En los capítulos anteriores usamos la prueba \(\chi^2\) de bondad de ajuste, que obliga a agrupar los datos en clases antes de comparar las frecuencias observadas con las esperadas. Ese agrupamiento desperdicia información cuando la variable es continua y la elección de las clases puede cambiar la conclusión. En este capítulo desarrollamos la prueba de Kolmogorov-Smirnov (KS), que compara directamente la función de distribución acumulada sin agrupar, por lo que suele ser más adecuada —y más potente— para datos continuos.
NotaObjetivos de aprendizaje
Al terminar este capítulo podré:
Definir la función de distribución empírica \(F_n\) y explicar por qué es un estimador consistente de la verdadera \(F\).
Comprender por qué, bajo \(H_0\), el estadístico \(D_n^\star\) no depende de la distribución teórica \(F^\star\).
Calcular a mano el estadístico \(D_n^\star\) de la prueba KS de una y de dos muestras, y compararlo con su valor crítico.
Aplicar la prueba KS en R y en Python, e interpretar correctamente el valor-\(p\) y la decisión sobre \(H_0\).
Analizar cuándo conviene KS frente a la prueba \(\chi^2\) y qué supuestos exige (continuidad de \(F\), parámetros no estimados de la misma muestra).
15.1 La función de distribución empírica
Antes de comparar nuestros datos con una distribución teórica necesitamos una forma de resumir la distribución que muestran los datos por sí solos. Esa es la función de distribución empírica: la versión muestral de la función de distribución acumulada.
Supongamos que tenemos una serie de observaciones \(X_1,\dots,X_n\), que siguen una distribución continua \(F\). También asumimos que los valores observados \(x_1,\dots,x_n\) son todos diferentes.
Definición 15.1 Dados los valores observados \(x_1,\dots,x_n\) de la muestra aleatoria \(X_1,\dots, X_n\), para cada \(x\) definimos \(F_n(x)\) como la proporción de valores observados en la muestra que son menores o iguales a \(x\). Es decir, si hay \(k\) valores observados menores o iguales a \(x\), \[
F_n(x) = \frac{k}{n}.
\]
La función \(F_n(x)\) se conoce como la función de distribución de la muestra (empírica). \(F_n\) es una distribución escalonada con saltos de magnitud \(\dfrac 1n\) en los valores \(x_1,\dots,x_n\). Se puede expresar como \[
