Código
x <- rexp(n = 100, rate = 1)
n <- length(x)
y <- sum(x)
theta <- seq(0.5, 1.5, length.out = 1000)Al finalizar este capítulo, podré:
En el capítulo anterior, nos enfocamos en construir una distribución posterior a partir de una distribución previa. Sin embargo, surge una pregunta:
¿Es posible estimar la distribución posterior sin una densidad previa?
Para responderla, primero debemos revisar algunas definiciones relacionadas con la muestra y la independencia condicional al valor de un parámetro.
Cuando observamos datos, queremos encontrar el valor del parámetro \(\theta\) que hace que esos datos sean lo más “plausibles” posible. La función de verosimilitud cuantifica exactamente esa plausibilidad: dado un parámetro candidato \(\theta\), ¿qué tan probable habría sido observar nuestra muestra? El MLE elige el \(\theta\) que maximiza esa probabilidad.
Definición 5.1 (Función de verosimilitud) Dada una muestra \(X_1, \dots , X_n\) que son variables aleatorias independientes e idénticamente distribuidas (i.i.d.) con distribución \(f(X\mid \theta)\) y un \(\theta\) fijo, la función de verosimilitud se define como:
\[ f_n (X\mid \theta) = \prod_{i=1}^n f(X_i\mid \theta) = L(\theta\mid X). \]
Si consideramos dos valores posibles del parámetro, \(\theta_1\) y \(\theta_2\), y evaluamos la función de verosimilitud para cada uno de ellos, obtenemos: \[\begin{align*} f_n(X\mid \theta_1) &= \prod_{i=1}^n f(X_i\mid \theta_1) = L(\theta_1\mid X) \\ f_n(X\mid \theta_2) &= \prod_{i=1}^n f(X_i\mid \theta_2) = L(\theta_2\mid X) \end{align*}\]
El principio de verosimilitud establece que si \(f_n(X\mid \theta_1)>f_n(X\mid \theta_2)\), entonces \(L(\theta_1\mid X)>L(\theta_2\mid X)\).
Observación. Es más verosímil (realista) que el verdadero valor del parámetro sea \(\theta_1\) que \(\theta_2\) dada la muestra observada.
Definición 5.2 (Estimador de máxima verosimilitud (MLE)) Para cada observación \(x\) en el espacio muestral \(X\), si existe un estimador \(\delta(x)\) de \(\theta\) que maximiza la función de verosimilitud \(f_n(x\mid \theta)\), entonces a \(\delta(x)\) se le denomina estimador de máxima verosimilitud (MLE).
Ejemplo 5.1 Consideremos una muestra \(X_1,\dots, X_n\) con distribución exponencial \(\text{Exp}(\theta)\), donde la función de densidad es \(\frac{1}{\theta} e^{-\frac{x}{\theta}}\) si \(x>0\). Estamos interesados en estimar \(\theta\).
La función de verosimilitud es:
\[\begin{equation*} f_n(X\mid \theta) = \frac{1}{\theta^n}\exp\left({-\frac{\sum_{i=1}^n x_i}{\theta}}\right) = \theta^{-n} \exp\left({-\frac{y}{\theta}}\right) . \end{equation*}\]
Donde \(y = \sum_{i=1}^n x_i\).
La log-verosimilitud es una transformación monótona creciente de la función de verosimilitud y se define como:
\[\begin{equation*} \ell(\theta\mid X) = \ln f_n(X\mid \theta) = -n\ln \theta - \frac{y}{\theta}. \end{equation*}\]
Para encontrar el MLE de \(\theta\), derivamos la log-verosimilitud con respecto a \(\theta\) y resolvemos para \(\theta\):
\[\begin{align*} \frac{\partial}{\partial\theta} \ell(\theta\mid X) &= \frac{\partial}{\partial\theta} \left[ -n\ln \theta - \frac{y}{\theta} \right] = -\frac{n}{\theta} + \frac{y}{\theta^2} = 0 \\ \implies \frac{1}{\theta}\left(-n + \frac{y}{\theta}\right) &= 0 \\ \implies \hat\theta = \frac{y}{n} &= \bar{X}_n. \end{align*}\]
