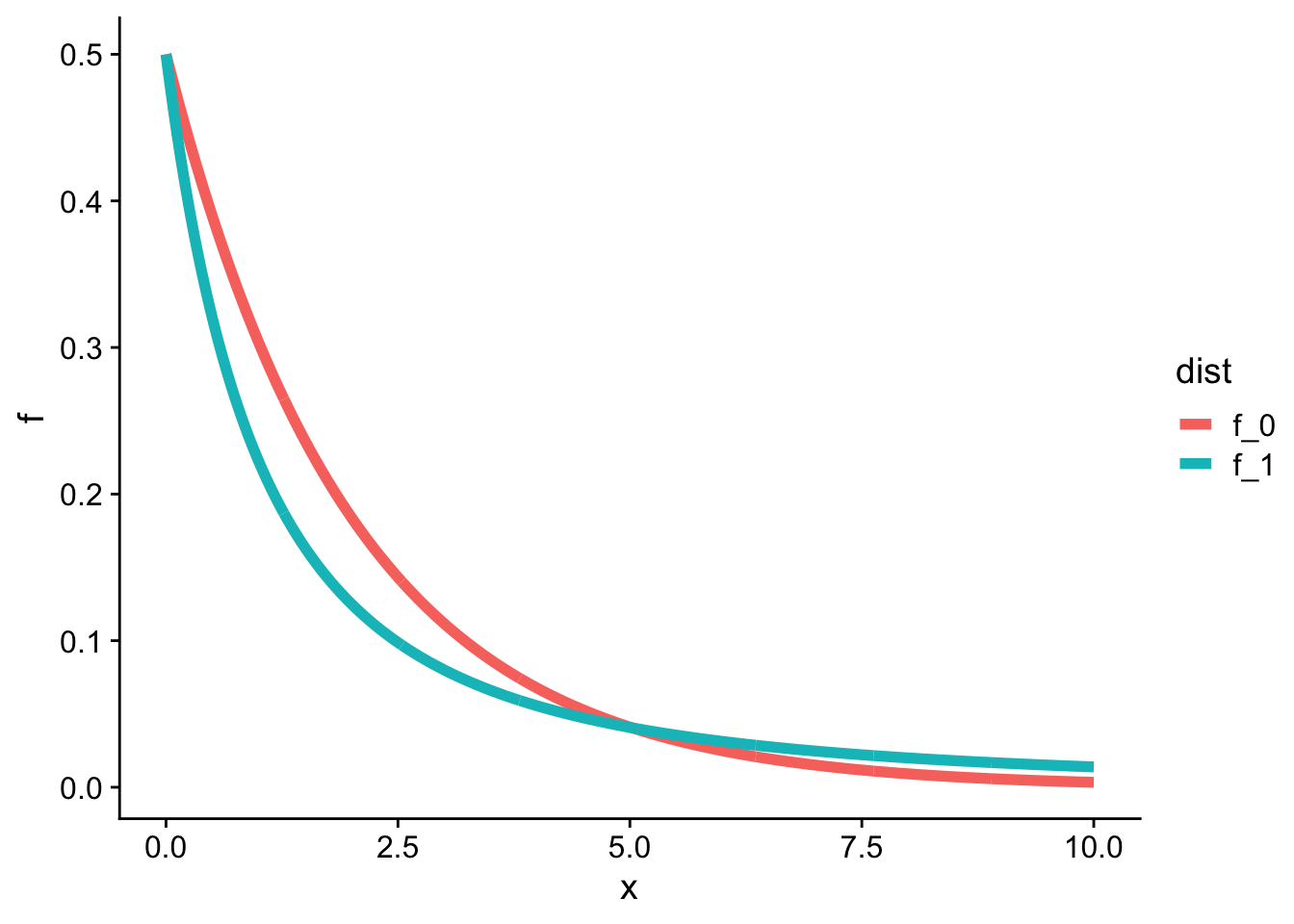
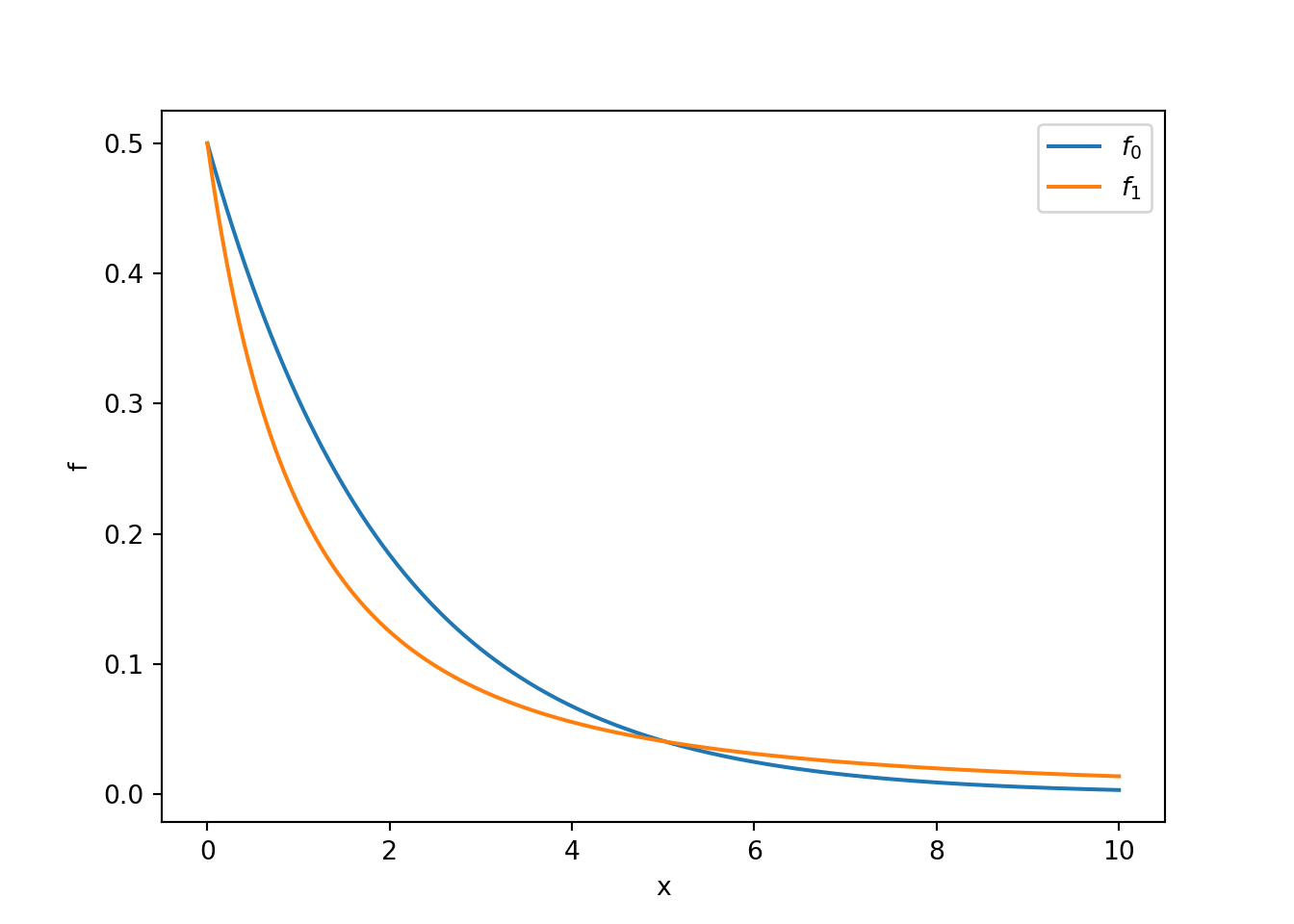
La primera distribución, denotada \(f_1(x)\), es dada por:
n <-1x <-seq(0, 10, length.out =1000)f1 <-2/ (2+ x)^2# densidad bajo H_1 con n = 1f0 <-1/2*exp(-1/2* x) # exponencial(1/2) bajo H_0df <-data.frame(x =c(x, x),f =c(f0, f1),dist =c(rep("f_0", 1000), rep("f_1", 1000)))ggplot(df, aes(x, f, color = dist)) +geom_line(linewidth =2) + cowplot::theme_cowplot()
Código
import numpy as npimport matplotlib.pyplot as pltx = np.linspace(0, 10, 1000)f1 =2/ (2+ x) **2# densidad bajo H_1 con n = 1f0 =0.5* np.exp(-0.5* x) # exponencial(1/2) bajo H_0fig, ax = plt.subplots()ax.plot(x, f0, label=r"$f_0$")ax.plot(x, f1, label=r"$f_1$")ax.set_xlabel("x")ax.set_ylabel("f")ax.legend()plt.show()
En el caso anterior, teníamos dos distribuciones, pero alternativamente, podemos definir el problema de prueba de hipótesis en términos de un parámetro desconocido \(\theta\). Supongamos que \(\theta\) puede tomar dos posibles valores, \(\theta_0\) y \(\theta_1\), que corresponden a las distribuciones \(f_0\) y \(f_1\) respectivamente. Entonces estamos probando \(H_0: \theta=\theta_0\) vs \(H_1:\theta=\theta_1\).