F_n(x) = \begin{cases}
0 & \text{si } x<X_{(1)}\\
\displaystyle \dfrac 1n \sum_{i=1}^n 1_{\{x_i\leq x\}} & \text{si } X_{(1)}\leq x<X_{(n)}\\
1 & \text{si } x\geq X_{(n)}
\end{cases}
\]
Dado que \(\{x_i\}_{i=1}^n\) son independientes, \(\{1_{\{x_i\leq x\}}\}_{i=1}^n\) también son independientes. Por lo tanto, por la ley de los grandes números
por lo que \(F_n(x)\) es consistente. Esta convergencia es la razón de fondo por la que comparar \(F_n\) con una distribución teórica tiene sentido: si los datos provienen de \(F\), entonces \(F_n\) se parece cada vez más a \(F\) conforme crece la muestra.
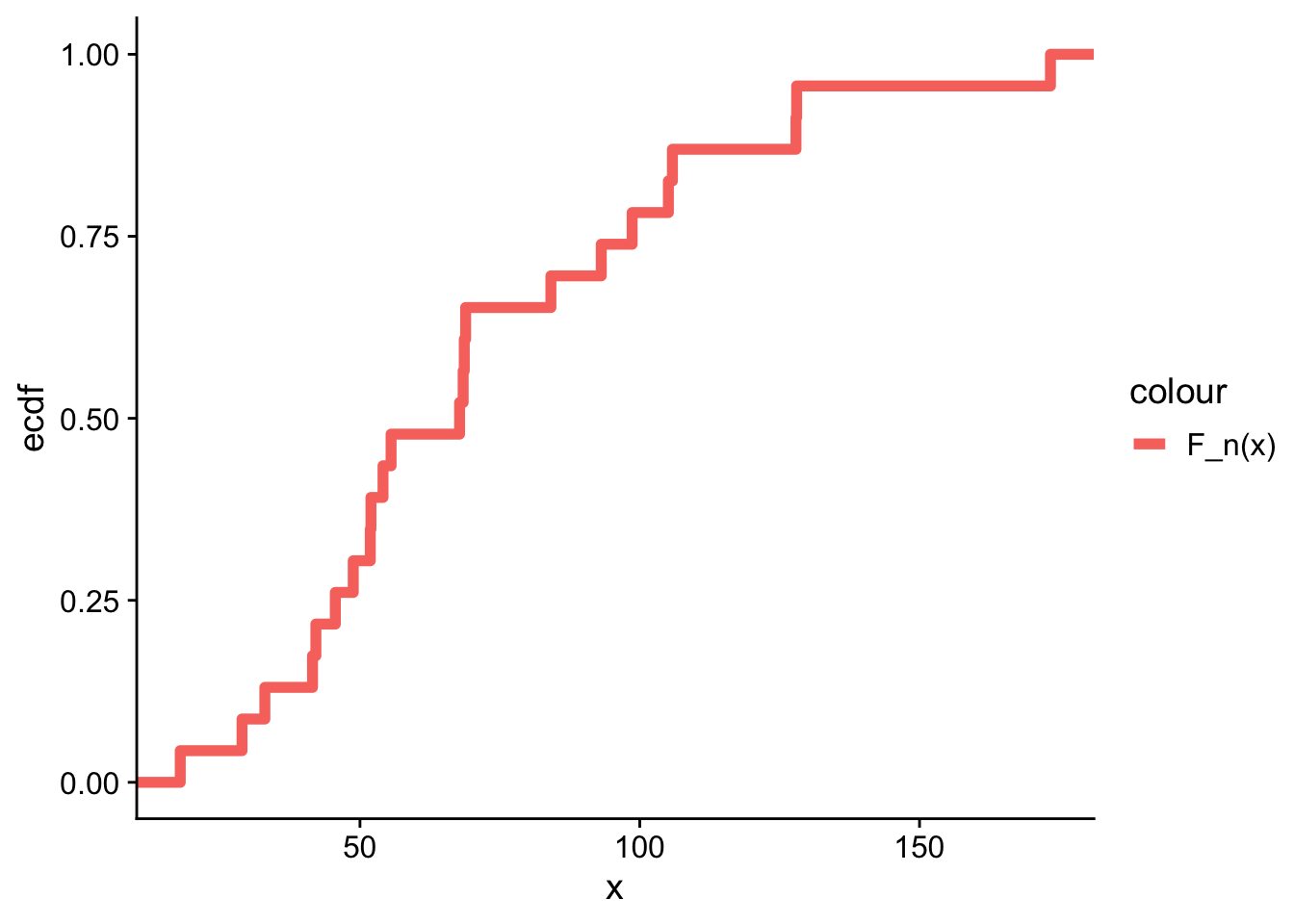
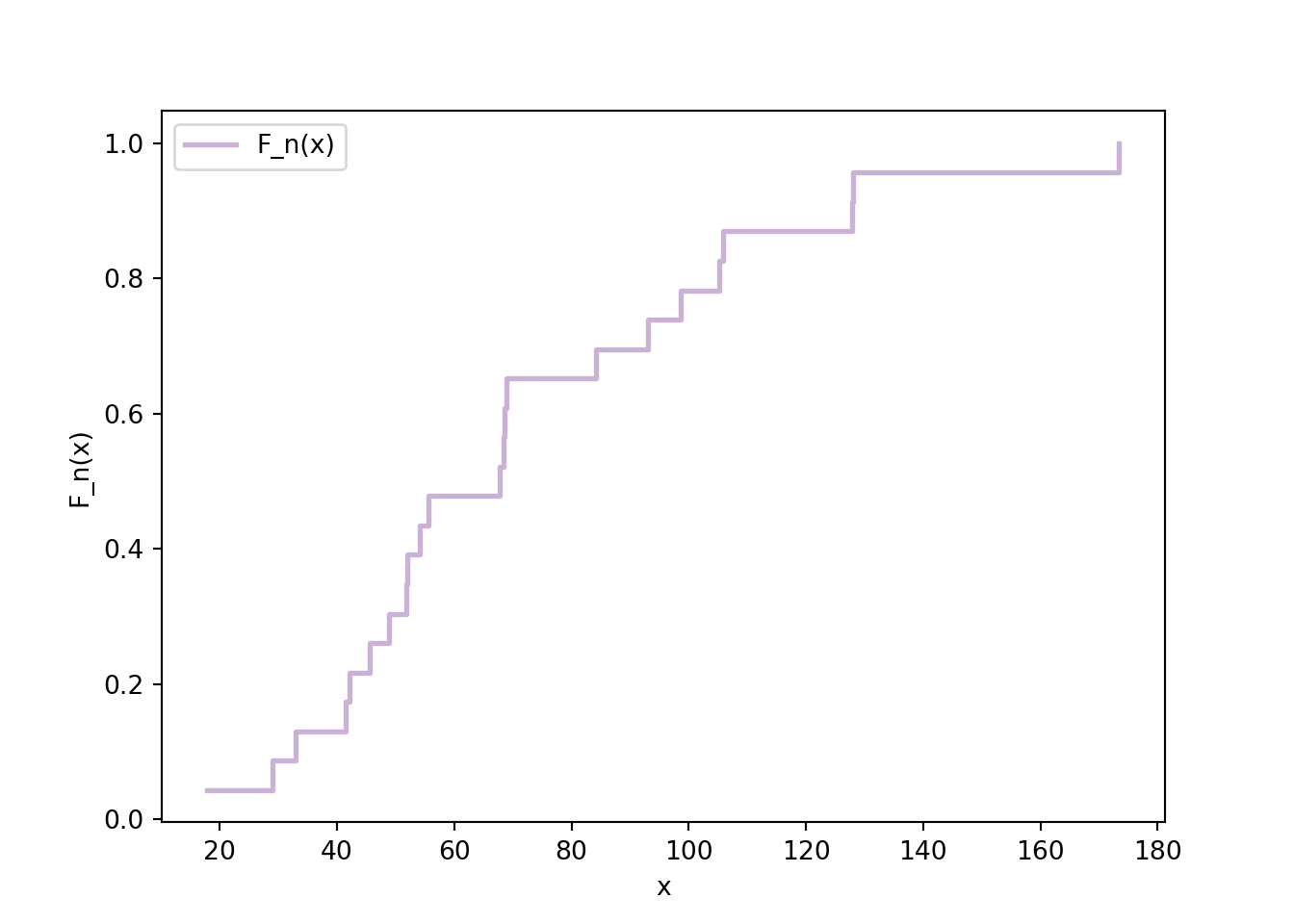
Ejemplo 15.1 Suponga que se tiene el siguiente conjunto de datos:
import matplotlib.pyplot as pltxs = np.sort(x) # valores ordenadosfn = np.arange(1, len(xs) +1) /len(xs) # F_n con saltos de 1/nfig, ax = plt.subplots()ax.step(xs, fn, where="post", color="#cab2d6", linewidth=2, label="F_n(x)")ax.set_xlabel("x"); ax.set_ylabel("F_n(x)"); ax.legend()plt.show()
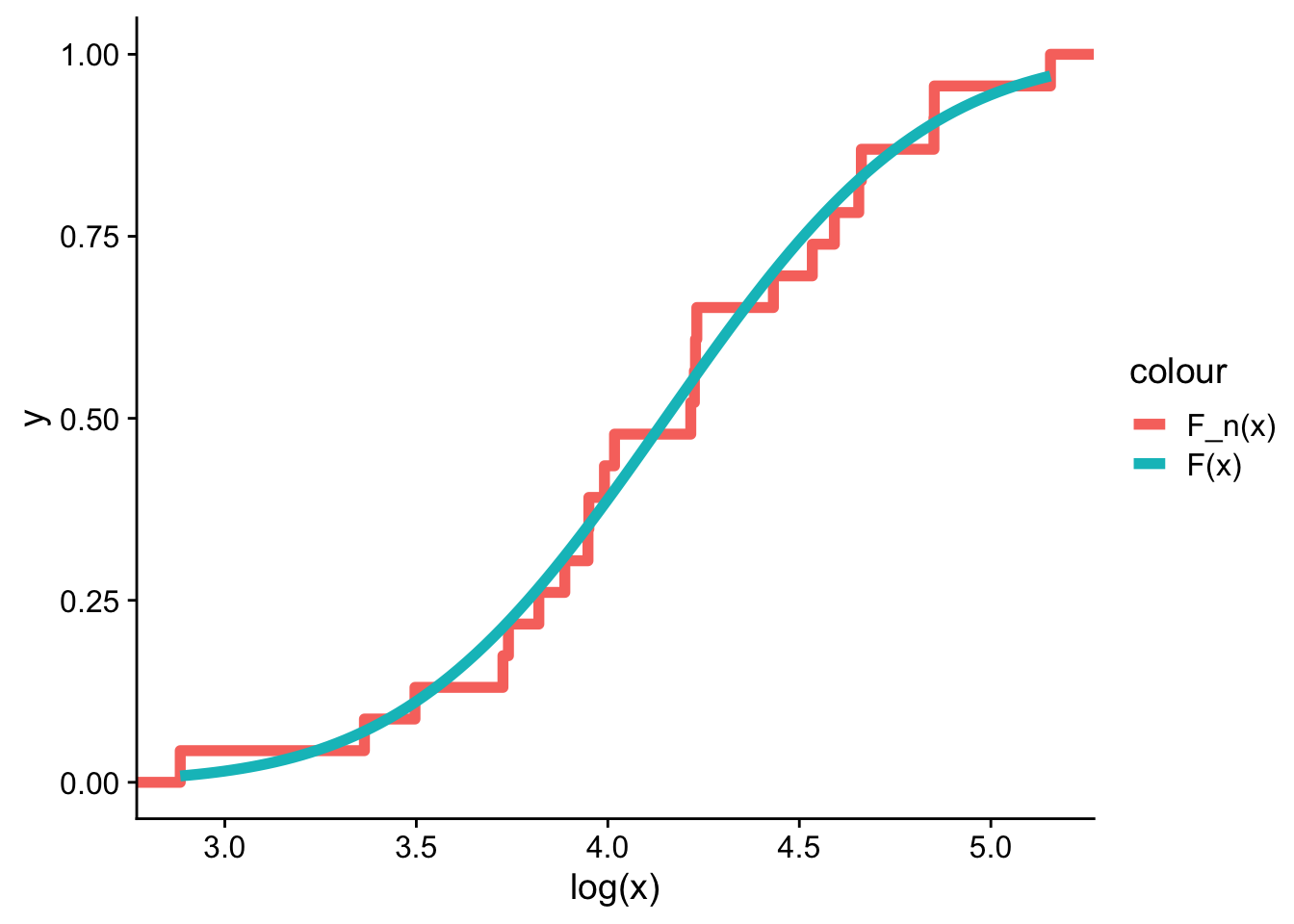
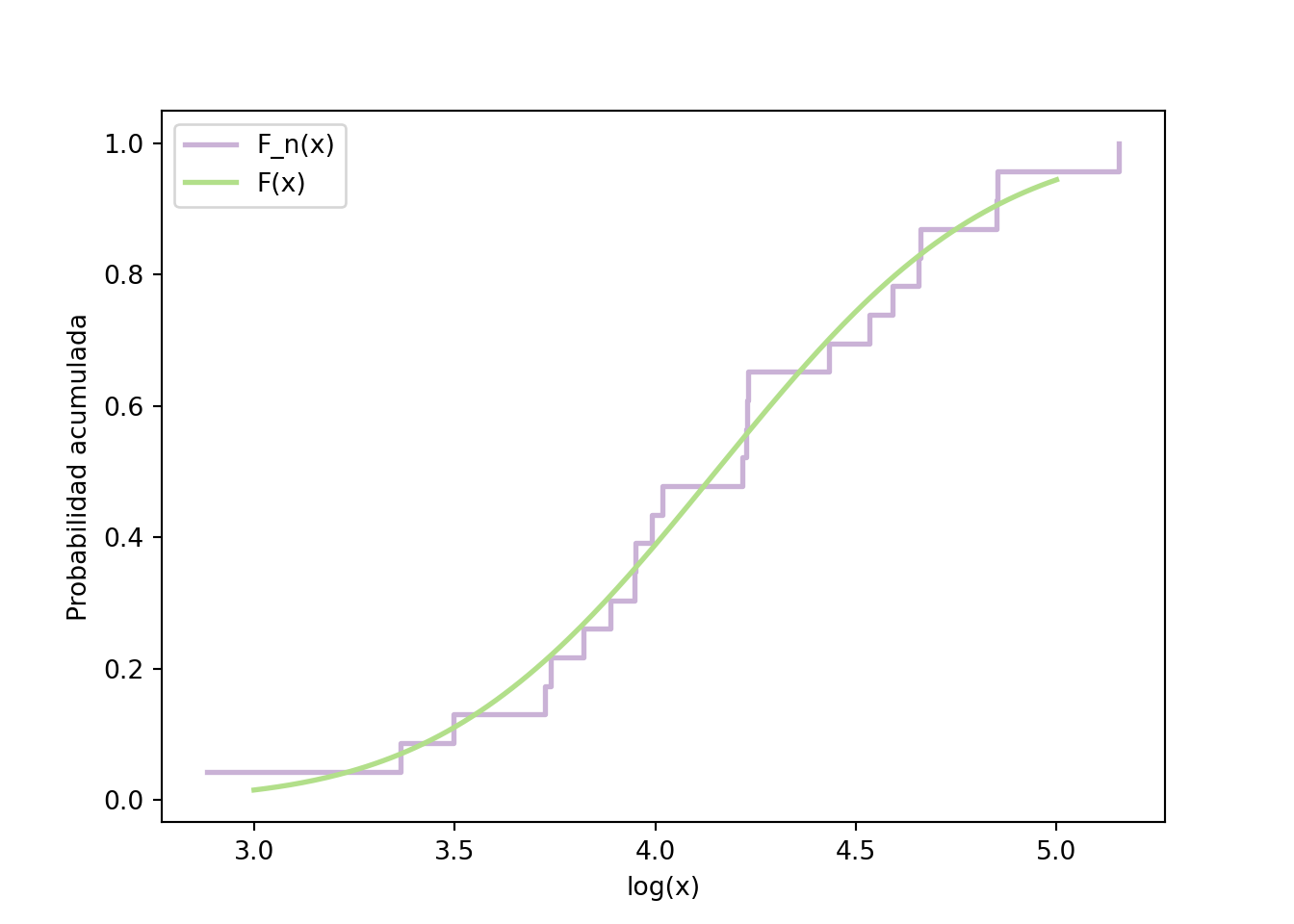
En el capítulo sobre la prueba \(\chi^2\) trabajamos con estos mismos datos y encontramos que sus log-valores se ajustaban bien a una distribución normal. Estimando la media y la varianza directamente de la muestra obtenemos \(\hat\mu = \overline{\log x} \approx 4.151\) y \(s^2 \approx 0.284\) (es decir \(s\approx 0.533\)). Podemos verificar este ajuste superponiendo la normal teórica sobre la distribución empírica:
ggplot() +stat_ecdf(data = df,mapping =aes(log(x), color ="F_n(x)"),linewidth =2 ) +stat_function(data =data.frame(x =c(3, 5)),fun = pnorm,aes(color ="F(x)"),linewidth =2,# parámetros estimados de la propia muestraargs =list(mean =mean(log(x)), sd =sd(log(x))) ) + cowplot::theme_cowplot()
Warning in stat_function(data = data.frame(x = c(3, 5)), fun = pnorm, aes(color = "F(x)"), : All aesthetics have length 1, but the data has 2 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.