Para verificar que \(\hat\theta\) es un máximo, derivamos la log-verosimilitud con respecto a \(\theta\) dos veces y evaluamos en \(\theta = \hat\theta\):
\[\begin{align*} \frac{\partial^2}{\partial\theta^2} \ell(\theta\mid X) &= \left. \frac{n}{\theta^2} - \frac{2y}{\theta^3}\right|_{\theta=\frac{y}{n}} \\ &= \frac{n}{\left(\frac{y}{n}\right)^2} - \frac{2y}{\left(\frac{y}{n}\right)^3} \\ &= \frac{n^3}{y^2} - \frac{2n^3}{y^2} \\ &= -\frac{n^3}{y^2} < 0. \end{align*}\]
Por lo tanto \(\hat\theta = \bar{X}_n\) es el MLE de \(\theta\).
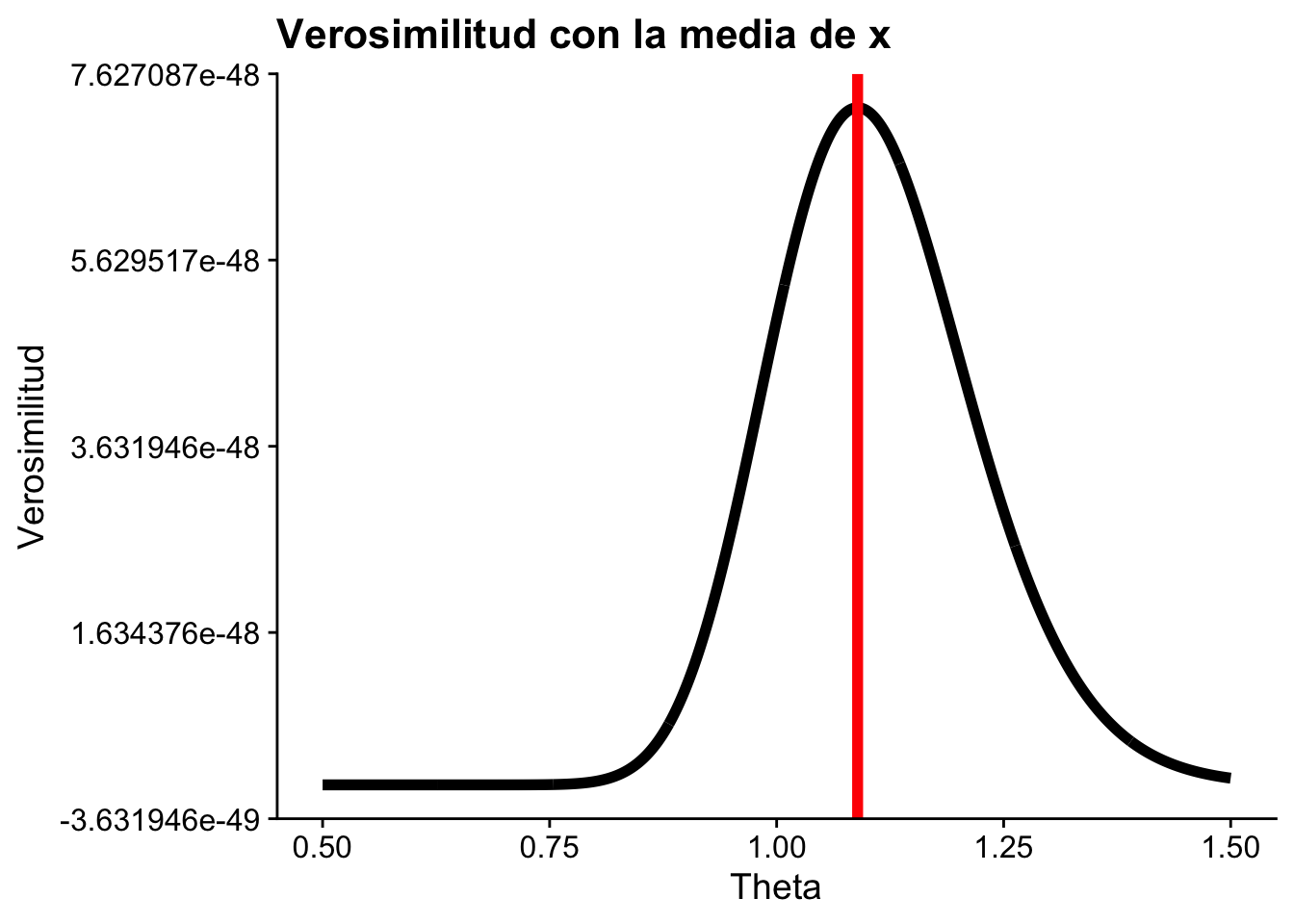
Ahora generemos 100 valores con una distribución exponencial con parámetro \(\theta=1\) y grafiquemos la función de verosimilitud y la log-verosimilitud:
x <- rexp(n = 100, rate = 1)
n <- length(x)
y <- sum(x)
theta <- seq(0.5, 1.5, length.out = 1000)ggplot(
data.frame(
theta = theta,
L = theta^(-n) * exp(-y / theta)
),
aes(x = theta, y = L)
) +
geom_line(linewidth = 2) +
geom_vline(aes(xintercept = mean(x)), linewidth = 2, color = "red") +
cowplot::theme_cowplot() +
labs(
title = "Verosimilitud con la media de x",
x = "Theta",
y = "Verosimilitud"
)
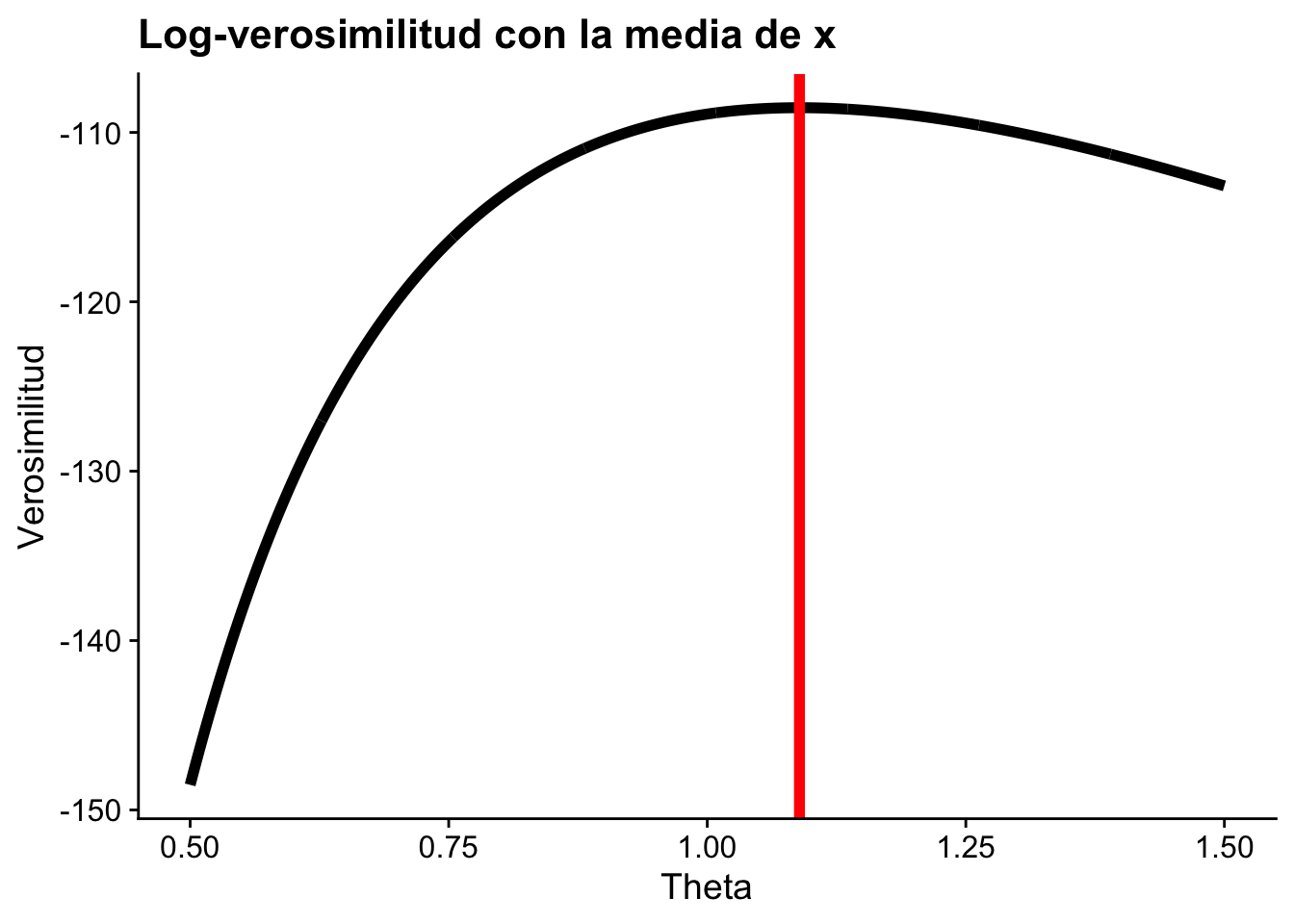
ggplot(
data.frame(
theta = theta,
l = -n * log(theta) - y / theta
),
aes(x = theta, y = l)
) +
geom_line(linewidth = 2) +
geom_vline(aes(xintercept = mean(x)), linewidth = 2, color = "red") +
cowplot::theme_cowplot() +
labs(
title = "Log-verosimilitud con la media de x",
x = "Theta",
y = "Verosimilitud"
)
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(42)
x_py = rng.exponential(scale=1.0, size=100) # Exp(theta=1) -> scale=theta
n_py = len(x_py)
y_py = x_py.sum()
theta_py = np.linspace(0.5, 1.5, 1000)
# Verosimilitud: theta^{-n} * exp(-y/theta)
L_py = theta_py ** (-n_py) * np.exp(-y_py / theta_py)
# Log-verosimilitud: -n*log(theta) - y/theta
l_py = -n_py * np.log(theta_py) - y_py / theta_py
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
axes[0].plot(theta_py, L_py, linewidth=2)
axes[0].axvline(x_py.mean(), color="red", linewidth=2)
axes[0].set_title("Verosimilitud con la media de x")
axes[0].set_xlabel("Theta")
axes[0].set_ylabel("Verosimilitud")
axes[1].plot(theta_py, l_py, linewidth=2)
axes[1].axvline(x_py.mean(), color="red", linewidth=2)
axes[1].set_title("Log-verosimilitud con la media de x")
axes[1].set_xlabel("Theta")
axes[1].set_ylabel("Log-verosimilitud")
plt.tight_layout()
plt.show()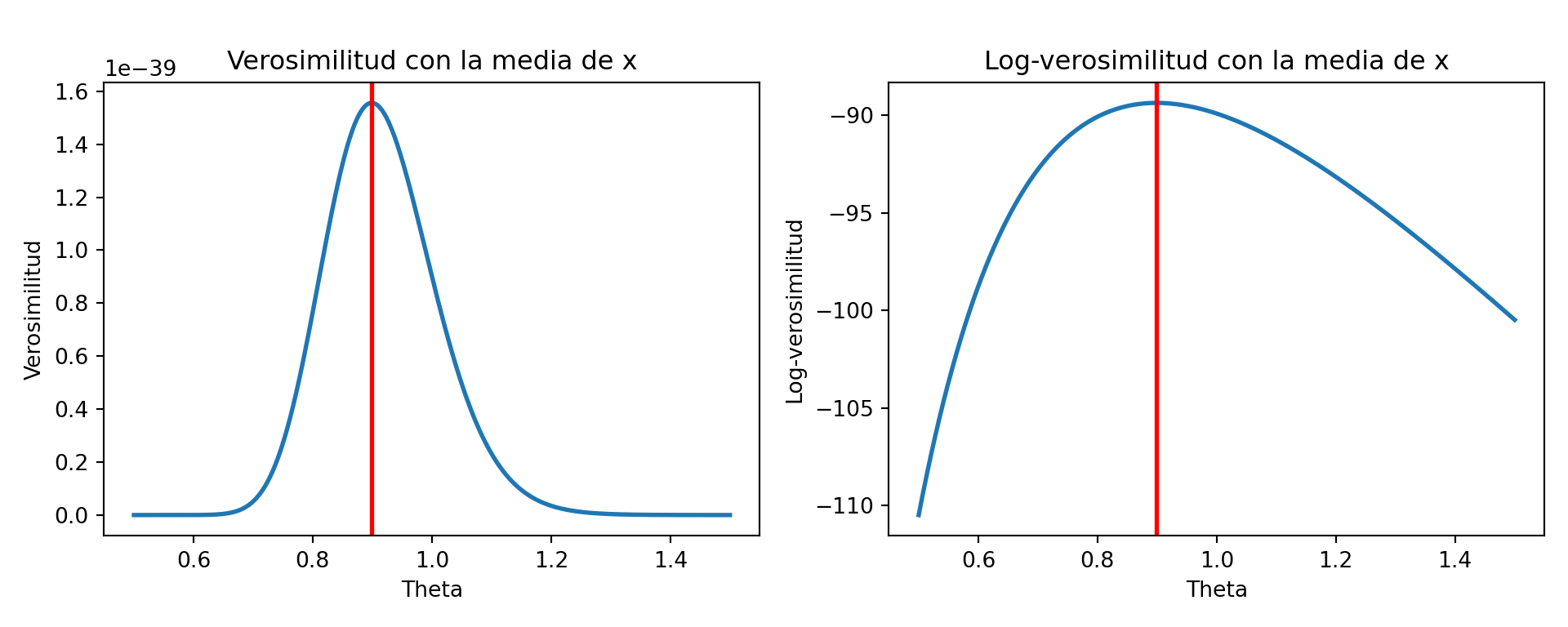
Ejemplo 5.2 Suponga que se está haciendo pruebas RT-PCR para detectar el virus SARS-CoV-2. La prueba es 90% confiable en el siguiente sentido:
En este caso nuestra variable aleatoria es \(\text{Bernoulli}(\theta)\), donde el espacio total paramétrico consiste de \(\theta \in \{0.9,0.1\}\). En este ejemplo \(0.1\) significa negativo y \(0.9\) significa positivo.
Nuestra muestra tendría la siguiente forma:
\[ x = \begin{cases}1 & \text{si la prueba es positiva}\\0& \text{si no}\end{cases} \]
Resumiendo el comportamiento de la prueba, tendríamos estas funciones de densidad
Si \(x=1\), entonces \(f(1\mid\theta) = \begin{cases}0.1 & \text{si }\theta = 0.1\\0.9& \text{si }\theta = 0.9\end{cases}\).
Si \(x=0\), entonces \(f(0\mid\theta) = \begin{cases}0.9 & \text{si }\theta = 0.1\\0.1& \text{si }\theta = 0.9\end{cases}\).