Al realizar la prueba de hipótesis, estamos interesados en dos tipos de errores:
El error de tipo I, denotado \(\alpha(\delta)\), es la probabilidad de rechazar la hipótesis nula cuando en realidad es cierta. Es decir, \(\alpha(\delta) = \mathbb P[\text{Rechazo }H_0|\theta=\theta_0 ]\).
El error de tipo II, denotado \(\beta(\delta)\), es la probabilidad de no rechazar la hipótesis nula cuando en realidad es falsa. Es decir, \(\beta(\delta) = \mathbb P[\text{No rechazo }H_0|\theta=\theta_1 ]\).
Siguiendo con el ejemplo anterior, supongamos que, después de un análisis preliminar, decidimos rechazar la hipótesis nula si \(X_1 > 4\) (cuando solo observamos un cliente, es decir, \(n=1\)). Entonces, las probabilidades de los errores de tipo I y II son:
La integral de \(f_1\) debe ser estimada numéricamente ya que no hay una fórmula predefinida en R.
Nota
Nuestro objetivo es encontrar un procedimiento de prueba, \(\delta\), que minimice simultáneamente los errores de tipo I y II, \(\alpha(\delta)\) y \(\beta(\delta)\) respectivamente. En otras palabras, queremos minimizar la cantidad \(a\alpha(\delta) + b\beta(\delta)\), donde \(a\) y \(b\) son constantes positivas. Nótese la asimetría que aparecerá más adelante: fijamos primero un tope para \(\alpha\) (el error que consideramos más grave) y después minimizamos \(\beta\); los dos errores no se tratan de forma simétrica.
Teorema 11.1 Supongamos que existe un procedimiento de prueba, \(\delta^*\), que rechaza \(H_0:\theta=\theta_0\) si \(af_0(x) < bf_1(x)\), y no rechaza \(H_0\) si \(af_0(x) > bf_1(x)\).
Si \(af_0(x) = bf_1(x)\), puede rechazarse o no \(H_0\). Para cualquier otro procedimiento de prueba, \(\delta\), tenemos que
y lo anterior es mínimo si \(af_0(x)-bf_1(x)<0\) en toda la muestra y no hay punto en donde \(af_0(x)-bf_1(x)>0\).
Definición 11.1 Definimos el Cociente de Verosimilitud como el cociente entre las densidades de las dos hipótesis:
\[
\dfrac{f_1(x)}{f_0(x)}.