La prueba de Kolmogorov-Smirnov se basa en el siguiente teorema, conocido como el Lema de Glivenko-Cantelli.
Lema 15.1 (Glivenko-Cantelli) Sea \(F_n(x)\) la distribución empírica de una muestra \(X_1, \dots, X_n\) provenientes de la distribución \(F\). Defina \[
D_n = \sup_{-\infty<x<\infty}|F_n(x)-F(x)|
\] Entonces \[
D_n\xrightarrow[]{\mathbb P} 0
\]
Esto implica que si una distribución empírica \(F_n(x)\) se obtiene realmente de la distribución teórica \(F(x)\), entonces la diferencia entre estas dos convergerá en probabilidad a 0 cuando $n $. Esta es la idea clave de toda la prueba: la distancia máxima entre \(F_n\) y \(F\) resume en un solo número qué tan lejos están las dos distribuciones, y bajo \(H_0\) esa distancia debe ser pequeña.
La demostración de este teorema está más allá del alcance de este curso, por lo que no se incluirá en esta sección.
TipIdeas clave de esta sección
\(F_n(x)\) es la proporción de datos \(\le x\): una escalera con saltos de \(1/n\).
Por la ley de los grandes números, \(F_n(x)\to F(x)\) para cada \(x\) (consistencia).
Glivenko-Cantelli refuerza esto: la distancia máxima\(D_n=\sup_x|F_n-F|\) tiende a \(0\).
Esa distancia máxima será el estadístico sobre el que se construye la prueba KS.
15.2 Prueba de Kolmogorov-Smirnov para una muestra
Ya sabemos que, si los datos provienen de \(F\), la distancia entre \(F_n\) y \(F\) se hace pequeña. Ahora damos el paso decisivo: convertir esa distancia en una prueba de hipótesis formal que nos diga si una distribución teórica concreta \(F^\star\) es compatible con los datos.
La prueba de Kolmogorov-Smirnov se utiliza para responder a la pregunta de si una distribución empírica de datos, \(F\), es igual a una distribución teórica, \(F^\star\). Se establecen las siguientes hipótesis:
El estadístico de prueba se define como \[
D_n^{\star} = \sup_{-\infty<x<\infty}|F_n(x)-F^{\star}(x)|.
\]
Importante
Si la hipótesis nula es verdadera, entonces la distribución del estadístico \(D_n^{\star}\) no depende de \(F^{\star}\). Esto es lo que permite tabular un único conjunto de valores críticos válido para cualquier distribución teórica continua.
NotaPrueba
Si consideramos \(Z_i = F^{\star}(X_i)\), donde \(i=1,\dots,n\) y \((X_1,\dots,X_n \sim F)\), entonces se puede demostrar que:
