Las tablas de contingencia son una herramienta poderosa en estadística inferencial para analizar la relación entre dos variables categóricas. En este capítulo, aprenderemos cómo realizar una prueba para determinar si dos variables categóricas son independientes utilizando R.
Este capítulo aplica la distribución \(\chi^2\) y la lógica de pruebas de hipótesis (errores tipo I y II) que ya hemos estudiado, ahora al caso de variables categóricas.
NotaObjetivos de aprendizaje
Al terminar este capítulo, seré capaz de:
Identificar cuándo un problema requiere una tabla de contingencia y reconocer su notación (\(N_{ij}\), marginales, \(p_{ij}\)).
Explicar la diferencia conceptual entre la prueba de independencia y la de homogeneidad.
Calcular los valores esperados \(\hat E_{ij}\) y el estadístico \(\chi^2\) a mano y con R.
Aplicarchisq.test e interpretar correctamente el valor-\(p\) y la región de rechazo.
Analizar la fuerza de asociación con la V de Cramér y reconocer la paradoja de Simpson al agregar/desagregar datos.
14.1 Definición y notación
Antes de avanzar, necesitamos definir algunos términos y notaciones que usaremos a lo largo de este capítulo:
Definición 14.1 (Tabla de Contingencia) Un arreglo bidimensional en el que cada observación se puede clasificar de dos o más formas, generalmente a lo largo de filas y columnas.
Introducimos la siguiente notación:
\(R\) representa el número de filas en la tabla.
\(C\) representa el número de columnas en la tabla.
\(N_{ij}\) representa el número de individuos en la muestra clasificados en la fila \(i\) y columna \(j\).
\(N_{i+}\) representa el total de individuos en la fila \(i\), calculado como \(\displaystyle N_{i+} = \sum_{j=1}^{C}N_{ij}\).
\(N_{+j}\) representa el total de individuos en la columna \(j\), calculado como \(\displaystyle N_{+j} = \sum_{i=1}^{R}N_{ij}\).
\(n\) representa el total de observaciones, calculado como \(\displaystyle \sum_{i=1}^R\sum_{j=1}^C N_{ij} = n\).
Además, definimos:
\(p_{ij}\) como la probabilidad de que un individuo en la población pertenezca a la celda \(i,j\), con \(i=1,\dots,R\); \(j=1,\dots, C\).
\(p_{i+}\) como la probabilidad de que un individuo en la población se clasifique en la fila \(i\), calculado como \(\displaystyle\mathbb P[\text{Individuo se clasifique en la fila }i] = \sum_{j=1}^C p_{ij}\).
\(p_{+j}\) como la probabilidad de que un individuo en la población se clasifique en la columna \(j\), calculado como \(\displaystyle\mathbb P[\text{Individuo se clasifique en la columna }j] = \sum_{i=1}^R p_{ij}\).
Note que la suma de todas las probabilidades \(p_{ij}\) es igual a 1, es decir, \(\displaystyle \sum_{i=1}^R\sum_{j=1}^Cp_{ij} = 1\).
Ejemplo 14.1 (Votaciones universitarias) Para ilustrar este concepto, consideremos un ejemplo con una muestra de 200 estudiantes de una universidad. La muestra se categoriza según dos variables: el currículum del estudiante (área de estudio) y su candidato preferido en unas elecciones universitarias (A, B o Indeciso). Los datos se presentan en la siguiente tabla de contingencia:
Área/Candidato
A
B
Indeciso
Totales
Ingeniería
24
23
12
59
Humanidades
24
14
10
48
Artes
17
8
13
38
Administración
27
19
9
55
Totales
92
64
44
200
Para ilustrar estos conceptos con nuestro ejemplo, podemos interpretar:
\(N_{11} = 24\) como los estudiantes de ingeniería que planean votar por el candidato A.
\(N_{2+} = 48\) como el total de estudiantes de Humanidades.
\(N_{+3} = 44\) como el total de estudiantes que se encuentran indecisos sobre a quién votar.
\(n = N_{++} = 200\) como el total de estudiantes en la muestra.
Este marco nos proporciona un lenguaje común y un conjunto de herramientas para describir y analizar las relaciones entre variables categóricas. En las siguientes secciones, aprenderemos cómo usar estos conceptos y notaciones para realizar pruebas estadísticas que nos ayuden a entender si las variables categóricas son independientes o si están relacionadas de alguna manera.
14.2 Prueba de independencia
Después de familiarizarnos con las tablas de contingencia, pasemos a la prueba de independencia, un método fundamental para determinar si dos variables categóricas son independientes.
La hipótesis nula \(H_0\) que queremos probar es:
\[
H_0: p_{ij} = p_{i+}\cdot p_{+j},\;i=1,\dots,R \; ;j=1,\dots, C
\]
Esta hipótesis sugiere que las probabilidades conjuntas de la tabla de contingencia son el producto de las probabilidades marginales, lo cual implica que las variables son independientes. Para llevar a cabo esta prueba, podemos “vectorizar” la tabla de contingencia y emplear una distribución multinomial. Similar al caso de las pruebas parametrizadas, tenemos una prueba con parámetros \(p_{ij}\) que debemos estimar. Por lo tanto lo primero que debemos hacer es encontrar los estimadores de máxima verosimilitud del problema.
La verosimilitud y log-verosimilitud de nuestra distribución multinomial es respectivamente:
Para maximizar esta suma, se debe tomar en cuenta las restricciones \(\sum_{i=1}^R p_{i+} = 1\) y \(\sum_{j=1}^C p_{+j} = 1\). Para esto, se usan multiplicadores de Lagrange con la función:
Note que \(L\) está divido en dos sumando que dependen solo de \(p_{i+}\) y \(p_{+j}\) respectivamente. Para encontrar el gradiente primero vamos a derivar con respecto a \(p_{i+}\).
El mismo razonamiento nos lleva a \[\begin{equation*}
\hat{p}_{+j} = \dfrac{N_{+j}}{n}
\end{equation*}\]
Para definir el número de grados de libertad, recuerde que el número de celdas es \(k=RC\). Ahora el número de párametros para estimar dentro de la verosimilitud \(H_0\) es \(s =(R-1)+(C-1) = R+C-2\). Por lo tanto el número de grados de libertad es \(k-s-1 = RC-(R+C-2)-1 = (R-1)(C-1)\).