Veamos este gráfico que explica lo que está sucediendo:
graph TB
inicio(Inicio) --> prueba("Resultado de la Prueba")
prueba --> theta09("Positiva (x=1)" )
prueba --> theta01("Negativa (x=0)")
theta01 --> p01a("P(θ=0.1|x=0) = 0.9"):::max
theta01 --> p01b("(P(θ=0.9|x=0) = 0.1)")
theta09 --> p09a("P(θ=0.1|x=1) = 0.1")
theta09 --> p09b("P(θ=0.9|x=1) = 0.9"):::max
classDef max fill:#ff9999,color:#000,stroke-width:4px;
%% classDef default fill:#f9f,stroke:#333,stroke-width:4px;
%% classDef theta fill:#bbf,stroke:#333,stroke-width:4px;
%% class prueba,theta01,theta09 theta;
Entonces los cuadros marcados en rojos, indican donde se maximiza la probabilidad para este ejemplo. Por lo tanto el MLE corresponde a
\[ \hat\theta = \begin{cases}0.1 & \text{si }x= 0\\0.9& \text{si }x= 1\end{cases} \]
theta <- c(0.1, 0.9)
## Define f(0|theta)
f_x0 <- c(0.9, 0.1)
## Define f(1|theta)
f_x1 <- c(0.1, 0.9)
df <- data.frame(
theta = rep(theta, 2),
likelihood = c(f_x0, f_x1),
x = factor(rep(0:1, each = 2))
)
# Gráfico
ggplot(df, aes(x = as.factor(theta), y = likelihood, fill = x)) +
geom_bar(stat = "identity", position = "dodge") +
labs(
title = "Función de verosimilitud para diferentes valores de x",
x = expression(theta),
y = "Verosimilitud",
fill = "Valor de x"
) +
cowplot::theme_cowplot() +
scale_fill_manual(values = c("blue", "red"), labels = c("x = 0", "x = 1"))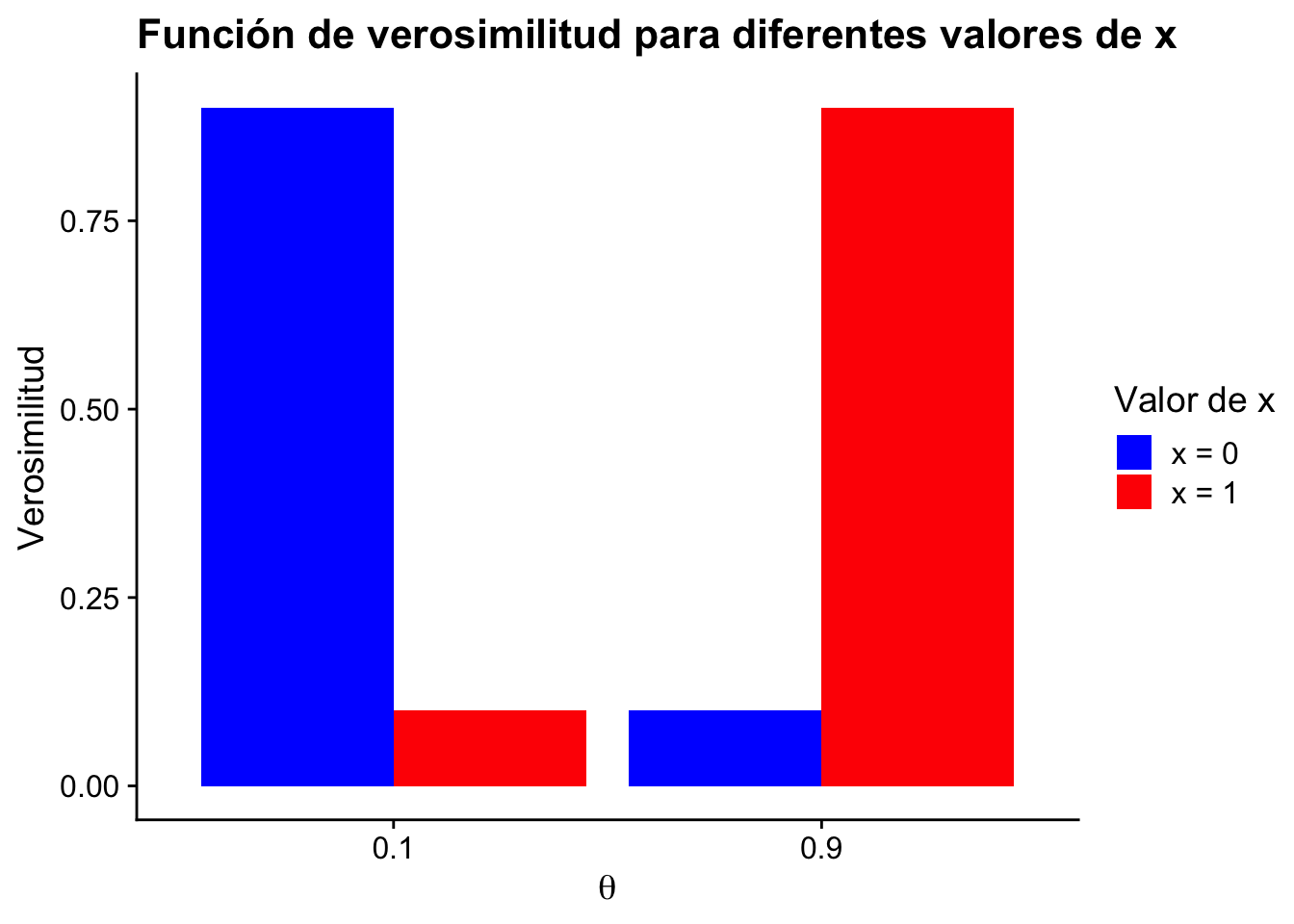
import numpy as np # noqa: E402
import matplotlib.pyplot as plt # noqa: E402
theta_b = np.array([0.1, 0.9])
f_x0_b = np.array([0.9, 0.1]) # f(0|theta): P(negativo | theta)
f_x1_b = np.array([0.1, 0.9]) # f(1|theta): P(positivo | theta)
x_pos = np.arange(len(theta_b))
width = 0.35
fig, ax = plt.subplots(figsize=(6, 4))
ax.bar(x_pos - width / 2, f_x0_b, width, label="x = 0", color="blue")
ax.bar(x_pos + width / 2, f_x1_b, width, label="x = 1", color="red")
ax.set_title("Función de verosimilitud para diferentes valores de x")
ax.set_xlabel("θ")
ax.set_ylabel("Verosimilitud")
ax.set_xticks(x_pos)
ax.set_xticklabels([str(t) for t in theta_b])
ax.legend(title="Valor de x")
plt.tight_layout()
plt.show()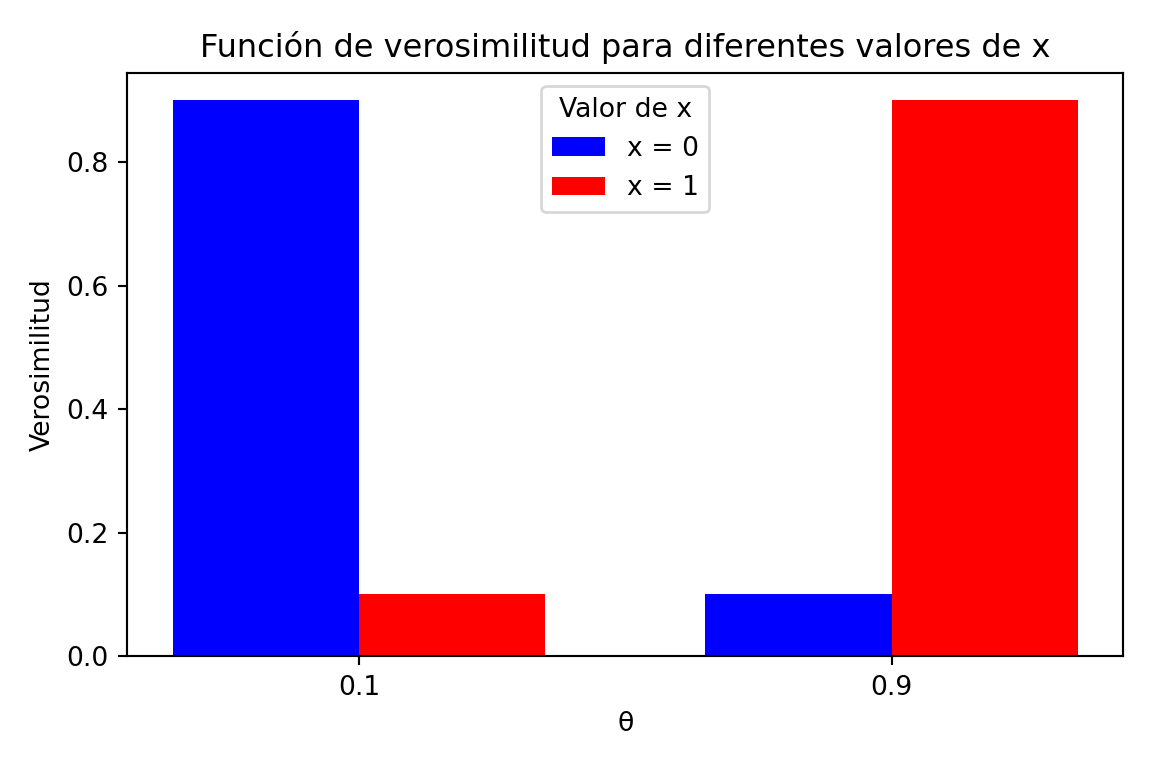
Ejemplo 5.3 (Caso 1: Varianza conocida) Consideremos una muestra \(X_1,\dots, X_n\) que sigue una distribución normal \(N(\mu,\sigma^2)\) con \(\sigma^2\) conocida. Estamos interesados en estimar el parámetro \(\mu\).