Bajo la hipótesis nula, \(Z_1,\dots, Z_n\) se distribuyen como una distribución uniforme entre 0 y 1, es decir, \(Z_1,\dots, Z_n \underset{H_0}{\sim} \text{Unif}(0,1)\).
Si consideramos una nueva hipótesis, \(H_0: G = \text{Unif}(0,1)\), donde \(G\) es la distribución de \(Z_i\), entonces el estadístico de prueba se redefine como:
Se puede demostrar que \(G_n(z) = F_n((F^{\star})^{-1}(z))\), lo que implica que \(D_n^{\star,G}\) es igual a \(D_n^{\star}\) bajo la hipótesis nula. Por lo tanto, \(D_n^{\star}\) no depende de \(F^{\star}\) cuando la hipótesis nula es verdadera.
En términos prácticos, si la distribución empírica \(F_n(x)\) está cerca de la distribución teórica \(F^{\star}(x)\), entonces el valor de \(D_n^{\star}\) será cercano a cero. Por lo tanto, rechazamos la hipótesis nula, \(H_0\), si \(n^{\frac{1}{2}}D_n^{\star}\geq c\) para algún valor crítico \(c\).
Este valor crítico \(c\) se obtiene a partir de la distribución de Kolmogorov-Smirnov. De acuerdo con el teorema de Kolmogorov-Smirnov (1930), si la hipótesis nula es verdadera, para \(t>0\),
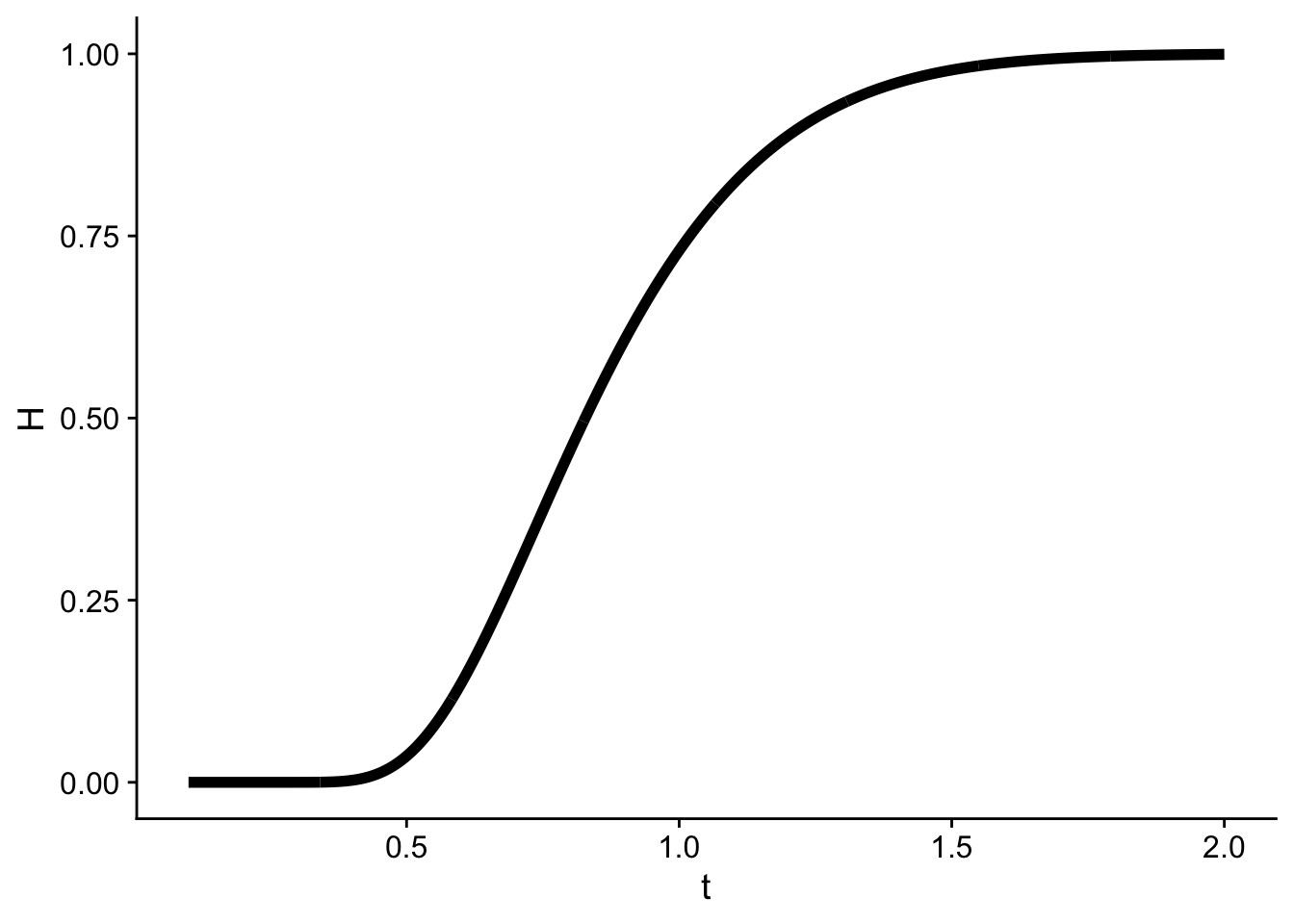
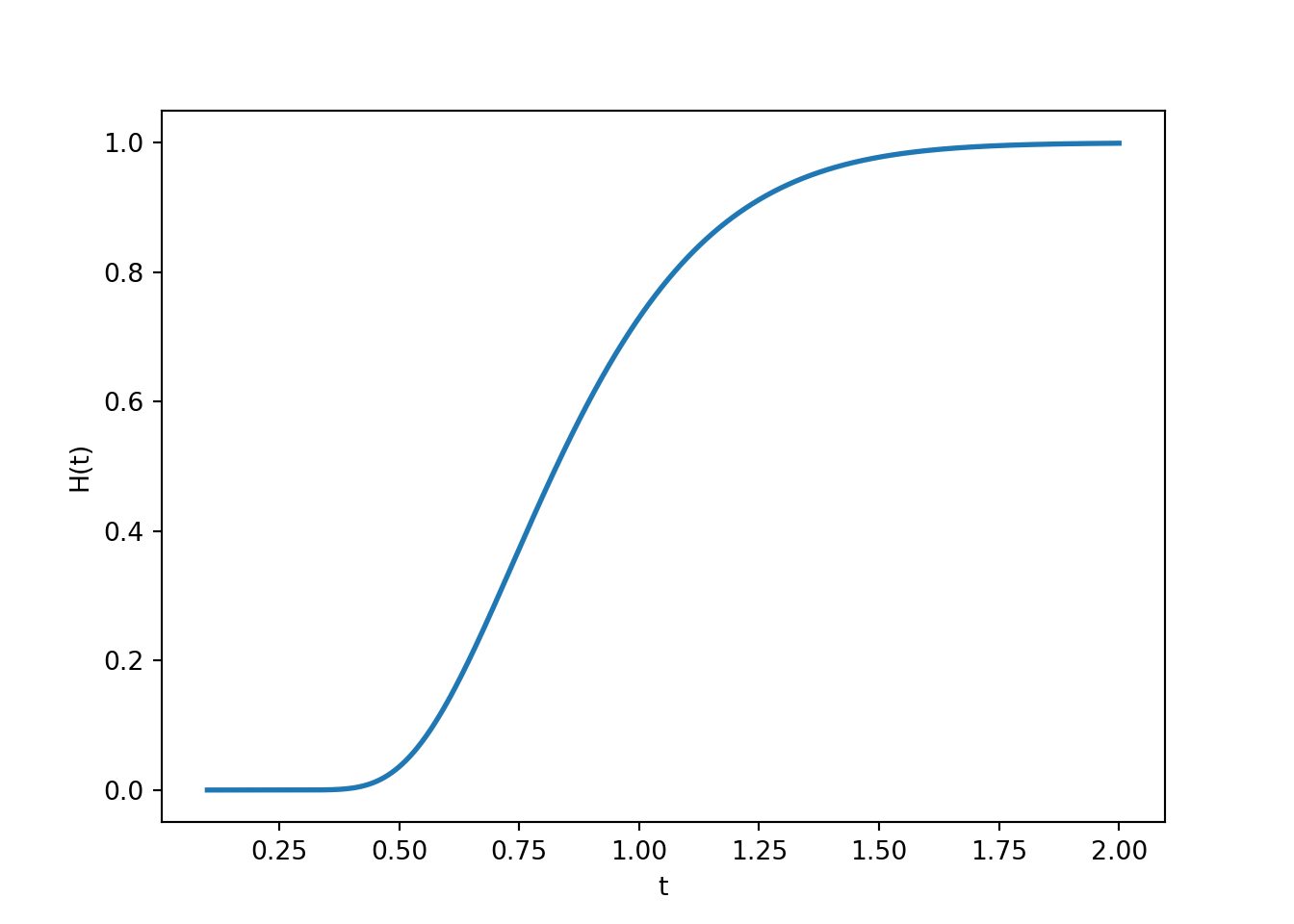
Teorema 15.1 (Kolmogorov-Smirnov (1930)) Si \(H_0\) es cierto, para \(t>0\), \[
\lim_{n\to \infty} \mathbb P(n^{1/2}D_n^{\star}\leq t) = 1-2\sum_{i=1}^\infty
(-1)^{i-1}e^{-2i^2t^2} = H(t).
\]
Rechazamos \(H_0\) si \(n^{1/2}D_n^{\star}\geq c\), \(n\) grande. Para un nivel de significancia \(\alpha_0\), \(c = H^{-1}(1-\alpha_0)\), donde \(H\) denota el valor de la parte derecha de la ecuación anterior.
El siguiente diagrama resume el procedimiento completo de la prueba para una muestra:
La función \(H(t)\) es algo complicada de estimar, y sus cuantiles lo son aún más. Estos normalmente son definidos a través de métodos núméricos que están fuera del alcance del este curso. La siguiente tabla muestra el conjunto de valores estimados para cada \(t\)
La función de distribución se ve de la siguiente forma:
H <-function(t) { i <-1:1e41-2*sum((-1)^(i -1) *exp(-2* i^2* t^2))}t <-seq(0.1, 2, length.out =1000)data.frame(t, H =Vectorize(H)(t)) %>%ggplot(aes(t, H)) +geom_line(linewidth =2) + cowplot::theme_cowplot()
Código