\]
Este cociente de verosimilitud está directamente relacionado con el procedimiento de prueba óptimo que hemos discutido anteriormente. Existe además un estadístico emparentado, el cociente de verosimilitud generalizado
que retomaremos para hipótesis compuestas. Para el caso de dos hipótesis simples que nos ocupa aquí, basta con el cociente \(f_1(x)/f_0(x)\) de la definición anterior.
Corolario 11.1 Bajo las condiciones del teorema anterior, si \(a,b>0\) entonces la prueba \(\delta\) que minimiza \(a\alpha(\delta) + b\beta(\delta)\) rechaza \(H_0\) si el cociente de verosimilitud es mayor a \(\dfrac ab\).
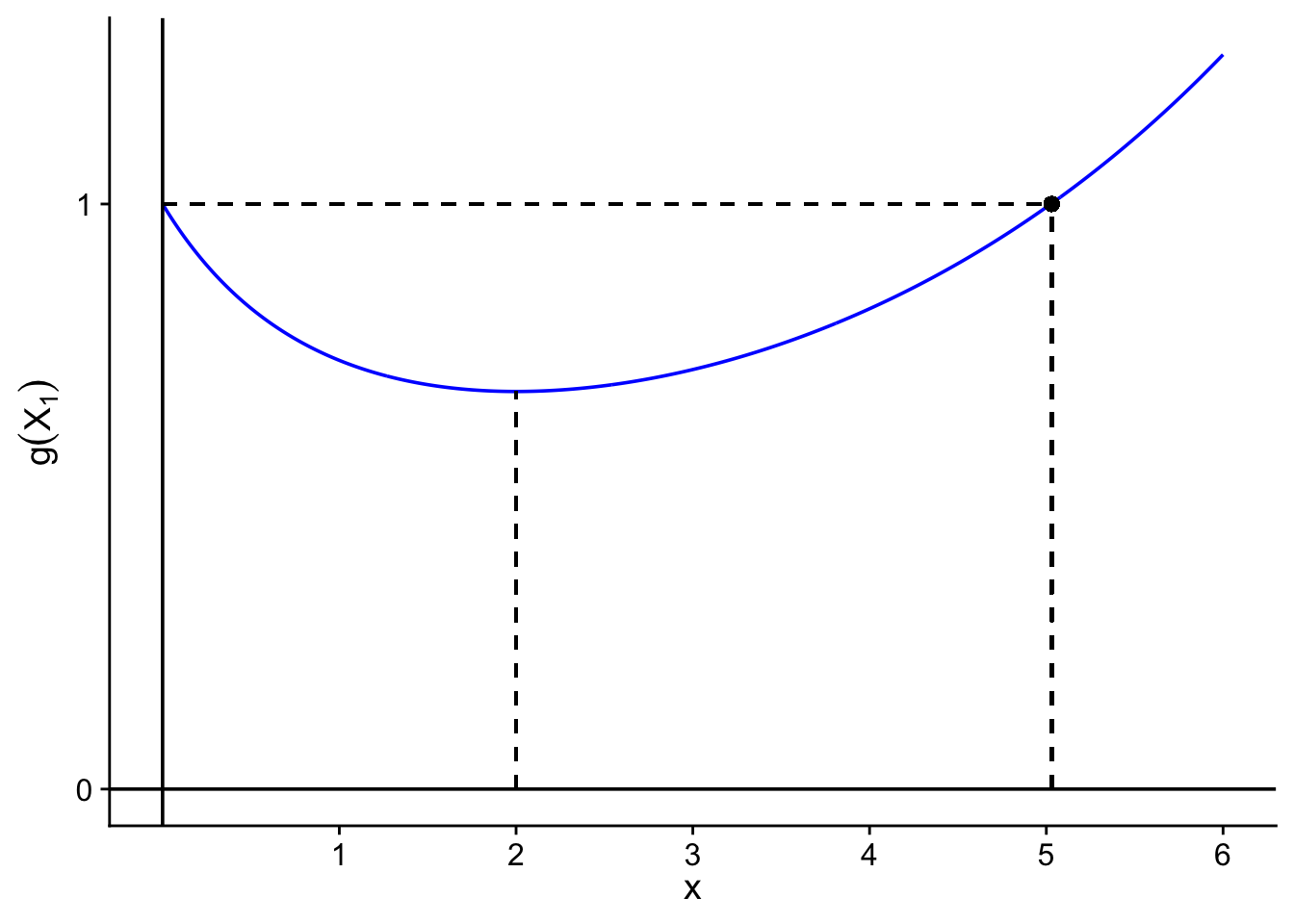
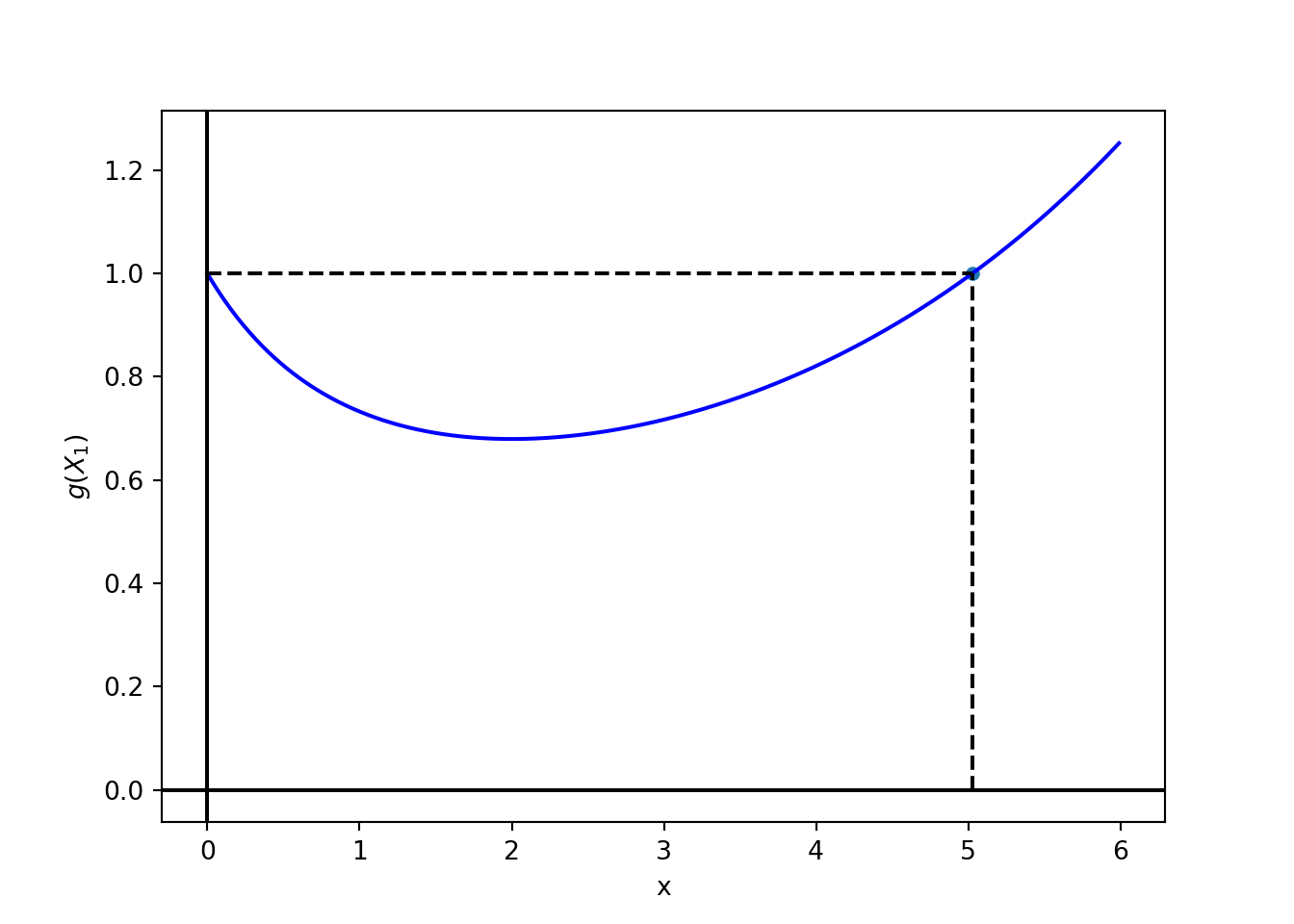
Volviendo al ejemplo del servicio al cliente, en lugar de rechazar \(H_0: \theta = \theta_0\) si \(X_1>4\), queremos encontrar \(a\) y \(b\) que balanceen ambos tipos de errores.