La función de verosimilitud para esta muestra es:
\[\begin{equation*} f_n(X\mid \mu) = \prod_{i=1}^n f(X_i\mid \mu) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(x_i-\mu)^2}{2\sigma^2}\right) = (2\pi\sigma^2)^{-n/2}\exp\left(-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2\right). \end{equation*}\]
La log-verosimilitud es:
\[\begin{equation*} \ell(\mu\mid X) = \ln f_n(X\mid \mu) = -\frac{n}{2}\ln(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2. \end{equation*}\]
Para encontrar el estimador de máxima verosimilitud (MLE) de \(\mu\), derivamos la log-verosimilitud con respecto a \(\mu\) y resolvemos para \(\mu\):
\[\begin{align*} \frac{\partial}{\partial\mu} \ell(\mu\mid X) &= \frac{\partial}{\partial\mu} \left[ -\frac{n}{2}\ln(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^n(X_i-\mu)^2 \right] \\ &= \frac{1}{\sigma^2}\sum_{i=1}^n(X_i-\mu) = 0 \\ \implies \sum_{i=1}^n(X_i-\mu) &= 0 \\ \implies \sum_{i=1}^n X_i - n\mu &= 0 \\ \implies \hat\mu = \frac{1}{n}\sum_{i=1}^n X_i &= \bar{X}_n. \end{align*}\]
Dado que la función es cuadrática en \(\mu\), tiene un único máximo. Por lo tanto, el MLE de \(\mu\) es:
\[\begin{equation*} \hat\mu = \bar{X}_n. \end{equation*}\]
Ejemplo 5.4 (Caso 2: Varianza desconocida) Si consideramos una muestra \(X_1,\dots, X_n\) que sigue una distribución normal \(N(\mu,\sigma^2)\) con \(\sigma^2\) desconocida, la función de log-verosimilitud es:
\[\begin{equation*} \ell(\mu,\sigma^2\mid X) = \ln f_n(X\mid \mu,\sigma^2) = -\frac{n}{2}\ln(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^n(X_i-\mu)^2. \end{equation*}\]
Si fijamos \(\mu=\bar{X}_n\) y derivamos con respecto a \(\sigma^2\), obtenemos:
\[\begin{align*} \frac{\partial}{\partial\sigma^2} \ell(\mu,\sigma^2\mid X) &= \frac{\partial}{\partial\sigma^2} \left[ -\frac{n}{2}\ln(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^n(X_i-\bar{X})^2 \right] \\ &= -\frac{n}{2\sigma^2} + \frac{1}{2(\sigma^2)^2} \sum_{i=1}^n(X_i-\bar{X}_n)^2 = 0 \\ \end{align*}\]
De la última igualdad, obtenemos que:
\[\begin{align*} \frac{n}{2\sigma^2} &= \frac{1}{2(\sigma^2)^2} \sum_{i=1}^n(X_i-\bar{X}_n)^2 \\ \hat\sigma^2 &= \frac{1}{n}\sum_{i=1}^n(X_i-\bar{X}_n)^2 \end{align*}\]
Esta es la fórmula para la varianza muestral.
Las condiciones de segundo orden para verificar que es un máximo se dejan como ejercicio para el lector.
Ejemplo 5.5 (Visualización de la función de verosimilitud) Ahora observe como quedaría la verosimilitud si variamos al mismo tiempo \(\mu\) y \(\sigma\).
Primero, generemos datos aleatorios de una distribución normal para simular una muestra:
set.seed(123)
n <- 100
data <- rnorm(n, mean = 5, sd = 2)Luego, definimos la función de log-verosimilitud:
log_likelihood <- function(mu, sigma_sq, data) {
n <- length(data)
-n / 2 * log(2 * pi * sigma_sq) - (1 / (2 * sigma_sq)) * sum((data - mu)^2)
}Ahora, generamos una grilla de valores para mu y sigma^2 y calculamos la log-verosimilitud para cada combinación:
mu_vals <- seq(4, 6, length.out = 100)
sigma_sq_vals <- seq(2, 5, length.out = 100)
ll_vals <- matrix(0, nrow = length(mu_vals), ncol = length(sigma_sq_vals))
for (i in seq_along(mu_vals)) {
for (j in seq_along(sigma_sq_vals)) {
ll_vals[i, j] <- log_likelihood(mu_vals[i], sigma_sq_vals[j], data)
}
}Y finalmente gráficamos la función de verosimilitud:
df <- expand.grid(mu = mu_vals, sigma_sq = sigma_sq_vals)
df$ll <- as.vector(ll_vals)
ggplot(df, aes(x = mu, y = sigma_sq, z = ll)) +
geom_raster(aes(fill = ll)) +
geom_contour(aes(z = ll), color = "white") +
geom_point(aes(x = mean(data), y = mean((data - mean(data))^2)), color = "red", size = 4) +
scale_fill_viridis_c() +
labs(
title = "Log-verosimilitud en función de mu y sigma^2",
x = expression(mu),
y = expression(sigma^2),
fill = "Log-verosimilitud"
) +
cowplot::theme_cowplot()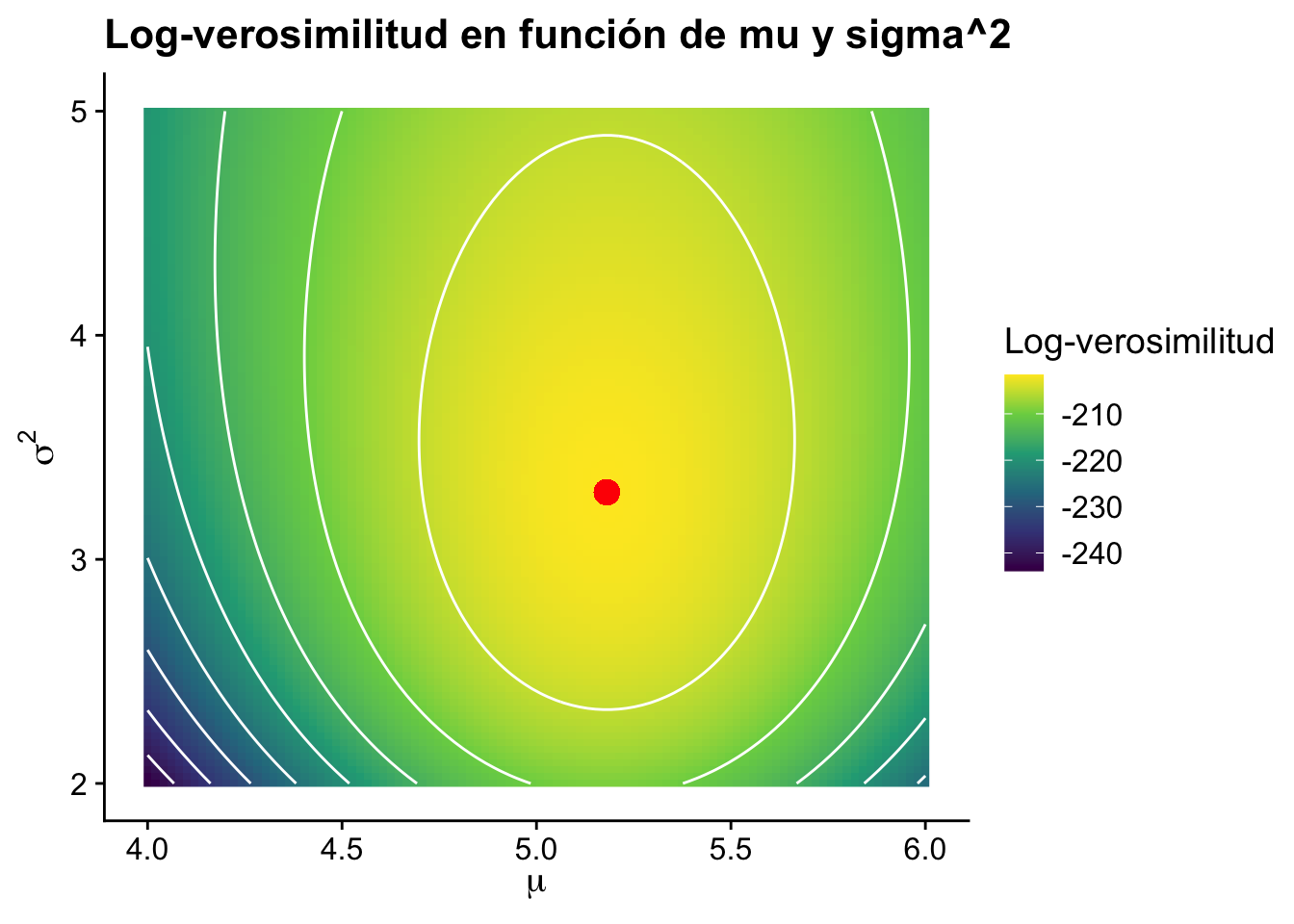
import numpy as np # noqa: E402
import matplotlib.pyplot as plt # noqa: E402
rng_n = np.random.default_rng(123)
data_py = rng_n.normal(loc=5, scale=2, size=100)
mu_vals_py = np.linspace(4, 6, 100)
sigma_sq_vals_py = np.linspace(2, 5, 100)
MU, SQ = np.meshgrid(mu_vals_py, sigma_sq_vals_py)
n_py = len(data_py)
# log-verosimilitud: -n/2 * log(2*pi*sigma^2) - sum((x-mu)^2) / (2*sigma^2)
LL = -n_py / 2 * np.log(2 * np.pi * SQ) - np.sum(
(data_py[:, None, None] - MU[None, :, :]) ** 2, axis=0
) / (2 * SQ)
fig, ax = plt.subplots(figsize=(7, 5))
cf = ax.contourf(MU, SQ, LL, levels=30, cmap="viridis")
ax.contour(MU, SQ, LL, levels=30, colors="white", linewidths=0.5)
ax.scatter(data_py.mean(), data_py.var(), color="red", s=80, zorder=5, label="MLE")
plt.colorbar(cf, ax=ax, label="Log-verosimilitud")<matplotlib.colorbar.Colorbar object at 0x1410c6f90>ax.set_title("Log-verosimilitud en función de μ y σ²")
ax.set_xlabel("μ")
ax.set_ylabel("σ²")
ax.legend()
plt.tight_layout()
plt.show()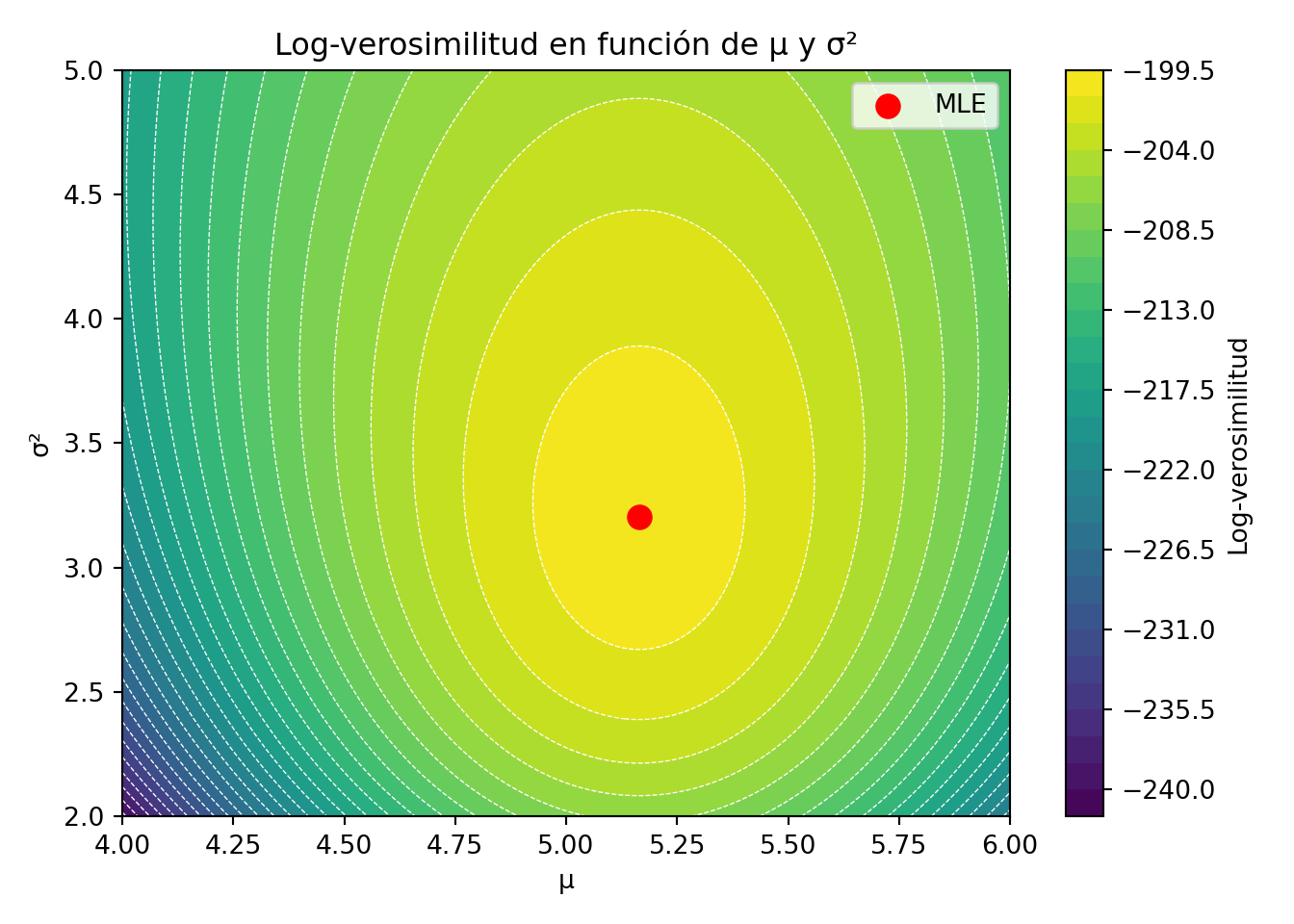
Ejemplo 5.6 Consideremos una muestra \(X_1,\dots, X_n\) que son variables aleatorias independientes e idénticamente distribuidas (i.i.d.) con distribución uniforme en el intervalo \([0,\theta]\), donde \(\theta>0\). Asumimos que cada observación \(X_i>0\).
La función de densidad para esta distribución es:
\[\begin{equation*} f(X\mid\theta)=\frac{1}{\theta}\cdot 1_{[0,\theta]}(x) \end{equation*}\]
Donde \(1_{[0,\theta]}(x)\) es una función indicadora que toma el valor de 1 si \(x\) está en el intervalo \([0,\theta]\) y 0 en caso contrario.
La función de verosimilitud para la muestra es:
\[\begin{equation*} f_n(X\mid\theta)=\prod_{i=1}^n f(X_i\mid\theta)=\frac{1}{\theta^n}\prod_{i=1}^n 1_{[0,\theta]}(X_i)=\frac{1}{\theta^n} \prod_{i=1}^n 1_{\{0\leq X_i\leq \theta\}} \quad 0\leq X_i \leq \theta \;\forall i. \end{equation*}\]
Note que \(f_n(X\mid\theta)\) es positivo si y solo si \(0\leq X_{(n)}\leq \theta\). donde \(X_{(n)}=\max\{X_1,\dots,X_n\}\) es el estadístico de orden máximo.
El valor de la muestra en la \(i\)-ésima posición, cuando los datos se ordenan de menor a mayor, se denota \(X_{(i)}\) (estadístico de orden). En este caso, \(X_{(n)} = \max\{X_1,\dots, X_n\}\). Entonces \(\hat\theta_{MLE} = X_{(n)}\).
Por ejemplo, si definimos que \(\theta=2\) entonces en ese punto existe una singularidad de la verosimilitud. En términos prácticos, esto significa que la función de verosimilitud no está definida o no es finita en ese punto. Es esencial ser consciente de estas singularidades al trabajar con estimaciones de máxima verosimilitud, ya que pueden afectar los resultados y la interpretación.
x <- runif(100, 0, 2)
n <- length(x)
theta <- seq(1.5, 2.5, length.out = 1000)
L <- numeric(1000)
for (k in 1:1000) {
L[k] <- 1 / theta[k]^n * prod(x < theta[k])
}
ggplot(data.frame(theta, L), aes(x = theta, y = L)) +
geom_line(linewidth = 2) +
geom_vline(
aes(xintercept = max(x)),
color = "red",
linetype = "dashed",
linewidth = 2
) +
labs(
title = "Función de verosimilitud para diferentes valores de theta",
x = expression(theta),
y = "Verosimilitud"
) +
cowplot::theme_cowplot()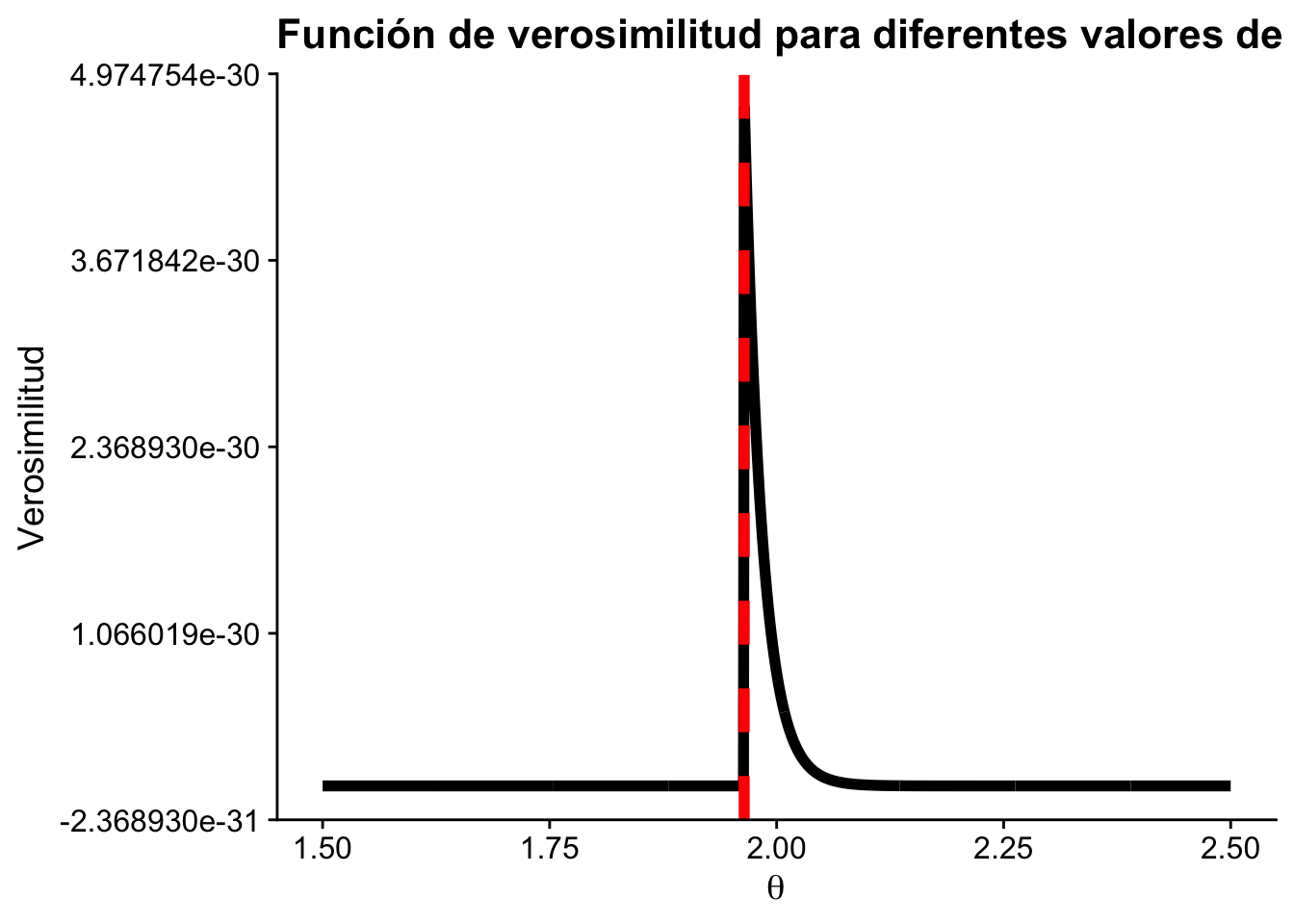
import numpy as np # noqa: E402
import matplotlib.pyplot as plt # noqa: E402
rng_u = np.random.default_rng(42)
x_u = rng_u.uniform(0, 2, size=100)
n_u = len(x_u)
theta_u = np.linspace(1.5, 2.5, 1000)
# Verosimilitud: 1/theta^n si todos los X_i <= theta, 0 en caso contrario
L_u = np.array([(1 / t**n_u) if np.all(x_u <= t) else 0.0 for t in theta_u])
plt.figure(figsize=(6, 4))
plt.plot(theta_u, L_u, linewidth=2)
plt.axvline(
x_u.max(),
color="red",
linestyle="dashed",
linewidth=2,
label=f"MLE = {x_u.max():.3f}",
)
plt.title("Función de verosimilitud para diferentes valores de theta")
plt.xlabel("θ")
plt.ylabel("Verosimilitud")
plt.legend()
plt.tight_layout()
plt.show()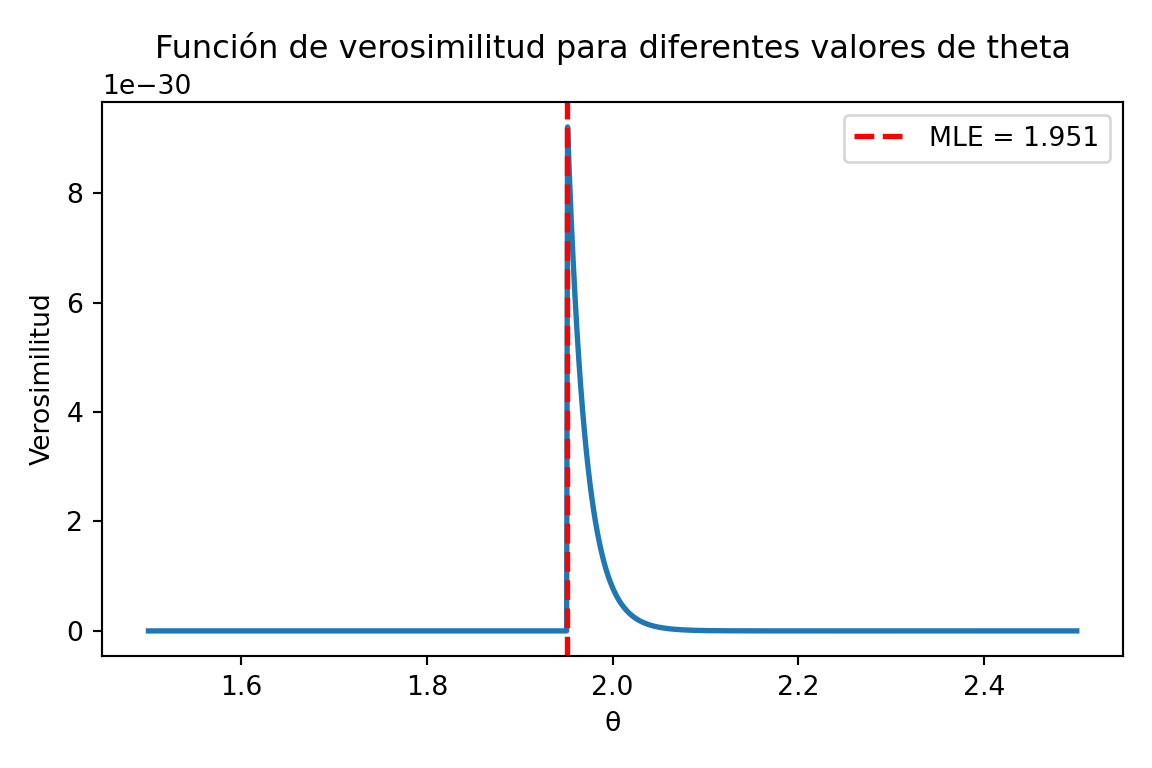
El siguiente diagrama resume el procedimiento general para obtener el MLE:
flowchart TB
A["$$\text{Muestra: }X_1,...,X_n$$"] --> B["$$\text{Verosimilitud: } L = \prod f(X_i|\theta)$$"]
B --> C["$$\text{Log-verosimilitud: } \ell = \sum \log f(X_i|\theta)$$"]
C --> D["$$\text{Derivar e igualar a cero: }\frac{d\ell}{d\theta} = 0$$"]
D --> E{"¿Solución cerrada?"}
E -->|"Sí"| F["$$\hat\theta = \text{fórmula}$$"]
E -->|"No"| G["$$\text{Optimización numérica}$$"]
F --> H["$$\text{Verificar: }\frac{d^{2}\ell}{d\theta^{2}}\lt 0$$"]
G --> H
H --> I["$$\hat\theta = \text{MLE}$$"]
El procedimiento anterior nos da el MLE, pero quedan dos preguntas naturales: ¿qué pasa si transformamos el parámetro? ¿y podemos confiar en el MLE con muestras pequeñas? Las dos secciones siguientes responden a estas preguntas mediante las propiedades de invarianza y consistencia.
Teorema 5.1 Si \(\hat\theta\) es el MLE de \(\theta\) y si \(g\) es biyectiva, entonces \(g(\hat\theta)\) es el MLE de \(g(\theta)\).
Demostración. Sea \(\Psi = g(\Omega)\) el espacio paramétrico inducido para \(\psi\). Dado que \(g\) es biyectiva entonces defina la inversa de \(g\) como \(\theta = g^{-1}(\psi), \psi \in \Psi\). Al reparametrizar la función de verosimilitud, tenemos:
\[\begin{equation*} f_n(x\mid\theta)=f_n(x\mid g^{-1}(\psi)) \end{equation*}\]
El MLE de \(\psi\) es \(\hat\psi\) y satisface que \(f_n(x\mid g^{-1}(\hat\psi))\) es máximo. Dado que \(f_n(x\mid\theta)\) se maximiza cuando \(\theta = \hat \theta\), entonces \(f_n(x\mid g^{-1}(\psi))\) se maximiza cuando \(\hat \theta = g^{-1}(\psi)\) para algún \(\psi\). Por lo tanto, si \(\hat\theta = g^{-1}(\hat\psi)\) entonces \(\hat\psi = g(\hat \theta)\).
Ejemplo 5.7 Suponga que para el caso exponencial se tiene que el MLE de \(\theta\) es \(\hat{\theta}= \bar{X}_n\). Si se quisiera el MLE de \(\dfrac{1}{\theta}\) entonces se tiene que \(g(\theta) = \dfrac{1}{\theta}\) y \(g^{-1}(\psi) = \dfrac{1}{\psi}\). Por lo tanto, el MLE de \(\dfrac{1}{\theta}\) es \(\dfrac{1}{\bar{X}_n}\).
Definición 5.3 (Generalización del MLE) Si \(g\) es una función de \(\theta\) y \(G\) la imagen de \(\Omega\) bajo \(g\). Para cada \(t\in G\) defina \[ G_t = \{\theta: g(\theta) = t\} \] Defina \(L^*(t) = \displaystyle\max_{\theta\in G_t} \ln f_n(x|\theta)\). El MLE de \(g(\theta)\) es igual a un valor \(\hat t\) y satisface \(L^*(\hat t) = \displaystyle\max_{t \in G} L^*(t)\).
Teorema 5.2 Si \(\hat{\theta}\) es el MLE de \(\theta\) entonces \(g(\hat\theta)\) es el MLE de \(g(\theta)\) (\(g\) es arbitraria).
Demostración. Basta probar que \(L^*(\hat t) = \ln f_n(x|\hat \theta)\). Se cumple que \(\hat\theta\in G_{\hat t}\). Como \(\hat \theta\) maximiza \(f_n(x|\theta)\) \(\forall \theta\), también lo hace si \(\theta \in G_{\hat t}\). Entonces \(\hat t = g(\hat \theta)\) (no pueden existir 2 máximos en un conjunto con la misma imagen).
Ejemplo 5.8 Considere una muestra \(X_1,\dots, X_n\sim N(\mu,\sigma^2)\).
Observación. Si \(\hat\theta\) es el MLE de \(\theta\), entonces \(g(\hat\theta)\) es el MLE de \(g(\theta)\).
Ya sabemos que el MLE maximiza la verosimilitud, pero eso no garantiza que sea cercano al verdadero \(\theta\). La consistencia formaliza la idea de que, con más datos, el estimador no puede desviarse del valor real.
Definición 5.4 Un estimador \(\hat{\theta}_n\) proveniente de la muestra \(X_1, \dots, X_n\) se dice consistente si para cada \(\epsilon>0\) y \(\theta \in \Omega\) \[\begin{equation*} \lim_{n\to\infty} \mathbb{P}(\vert \hat{\theta}_n-\theta\vert<\epsilon) = 1. \end{equation*}\]
Denotamos esta convergencia como
\[ \hat{\theta}_{n} \xrightarrow[n\to \infty]{\mathbb P}\theta. \]
Informalmente, la definición anterior dice que a medida que el tamaño de la muestra se vuelve infinito (y la información de la muestra se vuelve cada vez mejor), el estimador estará arbitrariamente cerca del parámetro con alta probabilidad, una propiedad eminentemente deseable. O, cambiando las cosas, podemos decir que la probabilidad de que una secuencia consistente de estimadores no alcance el parámetro verdadero es pequeña.
Recordemos que los estimadores bayesianos combinan la información de la previa con la de los datos. Cuando el tamaño de muestra crece, el peso de la previa disminuye y el estimador bayesiano converge al MLE. Este es el puente con el capítulo anterior: si usted tiene datos suficientes, la elección de previa importa cada vez menos.
El MLE es consistente bajo condiciones regulares: basta garantizar que \(\lim_{n\to\infty} \mathrm{Var}(\hat{\theta}_{n}) = 0\) y \(\lim_{n\to\infty} \mathrm{Bias}(\hat{\theta}_{n}) = 0\). Bajo estas condiciones
\[ \hat\theta_{MLE} \xrightarrow[n\to \infty]{\mathbb P}\theta. \]
En algunos casos, la ecuación \(\partial\ell/\partial\theta = 0\) no se puede resolver analíticamente y se requieren métodos numéricos o alternativos, como el método de los momentos.
Ejemplo 5.9 Consideremos una muestra \(X_1,\dots, X_n\) que sigue una distribución Gamma \(\Gamma(\alpha,1)\). Estamos interesados en estimar el parámetro \(\alpha\). La función de densidad de la distribución Gamma es dada por:
\[\begin{equation*} f(x\mid\alpha)=\frac{1}{\Gamma(\alpha)}x^{\alpha-1}e^{-x} \end{equation*}\]
La función de verosimilitud asociada es:
\[\begin{equation*} f_n(x\mid\alpha)=\frac{1}{\Gamma(\alpha)^n}\prod_{i=1}^n x_i^{\alpha-1}e^{-x_i} \end{equation*}\]
Para encontrar el estimador de máxima verosimilitud (MLE) de \(\alpha\), derivamos la log-verosimilitud con respecto a \(\alpha\) y la igualamos a cero:
\[\begin{align*} \frac{\partial}{\partial\alpha} \ell(\alpha\mid X) &= \frac{\partial}{\partial\alpha} \left[ -n\ln \Gamma(\alpha) + (\alpha-1)\sum_{i=1}^n \ln X_i - \sum_{i=1}^n X_i \right] \\ &= -n\frac{1}{\Gamma(\alpha)}\frac{\partial}{\partial\alpha}\Gamma(\alpha) + \sum_{i=1}^n \ln X_i = 0 \\ \end{align*}\]
El problema con este cálculo es que no existe una expresión cerrada para la derivada de la función Gamma. Usualmente se hacen aproximaciones numéricas.
Definición 5.5 Supongamos que tenemos una muestra \(X_1,\dots, X_n\) que sigue una distribución \(F\), indexada por un parámetro \(\theta\) que reside en \(\mathbb{R}^k\), y que tiene al menos \(k\) momentos finitos. Para \(j=1,\dots,k\), definimos \(\mu_j(\theta)=\mathbb{E}[X_1^j\mid\theta]\). Asumimos que la función \(\mu(\theta)=(\mu_1(\theta),\dots,\mu_k(\theta))\) es biyectiva. Definimos \(M\) como la inversa de \(\mu\), es decir,
\[\begin{equation*} M(\mu(\theta))=\theta=M(\mu_1(\theta),\dots,\mu_k(\theta)) \end{equation*}\]
y definimos los momentos empíricos como:
\[\begin{equation*} m_j=\frac{1}{n}\sum_{i=1}^n X_i^j, \quad j=1,\dots, k. \end{equation*}\]
El estimador por método de los momentos es:
\[\begin{equation*} \hat\theta_{\text{MoM}} = M(m_1,\dots,m_k). \end{equation*}\]
Ejemplo 5.10 Del ejemplo anterior, \(\mu_1(\alpha) = \mathbb{E}[x_1|\alpha] = \alpha\). Dado que \(m_1 = \bar{x}_n\), el sistema por resolver es
\[ \mu_1(\alpha) = m_1 \Longleftrightarrow \alpha = \bar x_n \]
El estimador por método de momentos es \(\hat \alpha = \bar{X}_n\).
Ejemplo 5.11 Consideremos una muestra \(X_1,\dots, X_n\) que sigue una distribución \(\mathrm{Gamma}(\alpha,\beta)\). Sabemos que la media es \(\mu=\alpha/\beta\) y la varianza es \(\sigma^2=\alpha/\beta^2\). Por lo tanto el segundo momento es
\[\begin{equation*} \mathbb{E}[X^2] = \mathrm{Var}(X) + \mathbb{E}[X]^2 = \frac{\alpha}{\beta^2} + \left(\frac{\alpha}{\beta}\right)^2 = \frac{\alpha(\alpha+1)}{\beta^2} \end{equation*}\]
Para encontrar los estimadores de \(\alpha\) y \(\beta\), necesitamos resolver el siguiente sistema de ecuaciones:
\[\begin{equation*} \begin{cases} \mu_1(\theta) = \dfrac{\alpha}\beta = \bar{X}_n = m_1& (1)\\ \mu_2(\theta) = \dfrac{\alpha(\alpha+1)}{\beta^2}=m_2 & (2) \end{cases} \end{equation*}\]
De \((1)\), \(\alpha = m_1\beta\). Sustituyendo en \((2)\),
\[ m_2 = \dfrac{m_1\beta(m_1\beta+1)}{\beta^2} = m_1^2+\dfrac{m_1}{\beta} \implies m_2-m_1^2 = \dfrac{m_1}{\beta}. \] De esta manera, \[ \hat\beta = \dfrac{m_1}{m_2-m_1^2},\quad \hat\alpha = \dfrac{m_1^2}{m_2-m_1^2} \]
Teorema 5.3 Supongamos que \(X_1,\dots, X_n\) son variables aleatorias independientes e idénticamente distribuidas (i.i.d) con una distribución indexada por \(\theta\in\mathbb{R}^k\). Si los \(k\) momentos teóricos son finitos para todo \(\theta\) y \(M\) es una función continua, entonces el estimador obtenido mediante el método de los momentos es consistente.
Suponga que tenemos una tabla con los siguientes datos, los cuales representan la cantidad de giros hacia la derecha en cierta intersección.
(
X <- c(
rep(0, 14),
rep(1, 30),
rep(2, 36),
rep(3, 68),
rep(4, 43),
rep(5, 43),
rep(6, 30),
rep(7, 14),
rep(8, 10),
rep(9, 6),
rep(10, 4),
rep(11, 1),
rep(12, 1)
)
) [1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
[26] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2
[51] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[76] 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[101] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[126] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4 4
[151] 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
[176] 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5
[201] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5
[226] 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6
[251] 6 6 6 6 6 6 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 7 7 7 7
[276] 7 7 7 8 8 8 8 8 8 8 8 8 8 9 9 9 9 9 9 10 10 10 10 11 12Queremos ajustar esta tabla a una distribución Poisson con función de densidad
\[ \mathbb{P}(X=x) = \frac{\lambda^x e^{-\lambda}}{x!} \]
Se puede probar que teórico de máxima verosimilitud para \(\lambda\) es \(\overline{X}\) (Tarea). Queremos estimar este parámetro alternativamente maximizando la función de verosimilitud.
Primero veamos la forma de los datos,
ggplot(data.frame(X), aes(x = X)) +
geom_histogram(aes(y = after_stat(density)), binwidth = 1,
boundary = -0.5, fill = "steelblue", color = "black") +
labs(title = "Número de giros a la derecha", x = "x", y = "Densidad") +
cowplot::theme_cowplot()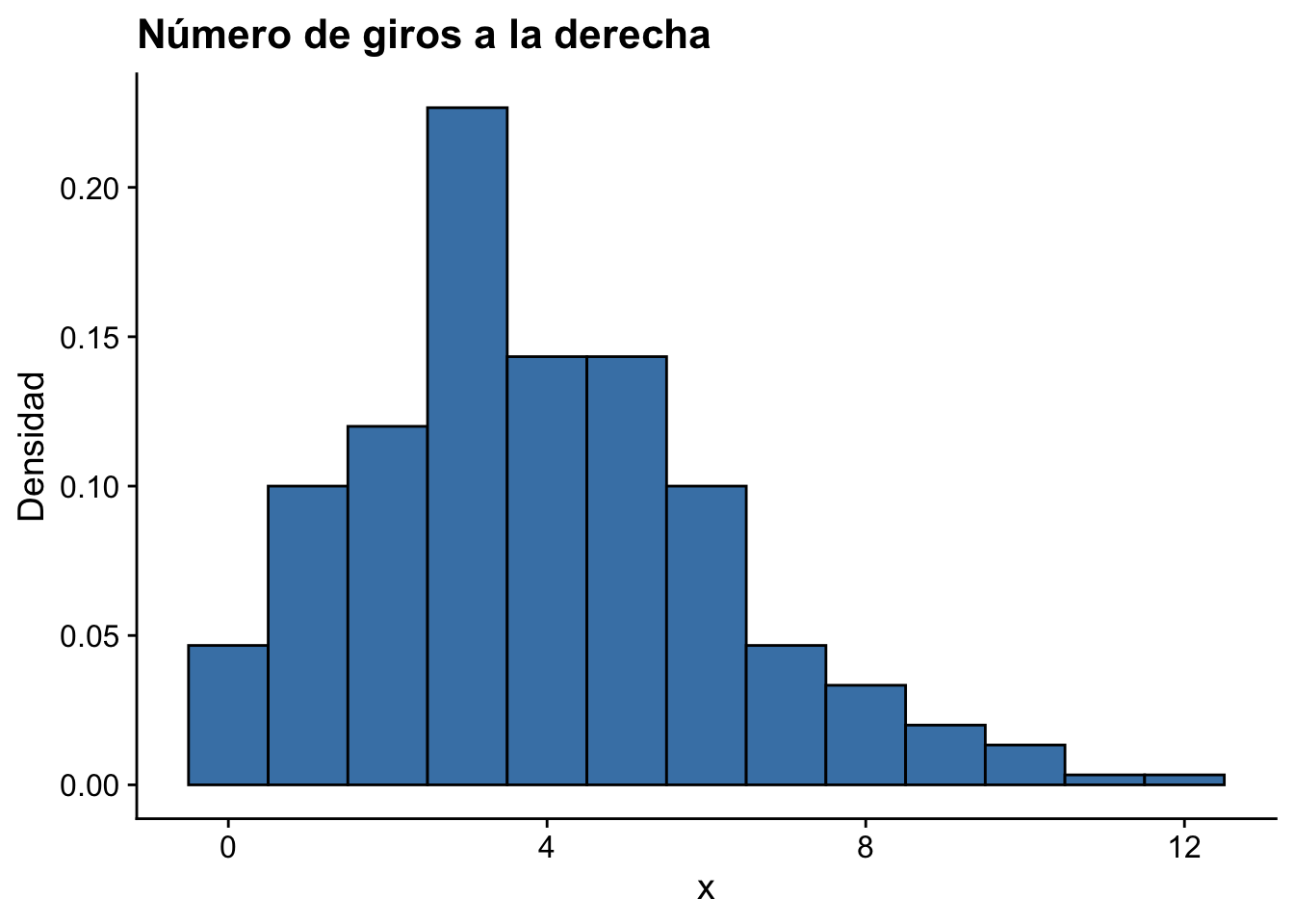
Definamos la función correspondiente como \(-\log(\mathbb{P}(X=x))\)
n <- length(X)
negloglike <- function(lambda) {
n * lambda - sum(X) * log(lambda) + sum(log(factorial(X)))
}Para encontrar el parámetro deseado, basta minimizar la función negloglike usando optimize(), que busca el mínimo de una función univariada en un intervalo dado:
lambda_hat <- optimize(negloglike, interval = c(0.01, 20))Compare el resultado de lambda_hat$minimum con mean(X), el cual sería el estimador por el método de los momentos:
lambda_hat$minimum[1] 3.893333mean(X)[1] 3.893333import numpy as np # noqa: E402
import matplotlib.pyplot as plt # noqa: E402
from scipy.optimize import minimize_scalar # noqa: E402
from math import factorial # noqa: E402
# Los mismos datos: frecuencias por valor
counts = {
0: 14,
1: 30,
2: 36,
3: 68,
4: 43,
5: 43,
6: 30,
7: 14,
8: 10,
9: 6,
10: 4,
11: 1,
12: 1,
}
X_py = np.array([v for v, c in counts.items() for _ in range(c)])
n_pois = len(X_py)
# Histograma de los datos
plt.figure(figsize=(6, 4))
plt.hist(X_py, bins=range(14), align="left", density=True, edgecolor="black")
plt.title("Número de giros a la derecha")
plt.xlabel("x")
plt.ylabel("Densidad")
plt.tight_layout()
plt.show()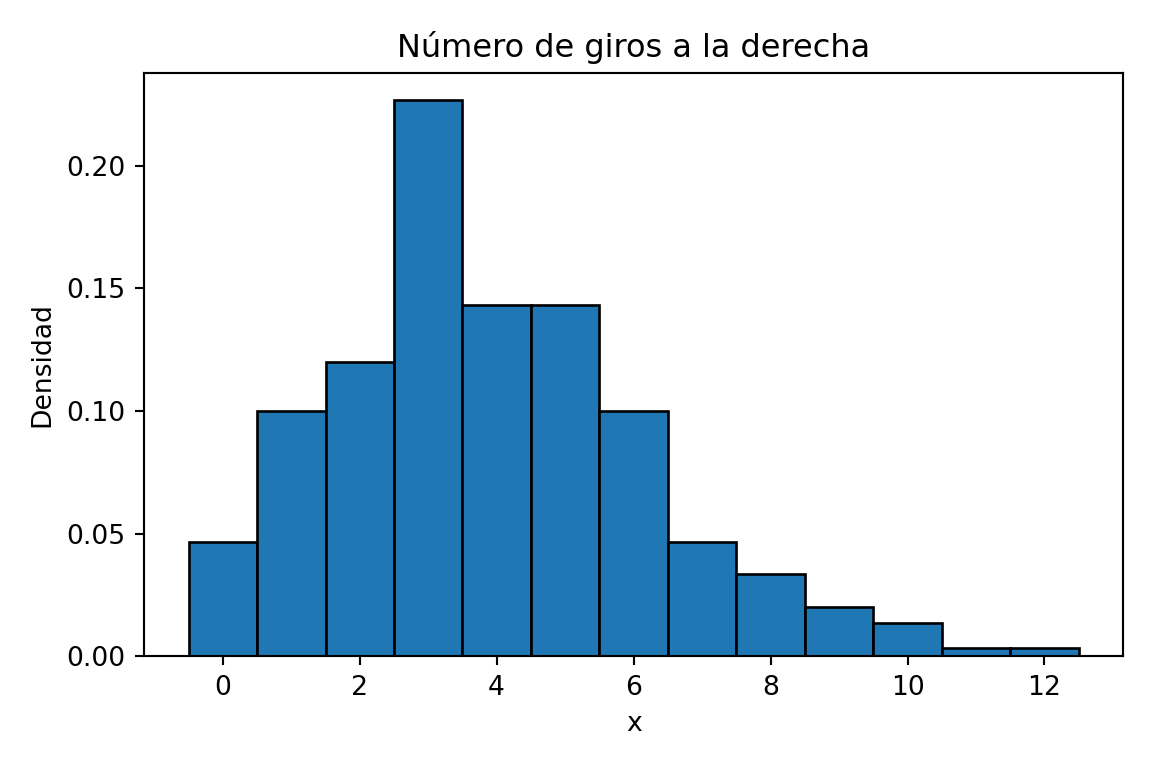
# Neg-log-verosimilitud Poisson: n*lambda - sum(X)*log(lambda) + sum(log(x!))
log_fact_sum = sum(np.log(factorial(int(xi))) for xi in X_py)
def negloglike_pois(lam):
return n_pois * lam - X_py.sum() * np.log(lam) + log_fact_sum
result = minimize_scalar(negloglike_pois, bounds=(0.01, 20), method="bounded")
lambda_hat_py = result.xprint(f"MLE numérico: {lambda_hat_py:.6f}")MLE numérico: 3.893333print(f"Media muestral (MoM): {X_py.mean():.6f}")Media muestral (MoM): 3.893333| Concepto | Definición / Fórmula | Propiedad clave |
|---|---|---|
| Función de verosimilitud | \(L(\theta\mid X) = \prod_{i=1}^n f(X_i\mid\theta)\) | Mide compatibilidad de \(\theta\) con los datos |
| Log-verosimilitud | \(\ell(\theta\mid X) = \sum_{i=1}^n \ln f(X_i\mid\theta)\) | Equivalente a \(L\); más fácil de derivar |
| MLE | \(\hat\theta = \arg\max_\theta \ell(\theta\mid X)\) | Resolver \(\partial\ell/\partial\theta = 0\), verificar \(\partial^2\ell/\partial\theta^2 < 0\) |
| MLE exponencial \(\text{Exp}(\theta)\) | \(\hat\theta = \bar{X}_n\) | Segunda derivada \(= -n^3/y^2 < 0\) |
| MLE normal \(\mu\) (\(\sigma^2\) conocida) | \(\hat\mu = \bar{X}_n\) | Función cuadrática → único máximo global |
| MLE normal \(\sigma^2\) | \(\hat\sigma^2 = \frac{1}{n}\sum(X_i - \bar{X}_n)^2\) | Estimador sesgado (divisor \(n\), no \(n-1\)) |
| MLE uniforme \([0,\theta]\) | \(\hat\theta = X_{(n)} = \max\{X_1,\dots,X_n\}\) | MLE en frontera, no por derivación |
| Invarianza | \(g(\hat\theta)\) es MLE de \(g(\theta)\) para cualquier \(g\) | No requiere re-derivar |
| Consistencia | \(\hat\theta_{MLE} \xrightarrow{\mathbb{P}} \theta\) cuando \(n\to\infty\) | Requiere \(\text{Var}\to 0\) y \(\text{Bias}\to 0\) |
| Estimador de momentos | \(\hat\theta = M(m_1,\dots,m_k)\) | Consistente; alternativa cuando MLE no tiene forma cerrada |