def H(t, terms=10000): i = np.arange(1, terms +1)return1-2* np.sum((-1)**(i -1) * np.exp(-2* i**2* t**2))t = np.linspace(0.1, 2, 1000)Hvals = np.array([H(ti) for ti in t])fig, ax = plt.subplots()ax.plot(t, Hvals, linewidth=2)ax.set_xlabel("t"); ax.set_ylabel("H(t)")plt.show()
Los valores más comunes de cuantiles para las pruebas son
\(\alpha\)
\(H^{-1}(1-\alpha)\)
0.01
1.63
0.05
1.36
0.1
1.22
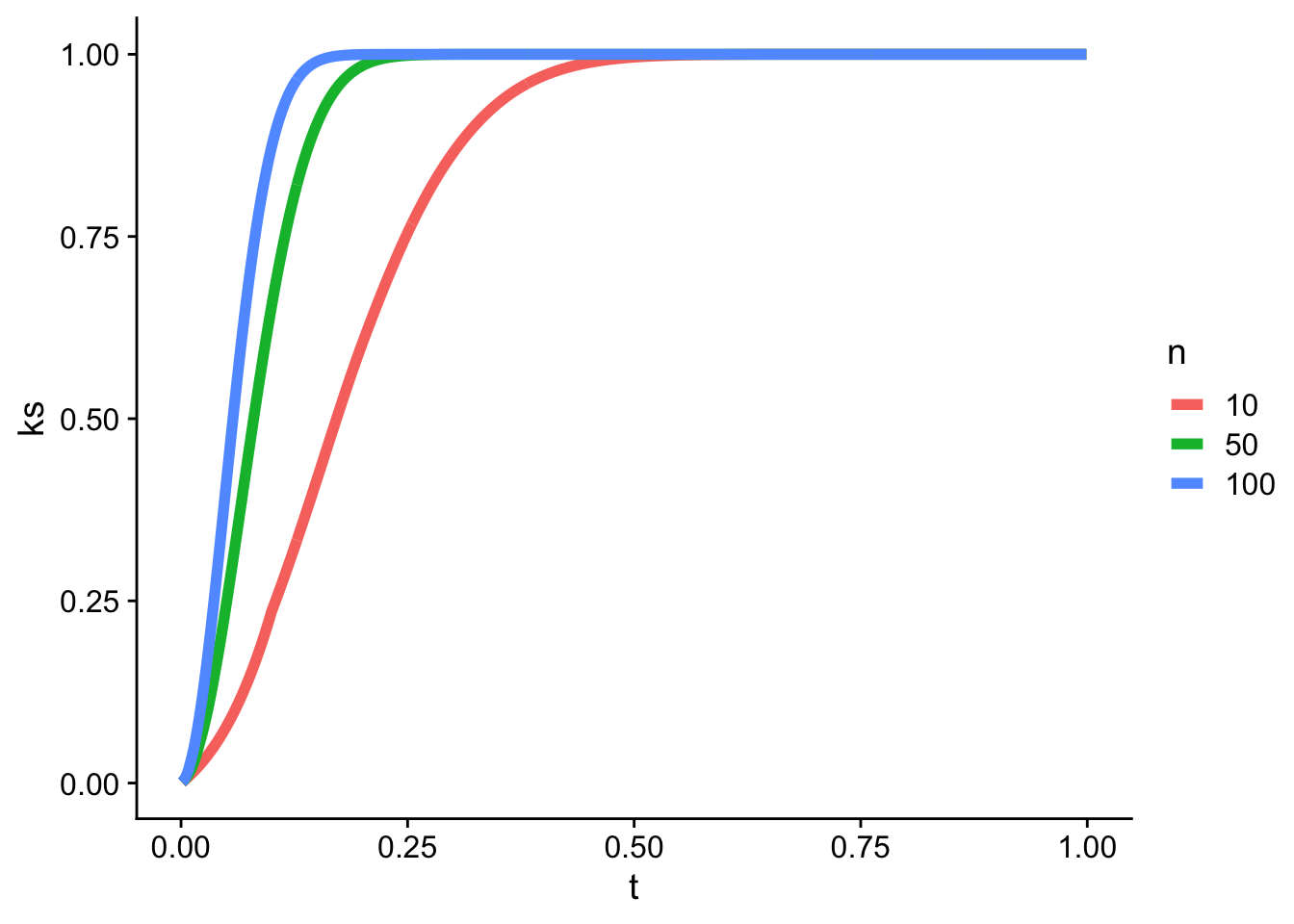
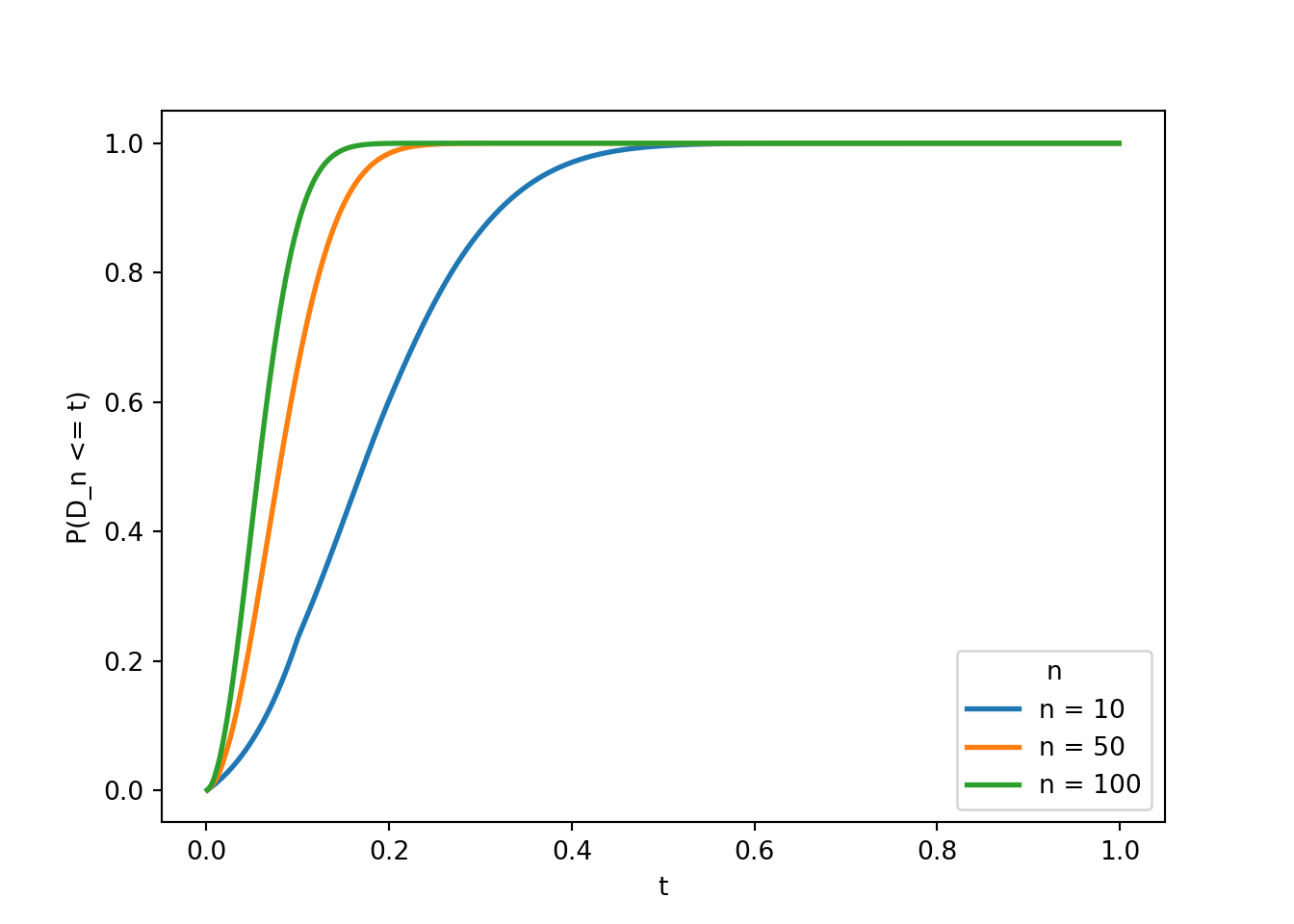
Solo como ilustración, la funcion ks.test tiene programada la estimación de \(\mathbb P (D_n \leq t)\). En este gráfico se presentan algunos ejemplos con \(n\) igual a 10, 50 y 100.
pkolmogorov1x <-function(x, n) {## Probability function for the one-sided one-sample Kolmogorov## statistics, based on the formula of Birnbaum & Tingey (1951).if (x <=0) {return(0) }if (x >=1) {return(1) } j <-seq.int(from =0, to =floor(n * (1- x)))1- x *sum(exp(lchoose(n, j) + (n - j) *log(1- x - j / n) + (j -1) *log(x + j / n) ) )}t <-seq(0.001, 0.999, length.out =1000)df <-rbind(data.frame(t, ks =Vectorize(pkolmogorov1x)(t, 10), n =10),data.frame(t, ks =Vectorize(pkolmogorov1x)(t, 50), n =50),data.frame(t, ks =Vectorize(pkolmogorov1x)(t, 100), n =100))
Código
ggplot(df, aes(x = t, y = ks, color =as.factor(n))) +geom_line(linewidth =2) +labs(color ="n") + cowplot::theme_cowplot()
Código
from scipy.special import gammalndef pkolmogorov1x(xv, n):# Birnbaum & Tingey (1951): P(D_n <= x) exacto para una colaif xv <=0:return0.0if xv >=1:return1.0 j = np.arange(0, np.floor(n * (1- xv)) +1) lchoose = gammaln(n +1) - gammaln(j +1) - gammaln(n - j +1)return1- xv * np.sum(np.exp( lchoose + (n - j) * np.log(1- xv - j / n) + (j -1) * np.log(xv + j / n) ))t = np.linspace(0.001, 0.999, 1000)fig, ax = plt.subplots()for nn in (10, 50, 100): ax.plot(t, [pkolmogorov1x(ti, nn) for ti in t], linewidth=2, label=f"n = {nn}")ax.set_xlabel("t"); ax.set_ylabel("P(D_n <= t)"); ax.legend(title="n")plt.show()
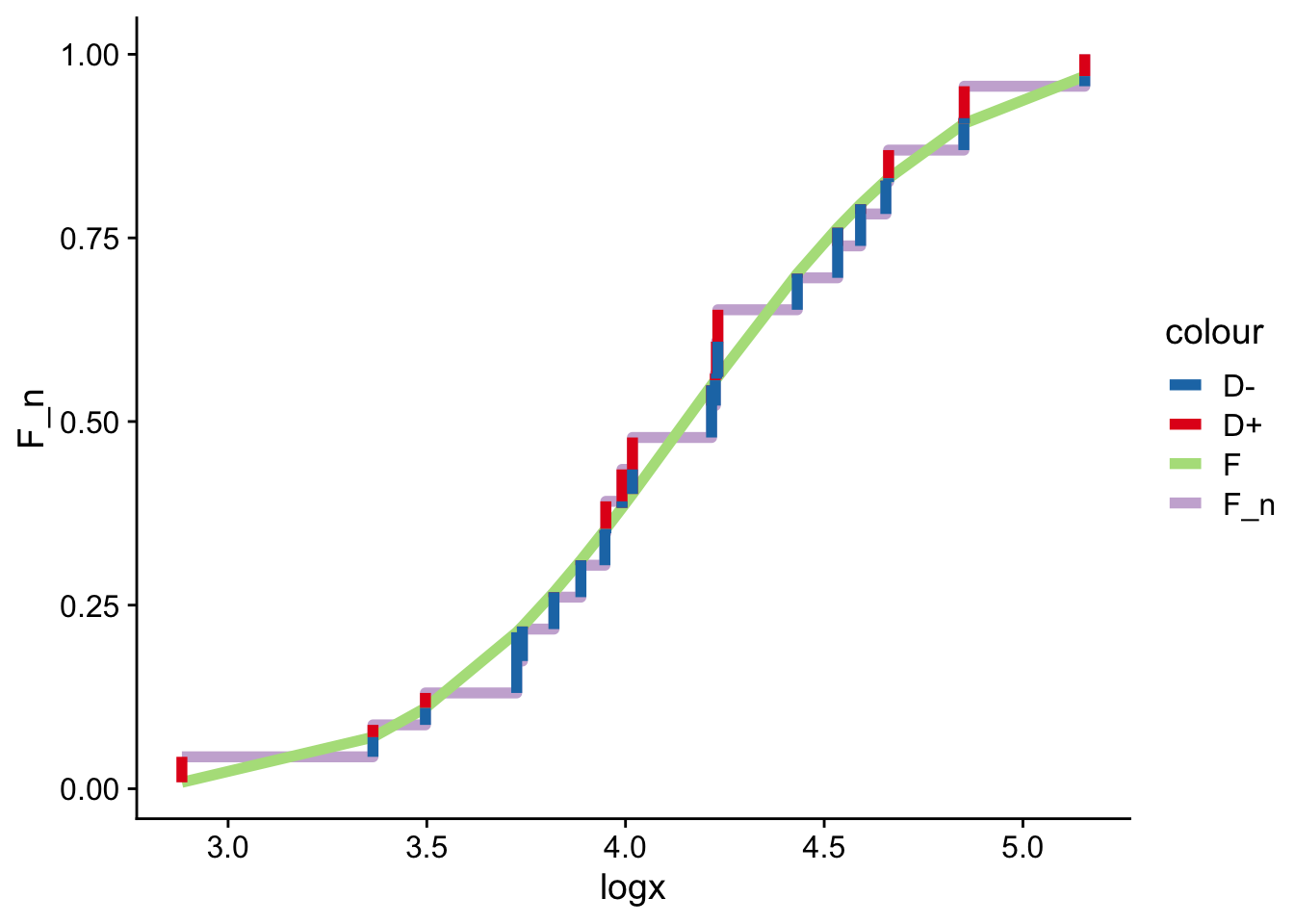
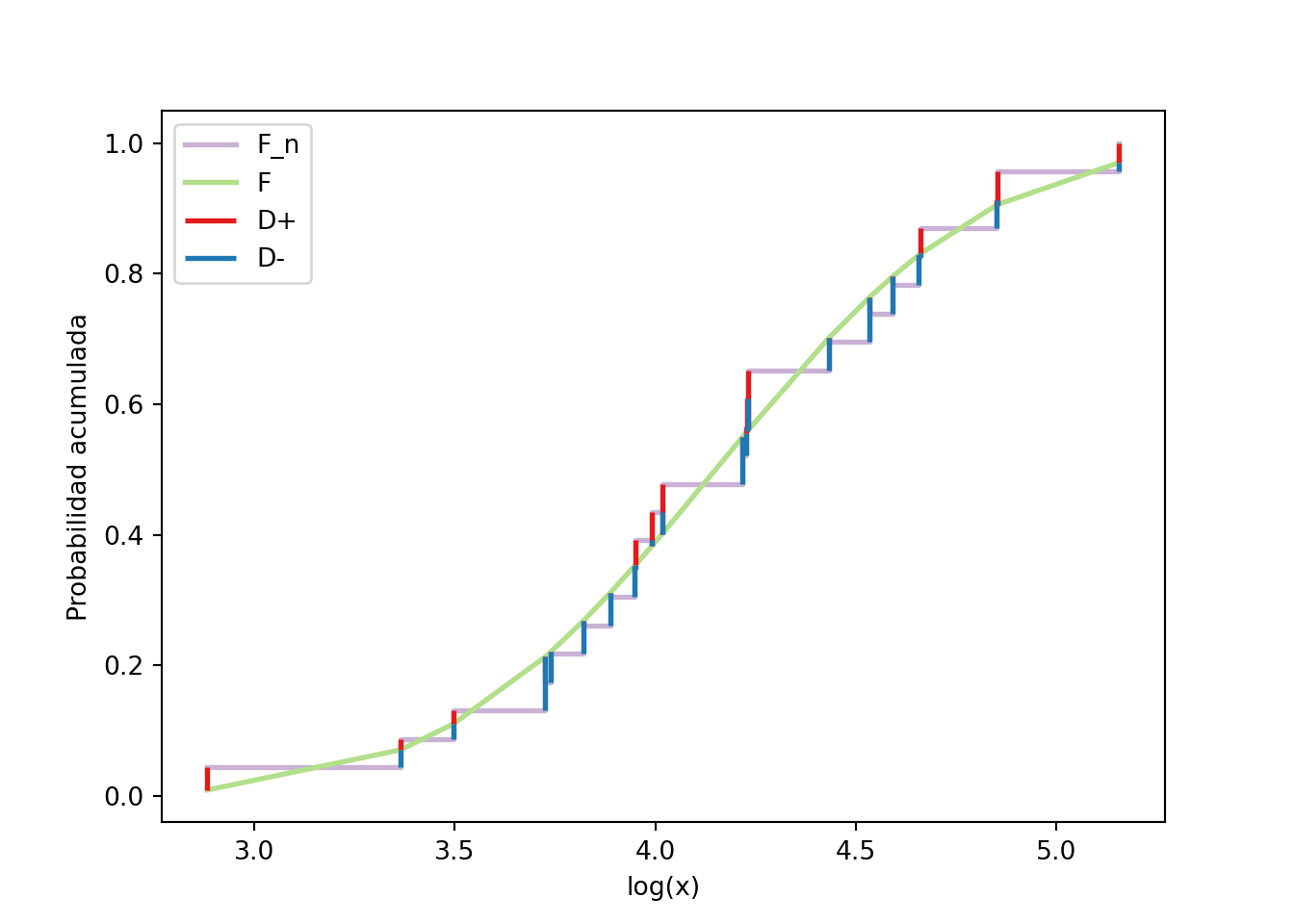
Ejemplo 15.2 En el caso de las partes mecánicas quisiéramos saber si los log-valores siguen o no una distribución normal de parámetros \(N (\hat{\mu } , s^{2})\).
Para calcular manualmente el valor de \(D_{n}^{\star }\) se deben usar los siguientes dos estimadores:
Como \(\sqrt{n}\,D_n^\star\approx 0.44 < 1.36\), no rechazamos\(H_0\): no hay evidencia contra la hipótesis de que los log-valores sigan la normal estimada. El valor-\(p\) asociado, \(1-H(\sqrt{n}\,D_n^\star)\), es cercano a \(1\):
One-sample Kolmogorov-Smirnov test
data: log(x)
D = 0.091246, p-value = 0.9815
alternative hypothesis: two-sided
Observación. Los valores de los valores-p son diferentes ya que la función ks.test usa varias aproximaciones para calcularlos.
Importante
En este ejemplo estimamos \(\mu\) y \(\sigma\)de la misma muestra que luego probamos. Cuando esto ocurre, la distribución \(H(t)\) deja de ser exacta y la prueba KS se vuelve conservadora: tiende a no rechazar (valor-\(p\) inflado). Para corregirlo se usa la prueba de Lilliefors o rutinas como KSgeneral::cont_ks_test, no el ks.test estándar. El KS clásico es exacto solo cuando \(F^\star\) está completamente especificada antes de ver los datos.
Note que esta localización es muy importante ya que si se quisiera comparar con una distribución \(N(0,1)\) el resultado es diferente.
El estadístico KS es la distancia vertical máxima entre \(F_n\) y \(F^\star\): \(D_n^\star=\max\{D_n^+, D_n^-\}\).
Se rechaza \(H_0\) si \(\sqrt{n}\,D_n^\star \ge c\), con \(c=H^{-1}(1-\alpha)\) (p. ej. \(1.36\) para \(\alpha=0.05\)).
La distribución de referencia \(H(t)\) es universal: no depende de \(F^\star\).
Si los parámetros se estiman de los datos, usar Lilliefors / KSgeneral, no el KS clásico.
15.3 Prueba de 2 muestras
Hasta aquí comparamos una muestra contra una distribución teórica conocida. A menudo, sin embargo, no tenemos una \(F^\star\) de referencia sino dos muestras y queremos saber si provienen de la misma población. La prueba KS se extiende de forma natural a este caso.
Suponga que se tiene \(X_1,\dots,X_m\sim N(\mu_1,\sigma^2)\) y \(Y_1,\dots,Y_n\sim N(\mu_2,\sigma^2)\) y se desea saber si ambas muestras tienen la misma distribución.
Una opción es probar que \[
H_0:\mu_1 = \mu_2 \text{ vs } H_1: \mu_{1} \neq \mu_{2}
\]
Uno de los supuestos fuertes para este tipo de pruebas es la normalidad.
En este caso se rechaza la hipótesis nula si \(\left(\dfrac{mn}{m+n}\right)^{\frac 12}D_{mn}^{\star} \geq c(\alpha)\), donde \(c(\alpha) =\sqrt{-\frac{1}{2}\ln\left(\frac{\alpha}{2}\right)}\).