Supongamos que tomamos \(a=b\), entonces, basado en el corolario anterior, rechazamos \(H_0\) si
Warning in geom_segment(aes(x = 0, xend = 5.03, y = 1, yend = 1), linetype = 2): All aesthetics have length 1, but the data has 601 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.
Warning in geom_segment(aes(x = 5.03, xend = 5.03, y = 0, yend = 1), linetype = 2): All aesthetics have length 1, but the data has 601 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.
Warning in geom_segment(aes(x = 2, xend = 2, y = 0, yend = 0.6795705), linetype = 2): All aesthetics have length 1, but the data has 601 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.
Warning in geom_point(aes(x = 5.03, y = 1), size = 2): All aesthetics have length 1, but the data has 601 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.
[<matplotlib.lines.Line2D object at 0x142ec6600>]
<matplotlib.lines.Line2D object at 0x1406f0470>
<matplotlib.lines.Line2D object at 0x142e704d0>
[<matplotlib.lines.Line2D object at 0x142eb25a0>]
[<matplotlib.lines.Line2D object at 0x142ef4920>]
<matplotlib.collections.PathCollection object at 0x1407da930>
Text(0.5, 0, 'x')
Text(0, 0.5, '$g(X_1)$')
De acuerdo con el gráfico, la desigualdad es cierta si \(X_1>c\). Podemos calcular numéricamente que \(c\approx5.03\).
Por lo tanto, rechazamos \(H_0\) si \(X_1>5.03\). Finalmente los errores de tipo I y II son:
\(\alpha\) y \(\beta\) se mueven en direcciones opuestas: bajar una sube la otra.
Minimizar \(a\alpha+b\beta\) siempre conduce a una regla basada en el cociente \(f_1/f_0\).
El umbral del cociente, \(a/b\), codifica cuánto pesa cada tipo de error.
11.2 Criterio de Neyman-Pearson
Retomemos de nuevo las definiciones de los errores de tipo I y II:
Definición 11.2
Definimos \(\alpha(\delta)\) como la probabilidad de un error de Tipo I (falso positivo), es decir, rechazar la hipótesis nula \(H_0\) cuando es verdadera. Deseamos que \(\alpha(\delta)\) sea menor o igual a un nivel de significancia \(\alpha_0\) preestablecido.
\(\beta(\delta)\) es la probabilidad de un error de Tipo II (falso negativo), es decir, no rechazar la hipótesis nula \(H_0\) cuando es falsa. Queremos minimizar \(\beta(\delta)\).
Lema 11.1 Supongamos que tenemos un procedimiento de prueba, \(\delta'\), que no rechaza \(H_0\) si \(f_1(x)<kf_0(x)\) y rechaza \(H_0\) si \(f_1(x)>kf_0(x)\). En el caso de que \(f_1(x)=kf_0(x)\), podemos decidir rechazar o no \(H_0\).