El MLE para el conteo en la celda \(i,j\) (valor esperado bajo \(H_0\)) es
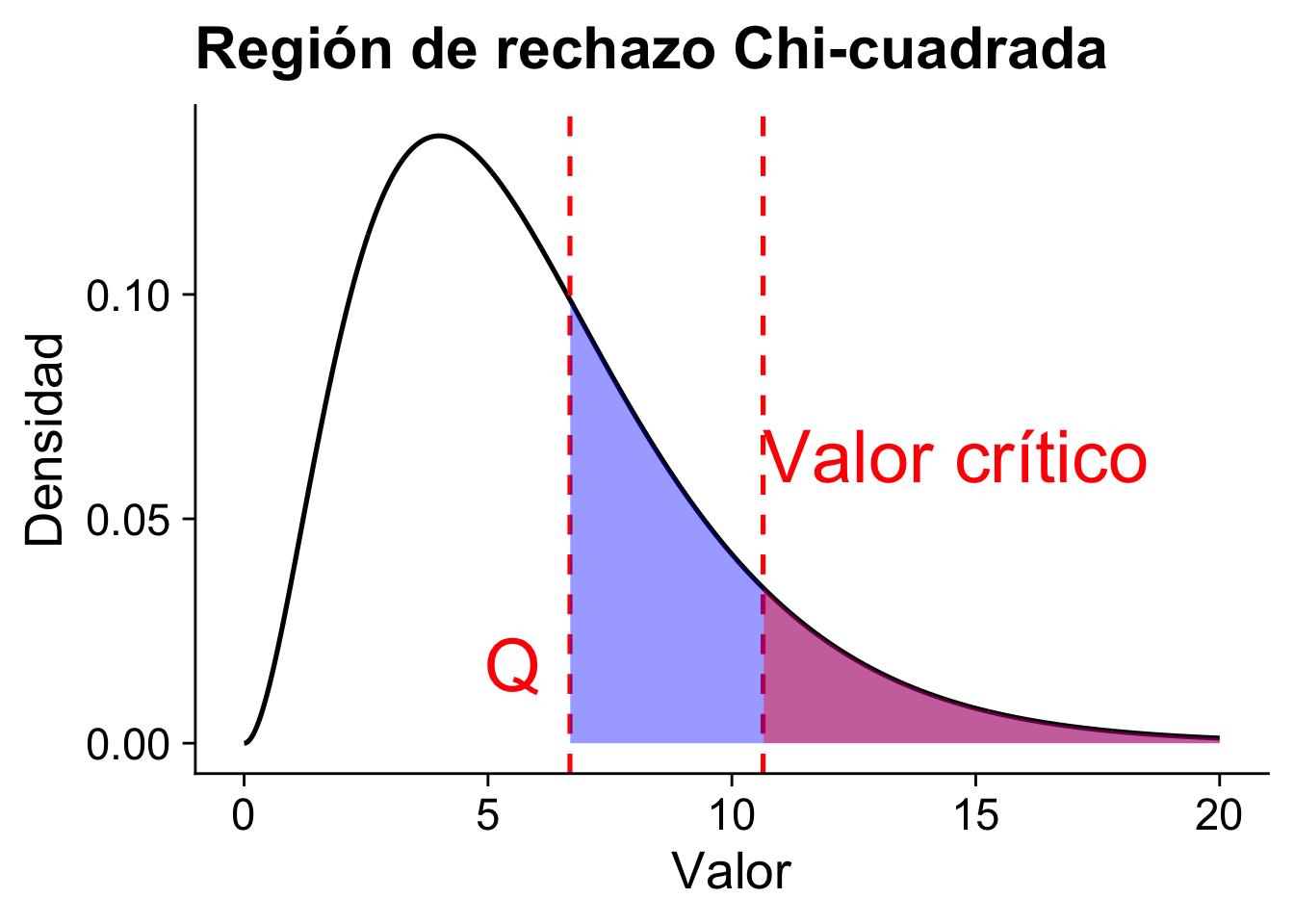
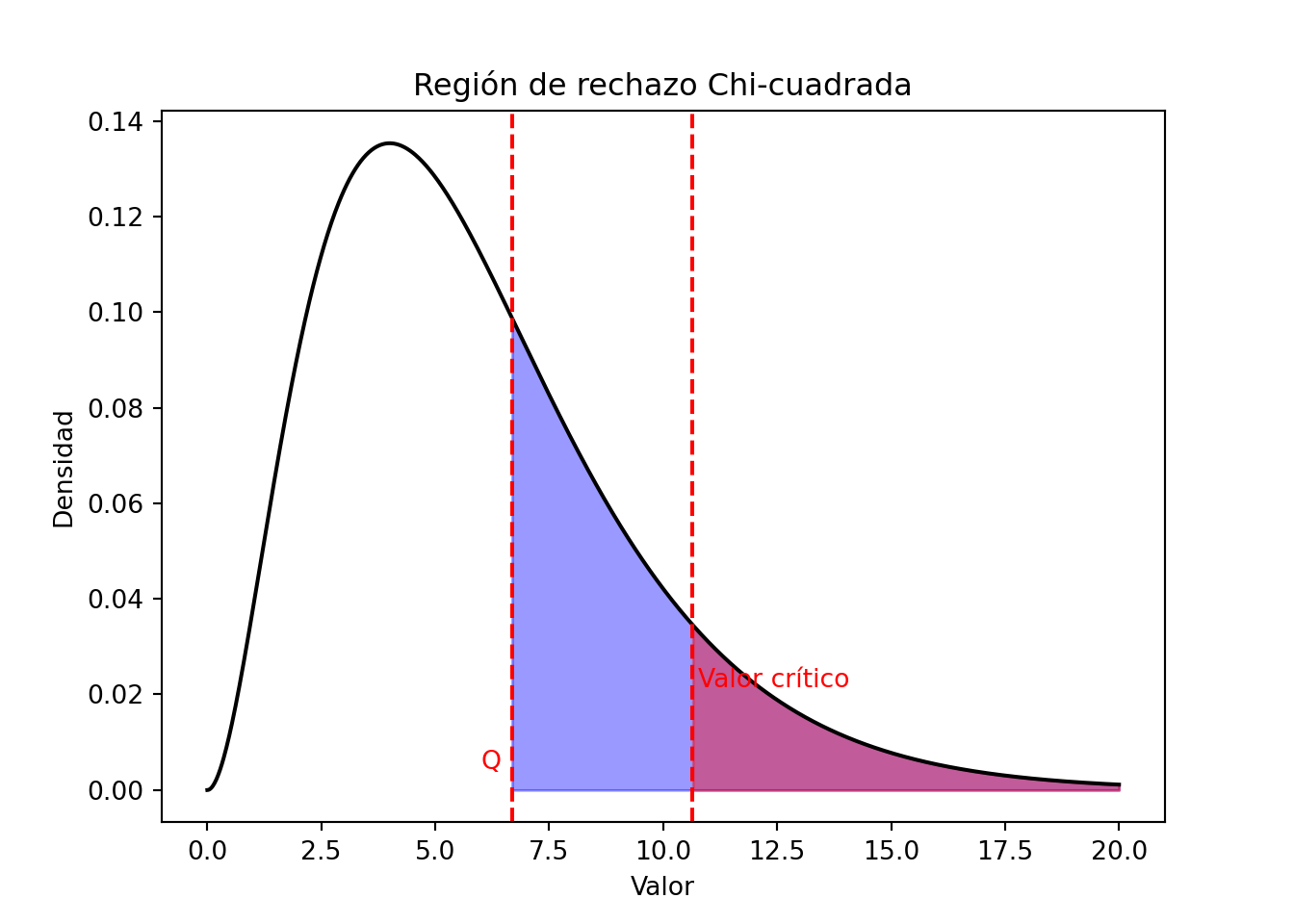
Para un dado nivel de significancia \(\alpha\), rechazamos \(H_0\) si \(Q>\chi^2_{(R-1)(C-1), 1-\alpha}\).
NotaResumen de la prueba de independencia
En este caso, estamos utilizando una tabla de contingencia con \(R\) filas y \(C\) columnas, lo que nos da un total de \(RC\) celdas o contingencias posibles.
El término \(k-s-1\) es el número de grados de libertad en la prueba de \(\chi^2\), donde \(k\) es el número total de celdas y \(s\) es el número de parámetros que se estiman en la hipótesis nula. En otras palabras:
\(k = RC\) es simplemente el número total de celdas en la tabla de contingencia.
\(s\) es el número de parámetros que se estiman bajo la hipótesis nula, que es \(R+C-2\). Aquí, \(R-1\) son las probabilidades marginales para las filas y \(C-1\) son las probabilidades marginales para las columnas. Se resta \(2\) debido a las restricciones que resultan de que las sumas de las probabilidades marginales deben ser \(1\) (una para las filas y otra para las columnas).
Esto nos da el número de grados de libertad en la prueba de \(\chi^2\). Los grados de libertad se refieren a la cantidad de valores en la prueba final de \(\chi^2\) que son libres de variar. En este caso, estamos tomando el número total de celdas y restando las restricciones impuestas por las sumas de las probabilidades marginales y una unidad adicional debido a la hipótesis nula de independencia.
Ejemplo 14.2 (Votaciones universitarias) Aplicando estos conceptos a nuestro ejemplo de estudiantes universitarios, calculamos los valores esperados de cada celda bajo \(H_0\). Como muestra se da el cálculo para las celdas \(E_{11}\) y \(E_{32}\):
Luego, calculamos el estadístico de prueba \(Q\) sumando los cuadrados de las diferencias entre las observaciones y los valores esperados, cada una dividida por su respectivo valor esperado. En nuestro ejemplo, obtenemos:
Si asumimos un nivel de significancia de 10% entonces el valor crítico es \(\chi^2_{(4-1)(3-1)}(0.9) = \chi^2_6(0.9) = 10.64\).
El valor-\(p\) asociado con este estadístico de prueba es \(1- F_{\chi^2_6}(6.68) \approx 0.35\). Como \(Q = 6.68 < 10.64 = \chi^2_6(0.9)\) (equivalentemente, el valor-\(p \approx 0.35 > 0.10\)), no rechazamos la hipótesis de independencia entre el currículum y la preferencia electoral a un nivel de significancia del 10%. No hay evidencia suficiente para afirmar que el área de estudio y la preferencia de voto estén asociadas.
Tip“No rechazar” no es lo mismo que “aceptar \(H_0\)”
Cuando \(Q\) cae fuera de la región de rechazo, decimos que no rechazamos\(H_0\), pero esto no demuestra que las variables sean independientes. Significa únicamente que los datos no aportan evidencia suficiente en contra de la independencia.
Es la misma lógica que un juicio: “no hay pruebas suficientes para condenar” no equivale a “el acusado es inocente”. Podría existir una relación débil que esta muestra no alcanza a detectar; con un tamaño de muestra mayor o un efecto más fuerte, la conclusión podría cambiar. Por eso es incorrecto escribir “aceptamos \(H_0\)” o “las variables son independientes”: lo correcto es “no rechazamos \(H_0\)” o “no hay evidencia de asociación”.
Estos análisis se pueden realizar eficientemente en R utilizando la función chisq.test. Primero, definimos la tabla de datos:
Observe que el X-squared = 6.685 que reporta R coincide con el \(Q = 6.68\) calculado a mano, y el p-value = 0.351 con nuestro valor-\(p \approx 0.35\).
En muchos estudios estadísticos, puede ser de interés determinar si diferentes poblaciones tienen la misma distribución para ciertas variables. En estadística, utilizamos la Prueba de Homogeneidad para este propósito.
NotaObjetivo de la prueba
Supongamos que seleccionamos individuos de varias poblaciones y observamos una variable aleatoria discreta para cada uno. El objetivo de nuestro análisis es determinar si la distribución de esta variable es la misma a través de todas las poblaciones.
Sean \(R\) el número de poblaciones (filas) y \(C\) el número de categorías de la variable (columnas). Definimos \(p_{ij}\) como la probabilidad de que una observación pertenezca a la i-ésima población y a la categoría \(j\). Estas probabilidades deben sumar 1 para cada población \(i\), es decir, \(\sum_{j=1}^Cp_{ij} = 1\), para \(i=1,\dots,R\).
La hipótesis nula, \(H_0\), dice que las probabilidades para cada categoría \(j\) son las mismas en todas las poblaciones, es decir, \(p_{1j} = p_{2j} = \dots = p_{Rj}\) para todas las categorías \(j=1,\dots, C\).
Para una fila fija \(i\) y probabilidades \(p_{ij}\) conocidas, se puede calcular el estadístico del test:
Bajo la hipótesis nula \(H_0\), \(Q^{(i)}\) sigue una distribución \(\chi^2\) con \(C-1\) grados de libertad.
NotaSupuesto
Las poblaciones son independientes. Esto implica que \(Q^{(i)}\) son variables independientes y \[
Q = \sum_{i=1}^R\sum_{j=1}^C\dfrac{(N_{ij}-N_{i+}p_{ij})^2}{N_{i+}p_{ij}}
\] sigue una distribución \(\chi^2\) con \(R(C-1)\) grados de libertad.
Observación. Este resultado proviene del hecho de que la suma de variables \(\chi ^{2}\) sigue una distribución \(\chi ^{2}\) con la suma de sus grados de libertad.
Sin embargo, los valores \(p_{ij}\) generalmente no son conocidos, por lo que debemos estimarlos. La estimación de máxima verosimilitud (MLE) para \(p_{ij}\), dada la hipótesis nula, es \(\hat p_{ij} = \dfrac{N_{+j}}{n}\).
Sustituyendo esto en la ecuación de \(Q\), obtenemos:
donde \(\hat E_{ij} = \dfrac{N_{i+}\cdot N_{+j}}{n}\) es la expectativa estimada del número de observaciones en la i-ésima población y la j-ésima categoría.
Finalmente, los grados de libertad de la prueba son:
\[
k-s-1 = R(C-1)-(C-1) = (R-1)(C-1).
\]
Aquí, \(k\) es el número total de celdas en la tabla de contingencia, y \(s\) es el número de restricciones, que es igual al número de categorías menos uno.
Para concluir el test, se rechaza la hipótesis nula, \(H_0\), si el valor de la estadística del test cae en la región de rechazo. Esta región de rechazo se determina de la misma manera que en la prueba de independencia, es decir, se rechaza \(H_0\) si el valor p es menor que el nivel de significancia preestablecido, a menudo 0.05.
Con este proceso, podemos realizar un test de homogeneidad y determinar si la distribución de una variable discreta es la misma en diferentes poblaciones.
Ejemplo 14.3 Sigamos con un ejemplo anterior en el que se tomaron muestras de tamaño 59, 48, 38 y 55 de cada área. Nos interesa saber si la distribución de la variable ‘preferencia’ es la misma independientemente del área. Es decir, ¿es homogénea la forma en que los estudiantes votan, independientemente de la carrera que están cursando?
Para este caso, el cálculo de \(Q\) es el mismo, con la misma cantidad de grados de libertad (6). Como \(Q = 6.68 < 10.64\), no rechazamos la hipótesis nula: no hay evidencia de que la distribución del voto difiera entre las carreras.
TipIdea clave
Aunque la fórmula de \(\hat E_{ij}\) y de \(Q\) es idéntica a la de independencia, aquí los totales de fila \(N_{i+}\) están fijados por el diseño (decidimos de antemano cuántos individuos muestrear de cada población). Por eso se pierde un grado de libertad por cada fila y se recupera el mismo \((R-1)(C-1)\).
14.4 Comparación entre las Pruebas de Independencia y Homogeneidad
Aunque estas pruebas son similares en muchos aspectos, también tienen diferencias clave en cuanto a su interpretación y aplicación.
14.4.1 Similitudes
Desde un punto de vista computacional, las pruebas de independencia y homogeneidad se calculan de la misma manera. Ambas pruebas se basan en la comparación de las frecuencias observadas y esperadas en una tabla de contingencia, y utilizan la misma estadística de prueba (\(\chi^2\)). Así, en términos de cálculo, ambas pruebas son esencialmente idénticas.
14.4.2 Diferencias
A pesar de su similitud en términos de cálculo, la interpretación de estas dos pruebas es bastante diferente:
Prueba de Independencia:
La prueba de independencia se utiliza para analizar la relación entre dos variables categóricas en una única población.
La hipótesis nula para esta prueba es que las dos variables son independientes, es decir, que la distribución condicional de una variable es la misma para todas las categorías de la otra variable.
Si rechazamos la hipótesis nula en una prueba de independencia, concluimos que hay una asociación entre las dos variables.
Prueba de Homogeneidad:
La prueba de homogeneidad se utiliza para comparar las distribuciones de una variable categórica entre varias poblaciones o grupos.
Cada fila de la tabla de contingencia se considera como una subpoblación distinta.
La hipótesis nula es que todas las subpoblaciones tienen la misma distribución de la variable categórica.
Si rechazamos la hipótesis nula en una prueba de homogeneidad, concluimos que al menos una subpoblación tiene una distribución diferente de las demás.
TipIdeas clave
El cálculo de \(\chi^2\) es idéntico en ambas pruebas; lo que cambia es el diseño muestral y la interpretación.
Independencia: una población, dos variables. Homogeneidad: varias poblaciones, una variable.
Datos pareados (un mismo sujeto medido dos veces) no admiten estas pruebas: requieren métodos como la prueba de McNemar.
14.5 Comparación de proporciones en dos o más grupos
En muchos estudios de investigación, podemos estar interesados en comparar las proporciones de una categoría en dos o más grupos. Estos grupos pueden representar diferentes poblaciones, condiciones de tratamiento, momentos en el tiempo, o cualquier otra división relevante para nuestro estudio.
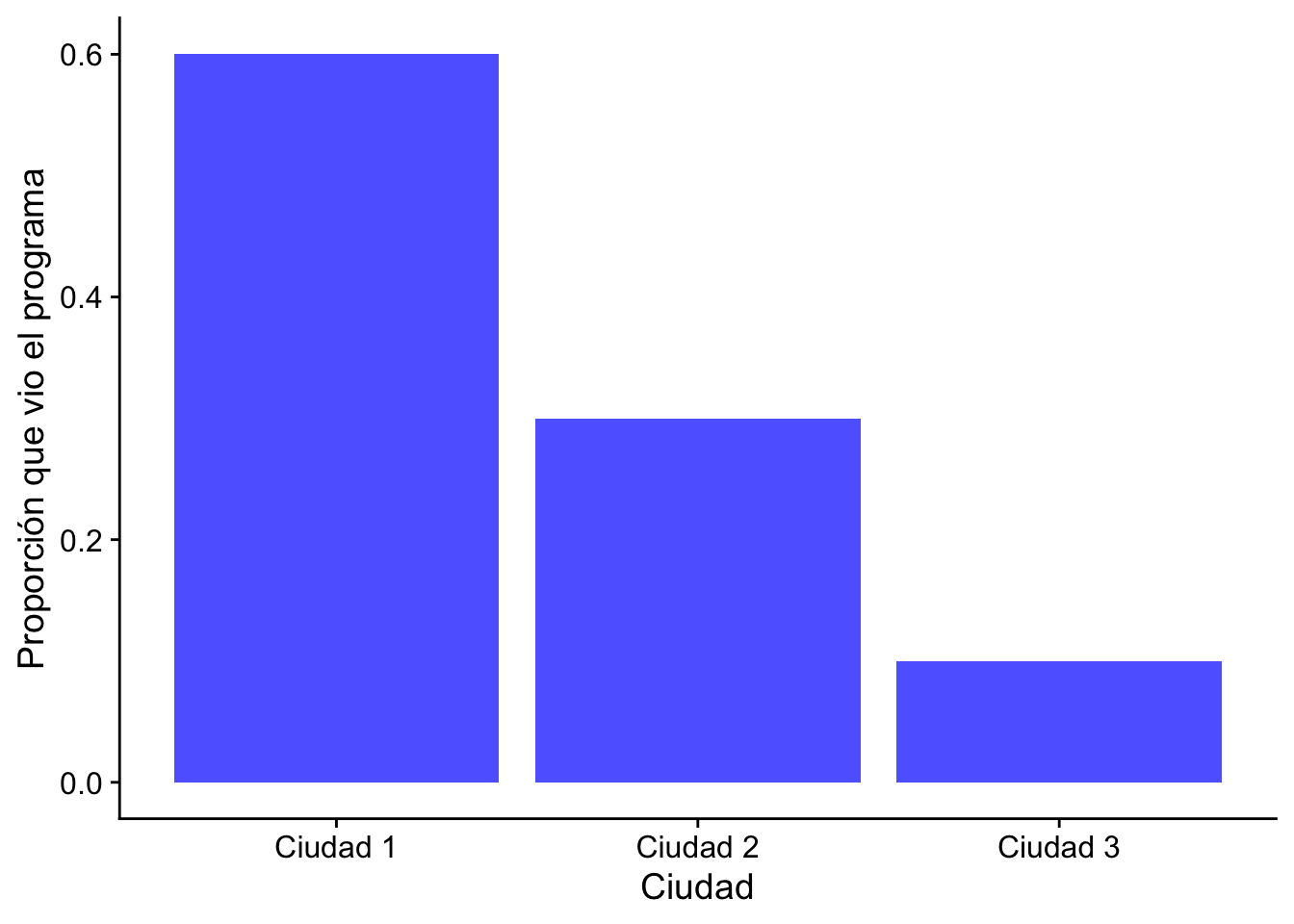
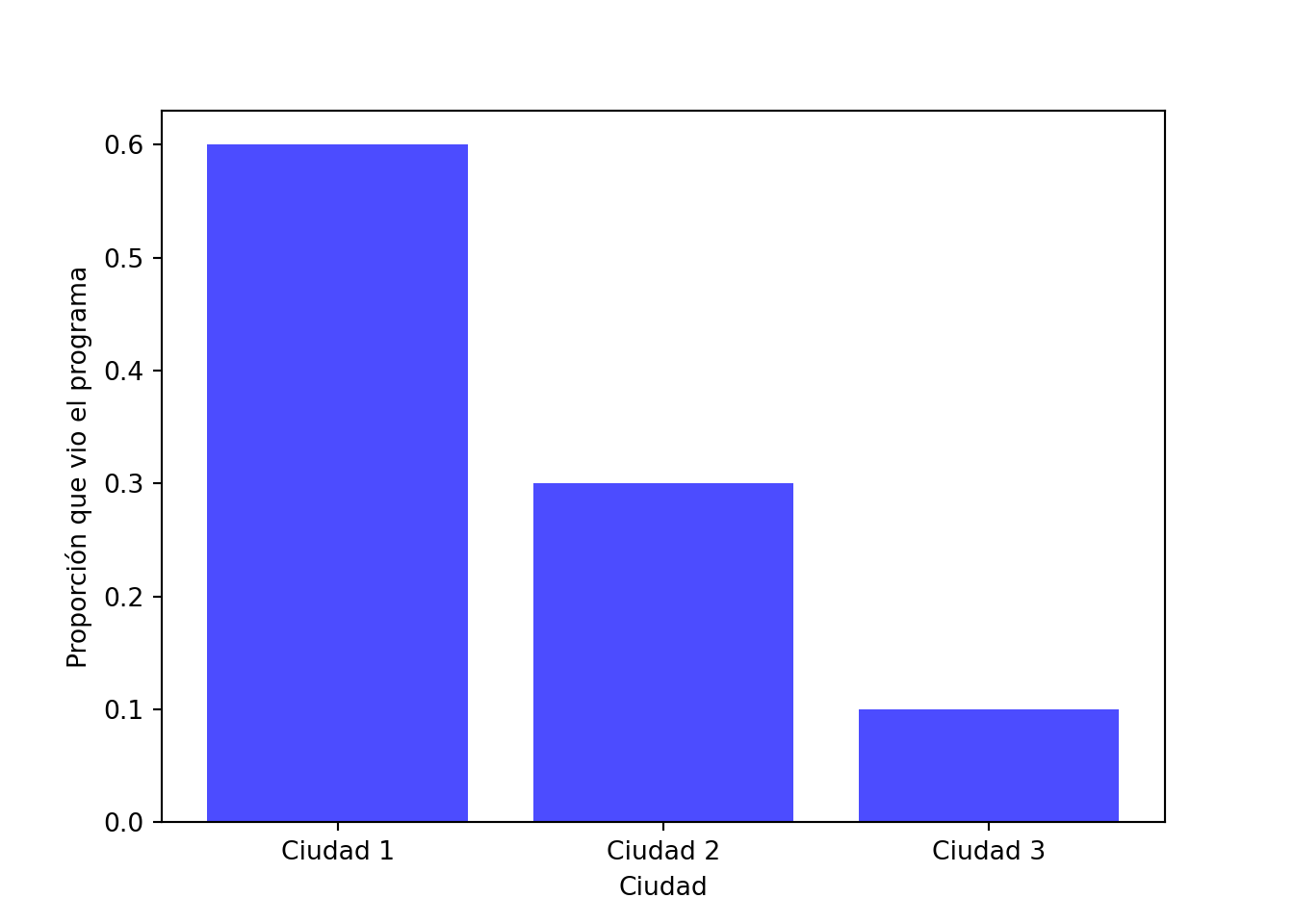
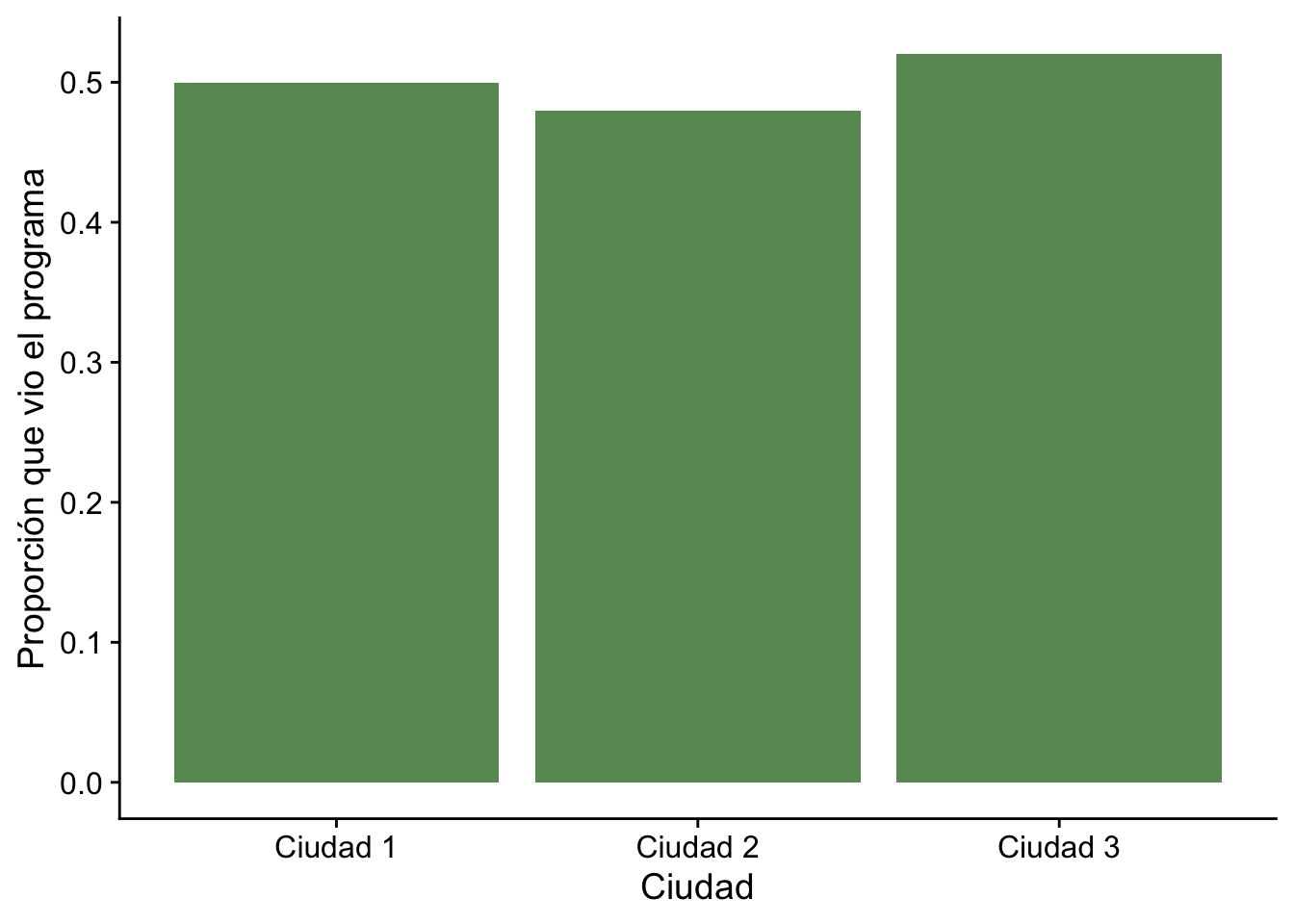
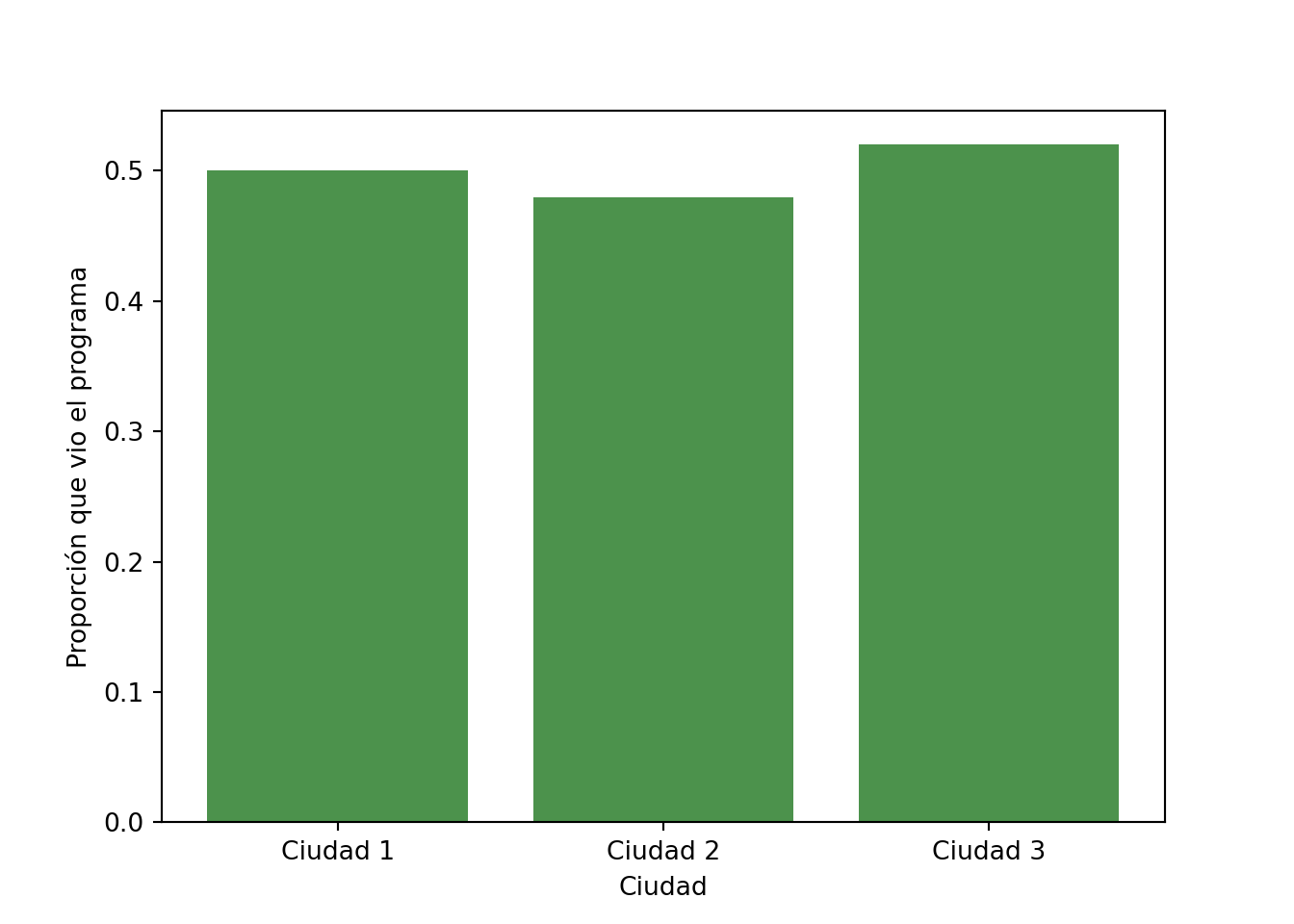
Ejemplo 14.4 Supongamos que realizamos una encuesta en varias ciudades y preguntamos a los encuestados si vieron un determinado programa de televisión. Podemos representar los resultados en una tabla de contingencia como la siguiente:
Ciudad
Vio el programa
No lo vio
1
\(N_{11}\)
\(N_{12}\)
\(\vdots\)
\(\vdots\)
\(\vdots\)
R
\(N_{R1}\)
\(N_{R2}\)
Nos gustaría saber si la proporción de espectadores del programa es la misma en todas las ciudades. Podemos plantear la hipótesis nula de homogeneidad, que afirma que la proporción de espectadores es la misma en todas las ciudades. Para probar esta hipótesis, podemos utilizar la estadística de prueba \(\chi^2\):
Aquí las proporciones (≈0.5 en las tres ciudades) son similares y el valor-\(p\) es alto, por lo que no rechazamos la homogeneidad: no hay evidencia de que la proporción de espectadores difiera entre ciudades.
Ejemplo 14.5 Supongamos que seleccionamos aleatoriamente a 100 personas en una ciudad y les preguntamos si están satisfechas con el trabajo de los bomberos. Posteriormente, ocurre un incendio en la ciudad, y hacemos la misma pregunta a las mismas personas. Los resultados se pueden resumir en la siguiente tabla:
Satisfactorio
No Satisfactorio
Antes del incendio
80
20
Después del incendio
72
28
En este caso, no sería apropiado realizar una prueba de independencia o homogeneidad, ya que los datos son dependientes (la misma persona proporciona medidas antes y después del incendio). En cambio, podríamos estar interesados en responder las siguientes preguntas:
¿Qué proporción de personas cambió su opinión sobre el servicio de bomberos después del incendio?
¿Cuál fue el cambio de opinión más común entre aquellos que cambiaron de opinión?
Para responderlas no basta con la tabla anterior (que solo muestra los totales antes y después): necesitamos cruzar la respuesta de cada persona en ambos momentos. Esa tabla cruzada es:
Después: Satisfactorio
Después: No satisfactorio
Total antes
Antes: Satisfactorio
70
10
80
Antes: No satisfactorio
2
18
20
Total después
72
28
100
A partir de ella, el 12% de las personas (10 de 80 que estaban satisfechas y 2 de 20 que no lo estaban) cambiaron de opinión. Entre estas personas, el 83% (10 de 12) cambió de tener una opinión satisfactoria a una no satisfactoria.
Estos cálculos nos permiten hacer inferencias sobre el cambio de opinión en la población general después del incendio.
14.6 La V de Cramér
La V de Cramér es una medida de la fuerza de asociación entre dos variables nominales. Su valor varía de 0 a 1 donde:
0 indica ninguna asociación entre las dos variables.
1 indica una asociación perfecta entre las dos variables.
La siguiente tabla muestra cómo interpretar la V de Cramér en función de los grados de libertad1:
Grados de libertad
Asociación Pequeña
Asociación Media
Asociación Grande
1
0.10
0.30
0.50
2
0.07
0.21
0.35
3
0.06
0.17
0.29
4
0.05
0.15
0.25
5
0.04
0.13
0.22
Ejemplo 14.6 (Fuerza de asociación en las votaciones universitarias) Retomamos la tabla M de las votaciones (4 áreas × 3 candidatos) para medir la fuerza de la asociación, complementando la prueba \(\chi^2\):
import numpy as npfrom scipy.stats import chi2_contingencychi2, _, _, _ = chi2_contingency(M, correction=False)n = M.sum()r, c = M.shapeV = np.sqrt((chi2 / n) /min(r -1, c -1))print(f"Cramér's V = {V:.4f}")
Cramér's V = 0.1293
Aquí los grados de libertad son \((4-1)(3-1) = 6\). Con \(\chi^2 = 6.68\) y \(n = 200\): \[
V = \sqrt{\dfrac{6.68/200}{\min(4-1,\, 3-1)}} = \sqrt{\dfrac{0.0334}{2}} \approx 0.13.
\] Según la tabla de interpretación (2 g.l.), \(V \approx 0.13\) corresponde a una asociación pequeña, coherente con el no-rechazo de la independencia que obtuvimos antes.
14.7 La paradoja de Simpson
La Paradoja de Simpson es un fenómeno estadístico que puede surgir cuando se trabaja con datos agrupados. Esta paradoja puede generar conclusiones erróneas si no se tiene cuidado al interpretar los resultados. Fue descrita por Edward H. Simpson en 1951, y ha sido utilizada para ilustrar cómo el mal uso de las estadísticas puede generar resultados engañosos. Sin embargo, no es una paradoja en el sentido estricto de la palabra, ya que no hay ninguna contradicción, sino simplemente dos formas diferentes de pensar sobre los mismos datos.
La Paradoja de Simpson puede manifestarse incluso en grandes conjuntos de datos, y su presencia no depende del tamaño de la muestra, sino de la proporción de los datos. Esto puede ocurrir con más frecuencia cuando se trabaja con datos discretos, por eso hay que tener cuidado con la forma en que agrupamos estos.
Ejemplo 14.7 Consideremos un experimento en el que se comparan dos tratamientos para bajar de peso, uno nuevo y otro ya establecido. En total, se toma una muestra de 80 sujetos, 40 de los cuales reciben el nuevo tratamiento y 40 el antiguo. A continuación, se evalúa la mejora en cada paciente.
Mejoró
No mejoró
% mejora
Nuevo
20
20
50
Viejo
24
16
60
Importante
Según los datos globales, el tratamiento antiguo parece tener un porcentaje de mejora mayor que el nuevo.
Sin embargo, si desagregamos los datos según el género de los pacientes, observamos que para los hombres:
Mejoró
No mejoró
% mejora
Nuevo
12
18
40
Viejo
3
7
30
y para mujeres:
Mejoró
No mejoró
% mejora
Nuevo
8
2
80
Viejo
21
9
70
En este caso, tanto para hombres como para mujeres, el tratamiento nuevo muestra una mayor tasa de mejora que el antiguo. Esta es la Paradoja de Simpson en acción: aunque los datos agregados sugieren que el tratamiento antiguo es más efectivo, los datos desagregados por género indican lo contrario.
La desagregación de los datos revela una variable “oculta”, el género, que influye en la efectividad de los tratamientos. En este caso, las mujeres muestran una mayor tasa de mejora que los hombres en ambos tratamientos. Adicionalmente, la mayoría de las mujeres recibieron el tratamiento antiguo, mientras que la mayoría de los hombres recibieron el tratamiento nuevo. A nivel global, el efecto total es mayor porque los hombres tuvieron una mayor influencia en la efectividad del tratamiento antiguo.
Tip
A este proceso de separar las tablas se le conoce como desagregación.
14.7.1 ¿Cómo evitamos esta paradoja?
Para evitar la Paradoja de Simpson, es importante considerar las variables ocultas en los datos y cómo pueden afectar los resultados. En el contexto de la probabilidad condicional, esto implica considerar las interacciones entre diferentes eventos.
Hay un par de condiciones que se deben cumplir para evitar problemas en este caso
Considere los eventos:
“Hombre” si se selecciona a un hombre.
“\(\text{Hombre}^c\)” si se selecciona a una mujer.
“Nuevo” si es el tratamiento nuevo.
“Mejora” si hubo una mejora en el tratamiento.
La paradoja de Simpson nos dice que es posible tener las siguientes desigualdades:
Entonces, podemos expresar la probabilidad de mejora dada la administración del nuevo tratamiento, \(\mathbb P[\text{Mejora}|\text{Nuevo}]\), en términos de las probabilidades de mejora condicionada al género y al tratamiento:
Usando el supuesto \(\mathbb P[\text{Hombre}\mid\text{Nuevo}] = \mathbb P[\text{Hombre}\mid\text{Nuevo}^c]\), los pesos coinciden y la desigualdad anterior se convierte en una igualdad:
Por lo tanto, la paradoja no se cumple en este caso.
En otras palabras para evitar la Paradoja de Simpson, queremos asegurarnos de que la probabilidad total de mejora dado el nuevo tratamiento es mayor que la probabilidad total de mejora dado el tratamiento viejo. Esto se logra asegurándose de que la probabilidad de ser un hombre (o una mujer) es la misma independientemente de si se recibe el tratamiento nuevo o el viejo.
Ejercicio 14.1 Otra forma de evitar la paradoja es si se cumple que \(\mathbb{P}[\text{Nuevo}|\text{Hombre}] = \mathbb{P}[\text{Nuevo}|\text{Hombre}^{c}]\). Esto se deja como un ejercicio.
14.8 Resumen
La siguiente tabla resume los resultados y fórmulas principales del capítulo:
Rechazar \(H_0\) si \(Q > \chi^2_{(R-1)(C-1),\,1-\alpha}\) (o si valor-\(p < \alpha\))
V de Cramér
\(V = \sqrt{\dfrac{\chi^2/n}{\min(r-1,\,c-1)}}\)
Recuerda la distinción clave: la prueba de independencia estudia dos variables en una sola población, mientras que la de homogeneidad compara la distribución de una variable entre varias poblaciones; ambas se calculan igual, pero se interpretan distinto. Para datos pareados (mismo sujeto medido dos veces) estas pruebas no aplican. Finalmente, la paradoja de Simpson advierte que agregar o desagregar datos puede invertir las conclusiones, por lo que conviene vigilar las variables ocultas.