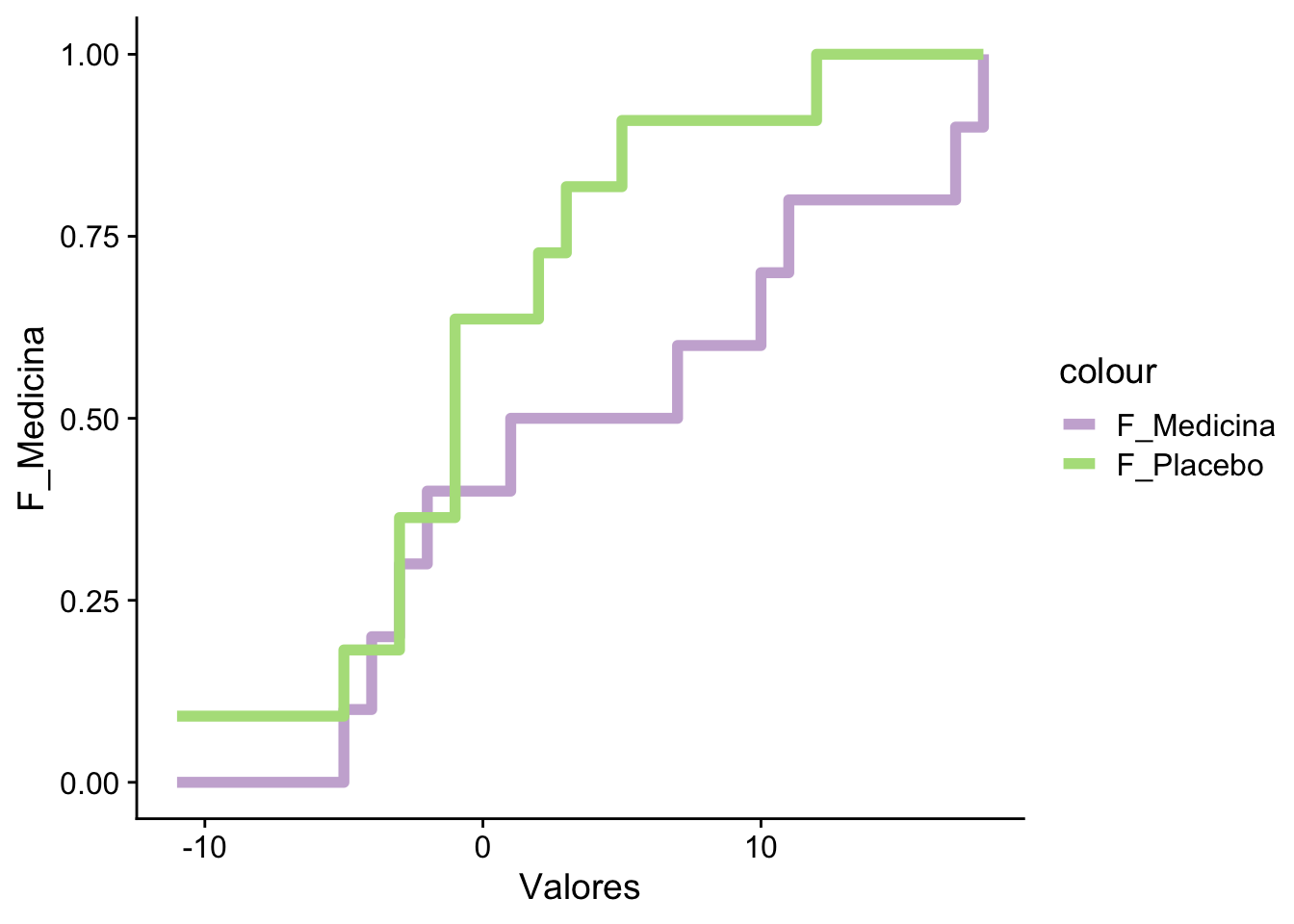
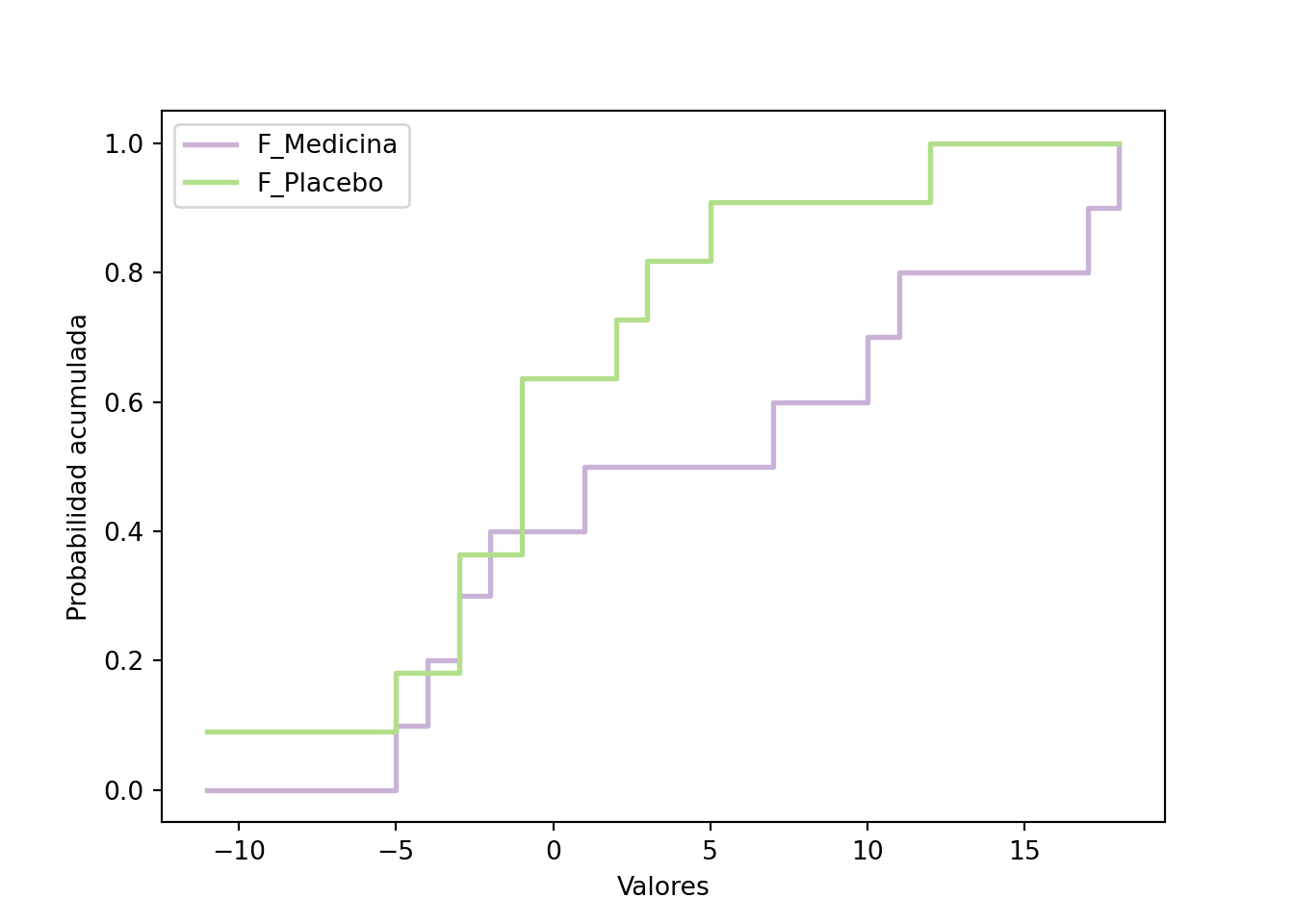
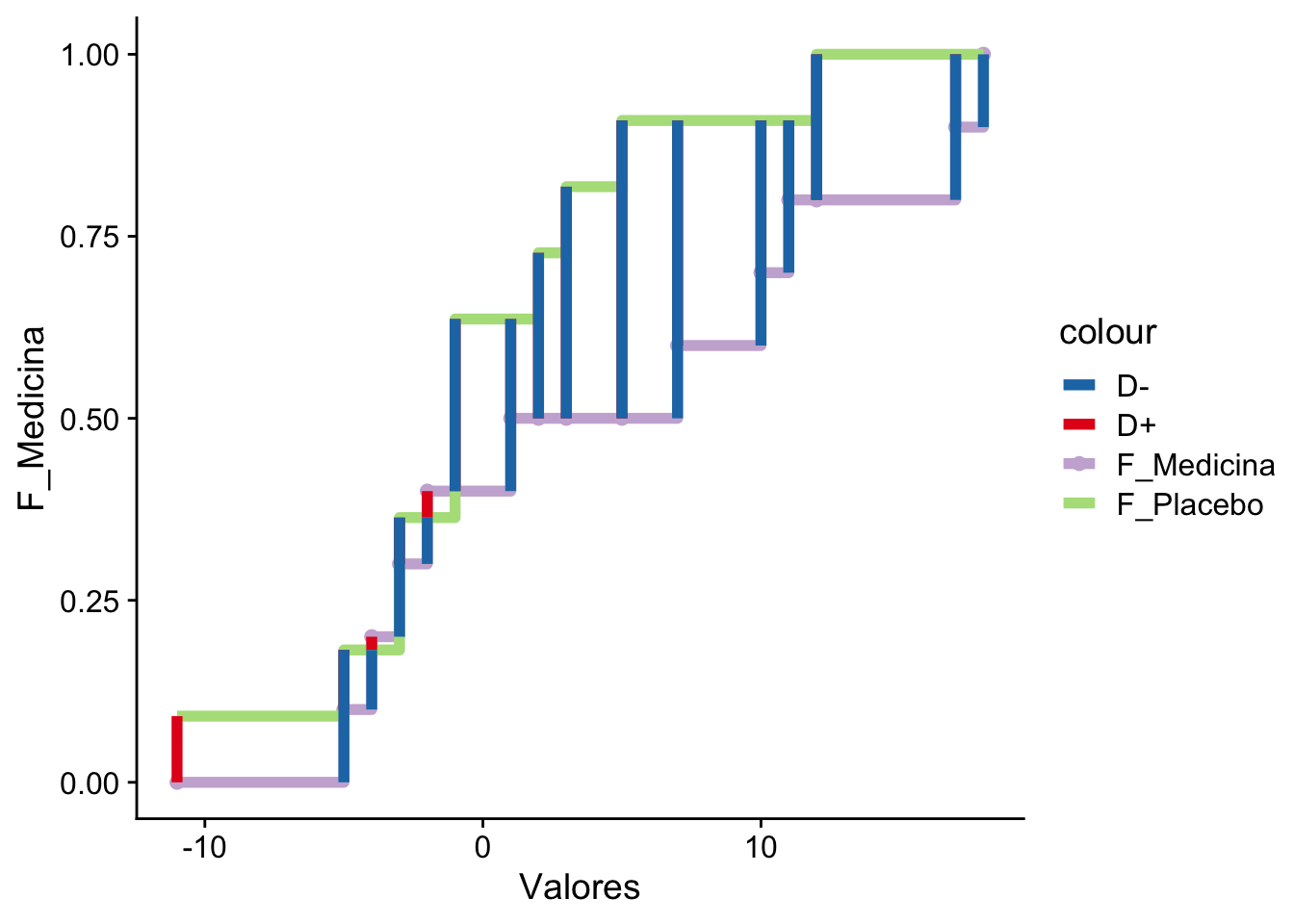
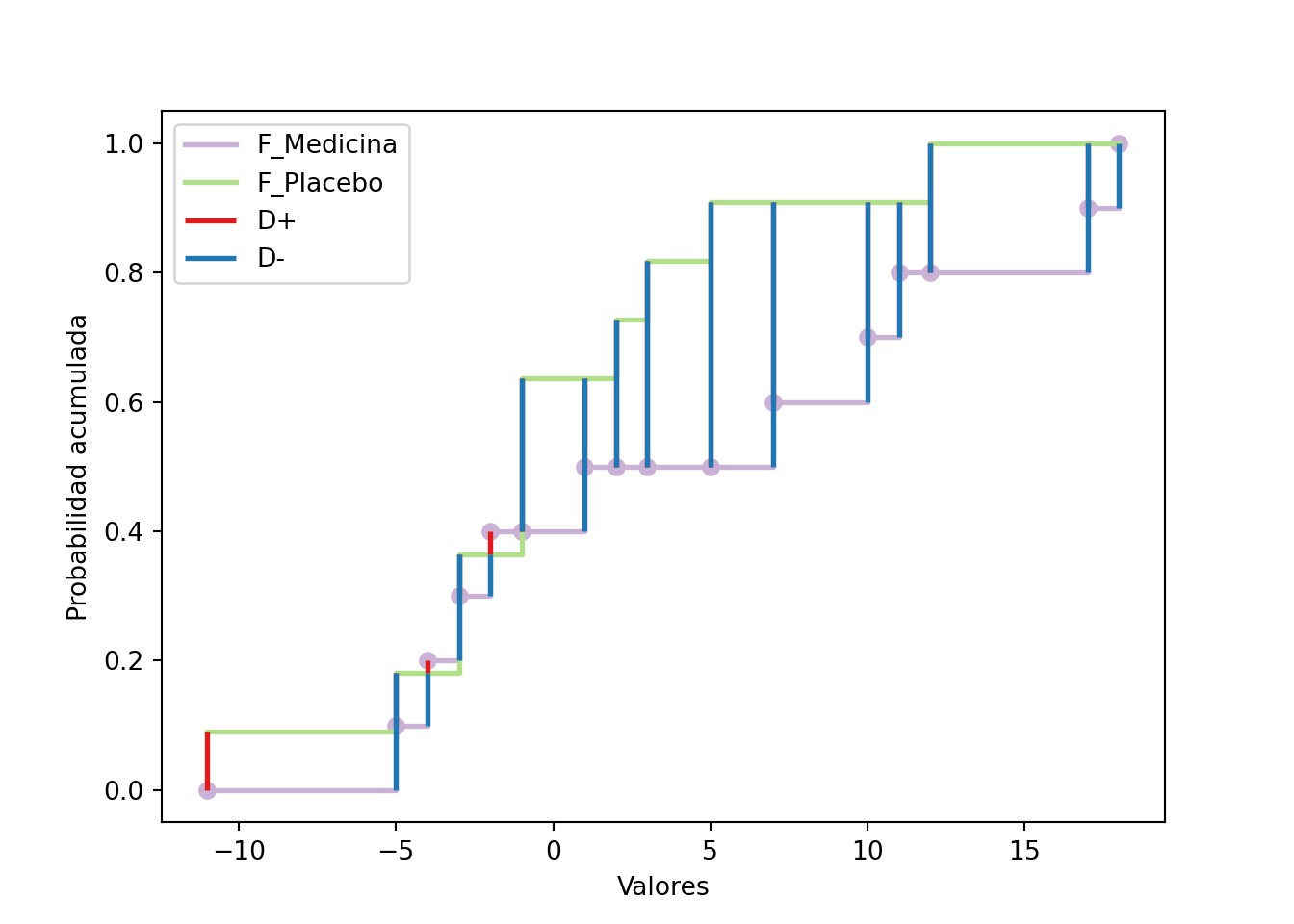
Ejemplo 15.3 Suponga que se tienen dos grupos de personas a las cuales a unas se les dio un tratamiento para la presión arterial y al otro se le dio un placebo.
Al se midieron las diferencias entre las presiones arteriales al cabo de 12 semanas de tratamiento.
La pregunta es si ambos conjuntos de datos vienen de la misma distribución.
Podemos repetir el mismo procedimiento anterior, pero modificado para dos muestras. Primero necesitamos estimar el \(D_{nm}^{\star}\) usando estos dos estimadores:
En este caso no rechazamos la hipótesis nula de que ambas distribuciones son iguales: el estadístico \(\left(\tfrac{mn}{m+n}\right)^{1/2}D_{mn}^{\star}\approx 0.936\) no supera el valor crítico \(c(0.05)\approx 1.358\). El valor-\(p\) asintótico (\(1-H\approx 0.345\)) y el exacto que reporta ks.test (\(p\approx 0.242\)) son ambos muy superiores a \(0.05\), de modo que solo rechazaríamos con un nivel \(\alpha\) inusualmente alto. Note que el estadístico es el mismo en ambos métodos (\(\sqrt{mn/(m+n)}\,D_{mn}^{\star}\approx 0.936\)); lo que difiere es la distribución de referencia contra la que se evalúa, y por eso el valor-\(p\) cambia:
El cálculo manual \(1-H\approx 0.345\) usa la distribución límite de Kolmogorov \(H(t)\), que es una aproximación asintótica válida cuando \(m,n\to\infty\).
ks.test usa la distribución exacta para los tamaños concretos \(m=11\), \(n=10\), contando combinatoriamente todas las formas de intercalar las dos muestras; por eso reporta \(p\approx 0.242\).
Como las muestras son pequeñas, la aproximación asintótica está lejos del valor exacto (lo sobreestima). A medida que \(m,n\) crecen, ambos valores convergen.
TipIdeas clave de esta sección
La versión de dos muestras compara dos distribuciones empíricas: \(D_{mn}^\star=\sup_x|F_m(x)-G_n(x)|\).
El estadístico se reescala con \(\sqrt{mn/(m+n)}\) y se compara con \(c(\alpha)=\sqrt{-\tfrac12\ln(\alpha/2)}\).
No exige normalidad ni igualdad de varianzas: detecta cualquier diferencia entre las dos distribuciones.
Para muestras pequeñas, ks.test usa la distribución exacta; \(1-H\) es solo la aproximación asintótica.
15.4 Resumen
La prueba de Kolmogorov-Smirnov compara distribuciones acumuladas mediante la distancia vertical máxima, sin agrupar los datos en clases. La siguiente tabla reúne los resultados principales del capítulo.
Caso
Estadístico
Reescalado
Se rechaza \(H_0\) si
Valor crítico
Una muestra
\(D_n^\star=\max\{D_n^+,D_n^-\}\)
\(\sqrt{n}\,D_n^\star\)
\(\sqrt{n}\,D_n^\star \ge c\)
\(c=H^{-1}(1-\alpha)\) (p. ej. \(1.36\) a \(\alpha=0.05\))
donde \(H(t)=1-2\sum_{i=1}^\infty(-1)^{i-1}e^{-2i^2t^2}\) es la distribución límite de Kolmogorov, común a ambos casos.
TipPara recordar
KS no requiere agrupar en clases: aprovecha toda la información de los datos continuos, por lo que suele superar a \(\chi^2\) en ese contexto.
Bajo \(H_0\), la distribución del estadístico es universal (no depende de \(F^\star\)): por eso basta una sola tabla de valores críticos.
En la prueba de una muestra, \(F^\star\) debe estar completamente especificada; si se estiman parámetros de la misma muestra, usar Lilliefors / KSgeneral.
La prueba de dos muestras es no paramétrica: detecta diferencias en forma, posición o escala sin suponer normalidad.