Si tenemos otro procedimiento de prueba, \(\delta\), que tiene un error de Tipo I no mayor que \(\delta'\) (\(\alpha(\delta)\leq \alpha(\delta')\)), entonces el error de Tipo II de \(\delta\) será mayor o igual que el error de Tipo II de \(\delta'\) (\(\beta(\delta)\geq \beta(\delta')\)).
NotaPrueba
Tome \(a=k\) y \(b=1\) en el corolario y teoremas anteriores. Como \[
k\alpha(\delta')+\beta(\delta')\leq k\alpha(\delta)+\beta(\delta),
\] entonces \(\alpha(\delta)\leq \alpha(\delta')\) implica que \(\beta(\delta)\geq \beta(\delta')\).
Observación. La consecuencia directa de este lema es que, si queremos encontrar una prueba que cumpla el criterio de Neyman-Pearson, necesitamos encontrar un valor de \(k\) que haga que \(\alpha(\delta') =
\alpha_0\), y se rechace \(H_0\) si \(f_1(x)>kf_0(x)
\Leftrightarrow\dfrac{f_0(x)}{f_1(x)}<k^{-1}\).
Tip
Lo que dice el Lema de Neyman-Pearson es que \(\frac{f_{1}(x)}{f_0(x)}\) sería la mejor prueba que se puede encontrar para hipótesis simples.
Ejemplo 11.2 Consideremos el ejemplo donde tenemos una muestra \(X_1,\dots,X_n\) de una distribución normal con media desconocida \(\theta\) y varianza conocida 1. Queremos probar la hipótesis nula \(H_0: \theta = 0\) contra la hipótesis alternativa \(H_1: \theta = 1\) con un nivel de significancia de \(\alpha = 0.05\).
Las funciones de densidad bajo las hipótesis \(H_0\) y \(H_1\) son, respectivamente: \[\begin{align*}
f_0(x) &= (2\pi)^{-n/2}\exp\left[-\dfrac 12 \sum_{i=1}^{n} X_i^2\right]\\
f_1(x) &= (2\pi)^{-n/2}\exp\left[-\dfrac 12 \sum_{i=1}^{n} (X_i-1)^2\right].
\end{align*}\].
Por ejemplo, si \(n=9\), entonces \(\beta(\delta') = \Phi(1.645-3) =0.0877.\)
Ejemplo 11.3 Supongamos que tenemos una muestra \(X_1,\dots,X_n\) de una distribución Bernoulli con probabilidad desconocida \(p\). Tomemos \(n=10\) para concretar los cálculos numéricos. Queremos probar la hipótesis nula \(H_0: p = 0.2\) contra la hipótesis alternativa \(H_1: p = 0.4\) con un nivel de significancia de \(\alpha = 0.05\).
Vamos a usar \(y\) para representar la suma de la muestra: \(y = \sum_{i=1}^{n} X_i\).
Las funciones de masa de probabilidad bajo las hipótesis \(H_0\) y \(H_1\) son:
\[
y>\dfrac{\ln k + n\ln(4/3)}{\ln (8/3)} = k'.
\]
Para encontrar \(k'\), queremos que la probabilidad de obtener un valor de \(Y\) mayor que \(k'\), bajo \(H_0\), sea \(0.05\):
\[
\mathbb P(Y>k'|p = 0.2) = 0.05.
\]
Pero debido a que \(Y\) sigue una distribución binomial (es discreta), no es posible encontrar un valor exacto para \(k'\). Sin embargo, podemos observar que
\[
\mathbb P(Y>4|p=0.2) = 0.0328
\]
\[
\mathbb P(Y>3|p=0.2) = 0.1209.
\]
Por lo tanto, como no podemos alcanzar exactamente \(0.05\) con una variable discreta, elegimos \(Y>4\) como región de rechazo: la prueba resultante tiene nivel \(\alpha(\delta) = 0.0328\), el mayor nivel posible que no supera \(0.05\). Estos valores se verifican directamente con la distribución binomial: