Recordar qué es una distribución muestral y distinguirla de la distribución poblacional.
Comprender por qué los estadísticos como \(\bar{X}_n\) y \(\hat\sigma^2\) tienen distribuciones propias que dependen de \(n\).
Aplicar las distribuciones \(\chi^2\) y \(t\) de Student para calcular probabilidades sobre estimadores en muestras normales.
Analizar cuándo usar la distribución \(t\) en lugar de la normal y qué consecuencia tiene el desconocimiento de \(\sigma\).
Comparar los enfoques bayesiano y frecuentista para construir distribuciones muestrales de un estimador.
Este capítulo responde una pregunta central: si tomamos una muestra diferente, ¿cuánto cambia nuestro estimador? En capítulos anteriores aprendimos a construir estimadores puntuales (MLE, método de momentos, estimadores de Bayes). Aquí desarrollamos las herramientas para cuantificar su variabilidad: la distribución muestral, la distribución \(\chi^2\) y la distribución \(t\) de Student. Estas tres herramientas son los cimientos de los intervalos de confianza y las pruebas de hipótesis que se verán en los capítulos siguientes.
8.1 Distribución muestral
La distribución muestral de un estadístico se refiere a la distribución de dicho estadístico basada en todas las posibles muestras de un tamaño dado que se pueden obtener de una población.
Formalmente, si \(X_1,\dots,X_n\) es una muestra con parámetro desconocido \(\theta\), y \(T=r(X_1,\dots,X_n,\theta)\), entonces la distribución de \(T\) dado \(\theta\) se llama distribución muestral.
Ejemplo 8.1 Considere una población con distribución \(N(\mu,\sigma^2)\) con \(\sigma^2\) conocido. El estimador de máxima verosimilitud (MLE) de \(\mu\) es:
La distribución muestral de \(\bar{X}_n\) es \(N\left(\mu,\dfrac{\sigma^2}{n}\right)\), donde \[\begin{align*}
\mathbb E[\bar{X}_n] & = \dfrac 1n\displaystyle\sum_{i=1}^n\mathbb E[X_i] = \dfrac
1n\cdot n \mathbb E[X_1] = \mu \\
\text{Var}(\bar{X}_n) & = \text{Var}\left(\dfrac 1n \displaystyle\sum_{i=1}^n
X_i\right) = \dfrac{1}{n^2}\cdot n\cdot \text{Var}(X_1) = \dfrac{\sigma^2}{n}.
\end{align*}\]
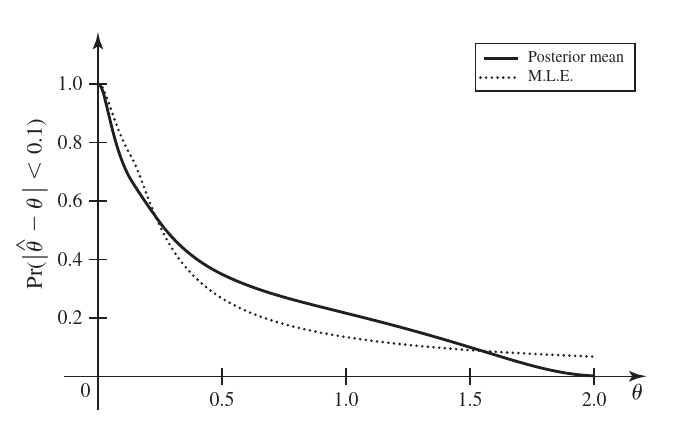
Ejemplo 8.2 Suponga que \(X_i\) para \(i=1, 2, 3\) es el tiempo de vida de un aparato, cuya distribución es \(\text{Exp}(\theta)\). Para ilustrar los cálculos de forma manejable fijamos \(n=3\) observaciones; el procedimiento se generaliza a cualquier \(n\). Suponga que queremos estimar \(\mathbb P(|\hat\theta-\theta|<0.1)\). Este ejemplo ilustra cómo los dos enfoques de la inferencia —frecuentista y bayesiano— responden a la misma pregunta de forma distinta, usando la distribución muestral como herramienta común. Usemos los enfoques bayesianos y frecuentistas para resolver el problema.
8.1.1 Enfoque bayesiano
Suponga que la previa de \(\theta\) es \(\Gamma(1,2)\). La posterior sería
Observación. Recuerde que sumas de exponenciales es una gamma. (Ver teorema 5.7.7 del libro).
Entonces \(T=\sum_{i=1}^{3}X_{i}\sim \Gamma(3,\theta)\), por lo que \(F(t|\theta) =
1-G_{\Gamma(3,\theta)}\left( \dfrac 4t-2\right)\). Aqui denotamos como \(G\) a la distribución de \(T\).
Si θ = 1, entonces
P(|θ̂_Bayes - θ| < 0.1) ≈ 0.2143
8.1.2 Enfoque frecuentista
Otra solución es estimar la probabilidad de que \(\theta\) y \(\hat{\theta}\) estén cerca de forma relativa. Usando el MLE \(\hat{\theta} = \frac{3}{T}\), se podría construir esa probabilidad de forma que no dependa de \(\theta\).
Si \[\begin{equation*}
T\sim\Gamma(3,\theta)
\end{equation*}\] entonces \(\theta T \sim \Gamma(3,1)\).
Por lo tanto, \[
\Delta = \mathbb P \left(0.9<\dfrac 3{\theta T}<1.1\bigg|\theta\right) = \mathbb P \left(\dfrac 3{1.1}<\theta T<\dfrac 3{0.9}\right) = 13,4\%
\]
TipIdeas clave: distribución muestral
La distribución muestral de un estadístico describe cómo varía ese estadístico sobre todas las posibles muestras del mismo tamaño \(n\).
Un estimador es una variable aleatoria: tiene su propia distribución, esperanza y varianza.
El enfoque frecuentista trabaja con la distribución condicional dado \(\theta\) fijo; el bayesiano promedia sobre la distribución del parámetro.
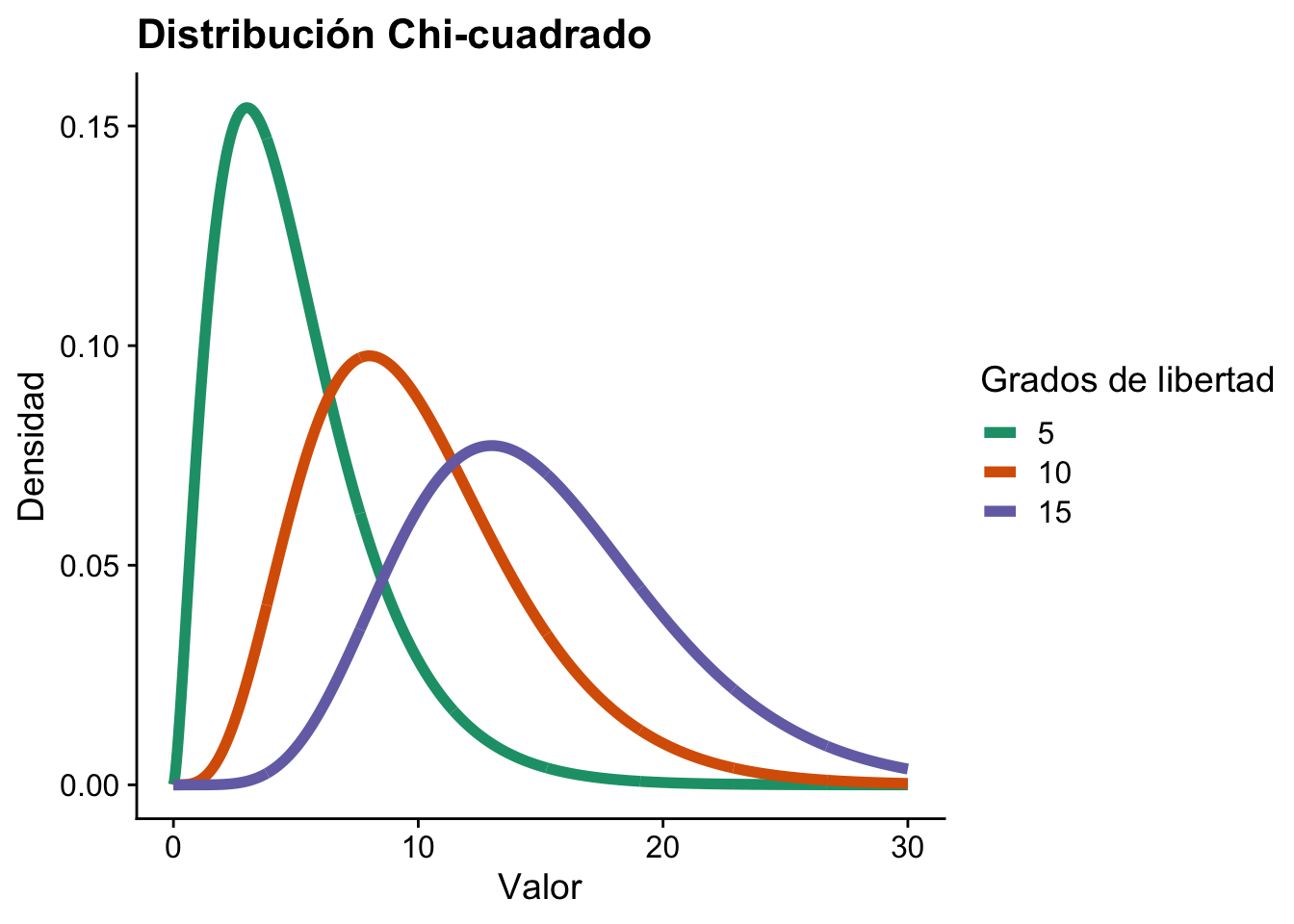
8.2 Distribución \(\chi^2\)
La distribución \(\chi^2\) surge de forma natural cuando trabajamos con varianzas muestrales de poblaciones normales. Si queremos construir un intervalo de confianza para \(\sigma^2\), o comparar varianzas de dos poblaciones, necesitamos conocer la distribución del estadístico \(\sum(X_i - \bar{X}_n)^2/\sigma^2\). El resultado clave es que este estadístico sigue exactamente una distribución \(\chi^2\), que definimos a continuación.
La distribución chi-cuadrado o \(\chi^2\)-cuadrado es una distribución especial de la familia gamma. Se define como:
# Generar datos para distintos grados de libertadx <-seq(0, 30, length.out =1000)df_values <-c(5, 10, 15) # Grados de libertad a ilustrardensities <-lapply(df_values, function(df) {dchisq(x, df)})# Convertir a data.frame para ggplotdf <-data.frame(x =rep(x, length(df_values)),density =unlist(densities),df =factor(rep(df_values, each =length(x))))# Graficar la densidad χ² para cada grado de libertadggplot(df, aes(x = x, y = density, color = df)) +geom_line(linewidth =2) +labs(title ="Distribución Chi-cuadrado",x ="Valor",y ="Densidad",color ="Grados de libertad" ) + cowplot::theme_cowplot() +scale_color_brewer(palette ="Dark2")
Código
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import chi2x = np.linspace(0, 30, 1000)df_values = [5, 10, 15] # Grados de libertad a ilustrarcolors = ["#1b9e77", "#d95f02", "#7570b3"]fig, ax = plt.subplots(figsize=(8, 5))for df, color inzip(df_values, colors):# Densidad χ²_df en cada punto ax.plot(x, chi2.pdf(x, df=df), linewidth=2, color=color, label=f"df = {df}")ax.set_xlabel("Valor")ax.set_ylabel("Densidad")ax.set_title("Distribución Chi-cuadrado")ax.legend(title="Grados de libertad")ax.spines[["top", "right"]].set_visible(False)plt.tight_layout()plt.show()
Estas distribuciones tiene propiedades interesantes que se enuncian a continuación.
NotaPropiedades
\(\mathbb E[X] = m\).
\(\text{Var} (X) = 2m\).
Para \(X_i \sim \chi^2_{m_i}\), \(i = 1,\dots, k\), independientes, entonces \[
\sum_{i=1}^k X_i \sim \chi^2_{\sum m_i}
\]
Si \(X\sim N(0,1) \implies Y = X^2\sim \chi^2_1\).
Si \(X_i \stackrel{i.i.d}{\sim} N(0,1) \implies \sum_{i=1}^m X_i^2 = \chi^2_m\).
Ejemplo 8.3 Consideremos una muestra \(X_1,\dots,X_n\) de una distribución normal \(N(\mu,\sigma^2)\). Si transformamos cada observación como \(Z = \dfrac{X_i-\mu}{\sigma}\), cada \(Z\) sigue una distribución \(N(0,1)\).
Por lo tanto, la suma de los cuadrados de estas transformaciones sigue una distribución chi-cuadrado con \(n\) grados de libertad:
En el ejercicio anterior el \(\mu\) es conocido. Si suponemos que \(\mu\) es desconocido. Entonces, ¿Cuál es la distribución muestral de \((\bar{X}_n,\hat\sigma^2)\)? EL siguiente cuadro resume sus propiedades.
NotaMás propiedades de las distribuciones \(\chi^2\)
Bajo las condiciones anteriores,
\(\bar{X}_n\) y \(\hat\sigma^2_n\) son independientes aunque \(\hat\sigma^2_n\) es función de \(\bar{X}_n\).
La distribución muestral de \(\bar{X}_n\) es \(N\left(\mu,\dfrac{\sigma^2}{n}\right)\).
Si \(\hat{\sigma}^2 = \dfrac{1}{n}\displaystyle\sum_{i=1}^n(X_i - \bar{X}_n)^2\), entonces \[\begin{equation*}
\dfrac{n\hat{\sigma}^2}{\sigma^2} = \sum_{i=1}^n \dfrac{(X_i-\bar{X}_n)^2}{\sigma^2} \sim \chi^2_{n-1}.
\end{equation*}\]Los \(n-1\) grados de libertad reflejan que se pierde uno al reemplazar \(\mu\) (desconocido) por \(\bar{X}_n\).
Los siguientes resultados son específicos de la distribución normal y no se cumplen en general para otras distribuciones. En particular, la independencia de \(\bar{X}_n\) y \(s^2_n\) es una propiedad notable: aunque \(s^2_n\) se calcula usando \(\bar{X}_n\), ambos estadísticos son independientes. La primera propiedad solo ocurre con distribuciones normales. La prueba no es difícil y es interesante entenderla. Para probarla necesitamos un resultado de álgebra lineal: cualquier transformación ortogonal de variables normales estándar independientes produce nuevamente variables normales estándar independientes. La siguiente proposición hace esto preciso.
Proposición 8.1 Una matriz \(A_{n\times n}\) es ortogonal si cumple que \(A^{-1} = A^T\) (equivalentemente, \(A^TA = I\)). En ese caso \(\det(A) = \pm 1\). Además si \(X, Y\in \mathbb R ^{n}\), y definimos \(AX =Y\) con \(A\) ortogonal, entonces \[
\|Y\|_2^2 = \|X\|_2^2.
\]
Teorema 8.1 Si \(X_1,\dots,X_n \sim N(0,1)\), \(A\) es ortogonal \(n\times n\) y \(Y=AX\) donde \(X = (X_1,\dots,X_n)^T\) entonces \(Y_1,\dots,Y_n \sim N(0,1)\).
NotaPrueba
Si \(X_1,\dots,X_n \sim N(0,1)\), use Gram-Schmidt con vector inicial
\[\begin{equation*}
u = \left[ \frac{1}{\sqrt{n}}, \cdots, \frac{1}{\sqrt{n}}\right]
\end{equation*}\]
Como \(Y_1^2\) y \(\sum_{i=2}^nY_i^2\) son independientes, entonces \(\bar{X}_n\) y \(\dfrac{1}n \sum_{i=1}^n(X_i-\bar{X}_n)^2\) son independientes.
Note que \(\sum_{i=2}^n Y_i^2 \sim \chi^2_{n-1}\) ya que \(Y_i \stackrel{i.i.d}{\sim} N(0,1)\).
Si \(X_1,\dots,X_n \sim N(\mu, \sigma^2)\), tome \(Z_i = \dfrac{X_i-\mu}\sigma\) y repita todo lo anterior.
Este resultado implica directamente que \(\bar{X}_n\) y \(s^2_n\) son independientes en muestras normales: \(\bar{X}_n\) es función de \(Y_1\) (la primera componente transformada), mientras que \(s^2_n\) es función de \(Y_2,\dots,Y_n\), y todas son independientes por el teorema anterior.
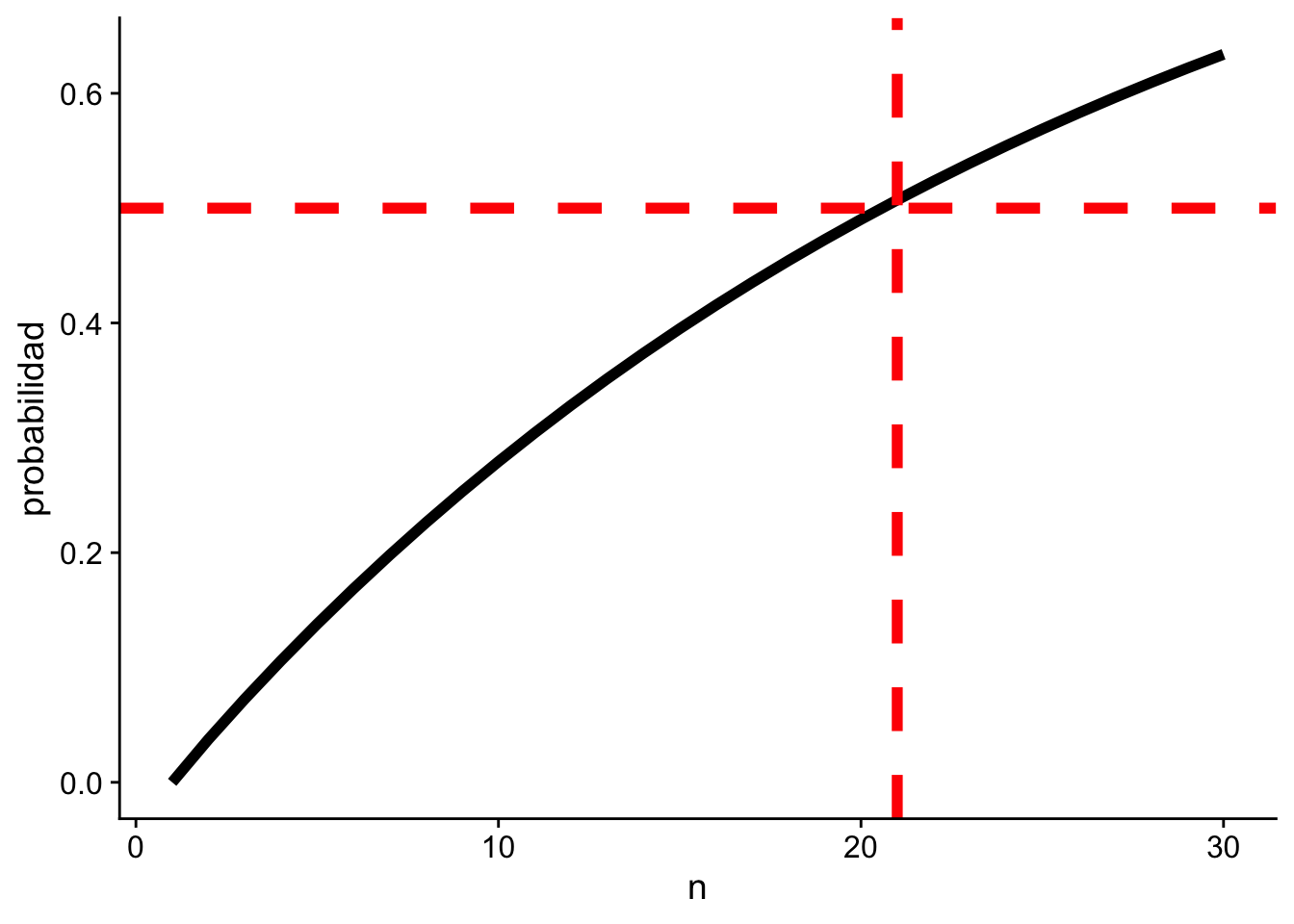
Ejemplo 8.4 Sea \(X_1,\dots,X_n\sim N(\mu,\sigma^2)\) (\(\mu,\sigma\) desconocidos). Los MLE son
\[\begin{equation*}
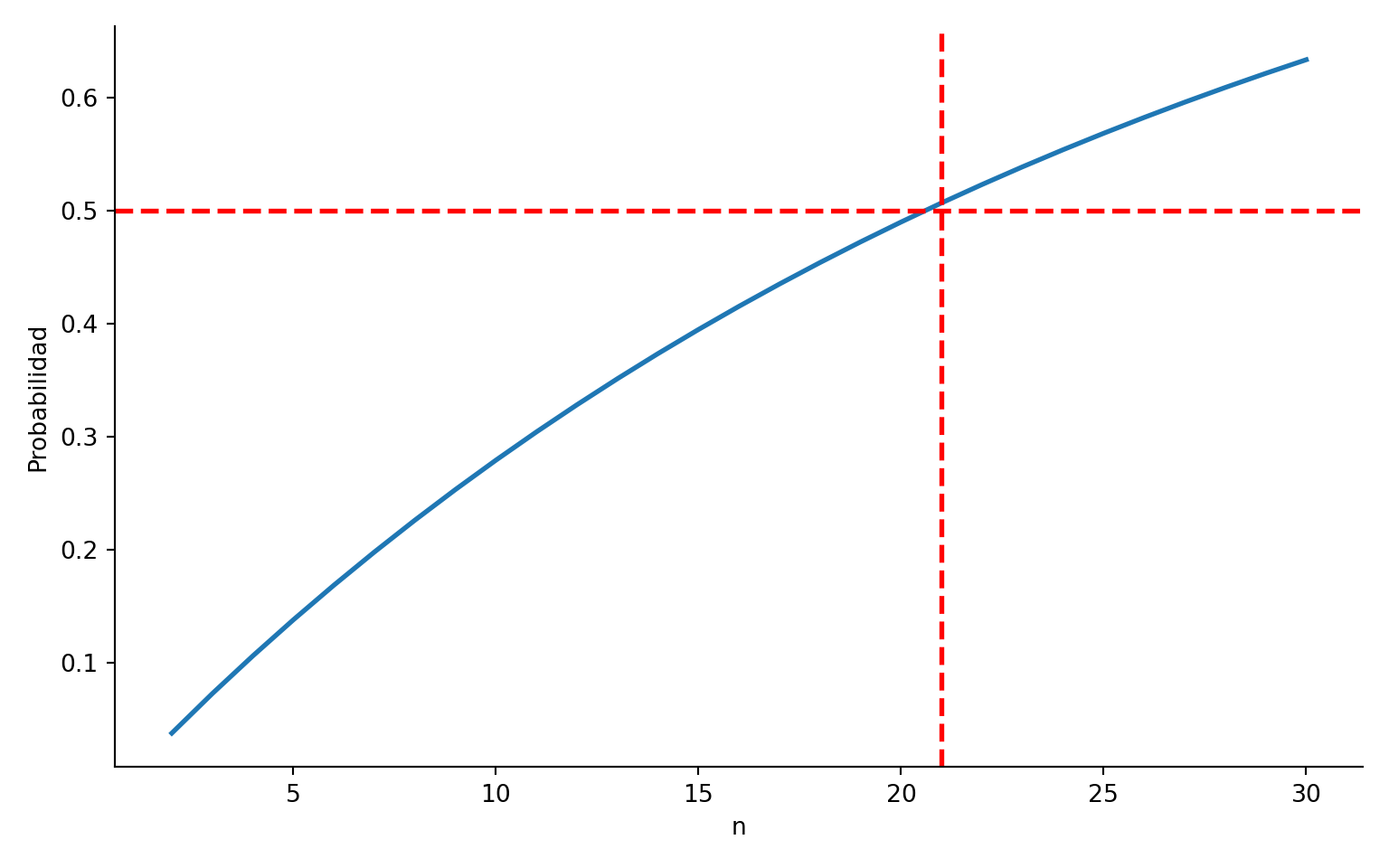
p = \mathbb P \bigg[|\hat\mu-\mu|<\dfrac {\sigma}{5}, |\hat\sigma-\sigma|<\dfrac \sigma 5\bigg] \geq \dfrac 12.
\end{equation*}\]
Por independencia de \(\bar{X}_n\) y \(\hat\sigma^2_n\), \[
p= \mathbb P \bigg[|\hat\mu-\mu|<\dfrac \sigma5\bigg] \mathbb P \bigg[|\hat\sigma-\sigma|<\dfrac \sigma5\bigg]
\]
Por un lado, \[
\mathbb P \bigg[|\hat\mu-\mu|<\dfrac \sigma5\bigg] = \mathbb P \bigg[-\dfrac{\sqrt n}5\leq \underbrace{\dfrac{\sqrt{n}(\hat\mu-\mu)}\sigma}_{N(0,1)} <\dfrac {\sqrt n}{5}\bigg] = \Phi\left(\dfrac{\sqrt n}{5}\right)-\Phi\left(-\dfrac{\sqrt n}{5}\right).
\]
# n mínimo que cumple la condiciónn_opt = n_vals[prob >=0.5][0]print(f"n mínimo que cumple p ≥ 0.5: {n_opt}")
n mínimo que cumple p ≥ 0.5: 21
TipIdeas clave: distribución \(\chi^2\)
\(\chi^2_m \sim \Gamma(m/2, 1/2)\): es un caso especial de la Gamma con media \(m\) y varianza \(2m\).
La suma de cuadrados de normales estándar i.i.d. sigue una \(\chi^2\): \(\sum_{i=1}^m Z_i^2 \sim \chi^2_m\).
Cuando \(\mu\) es desconocido y se reemplaza por \(\bar{X}_n\), se pierde un grado de libertad: \(n\hat\sigma^2/\sigma^2 \sim \chi^2_{n-1}\).
\(\bar{X}_n\) y \(s^2_n\) son independientes en muestras normales — esta es una propiedad exclusiva de la distribución normal.
8.3 Distribución \(t\)
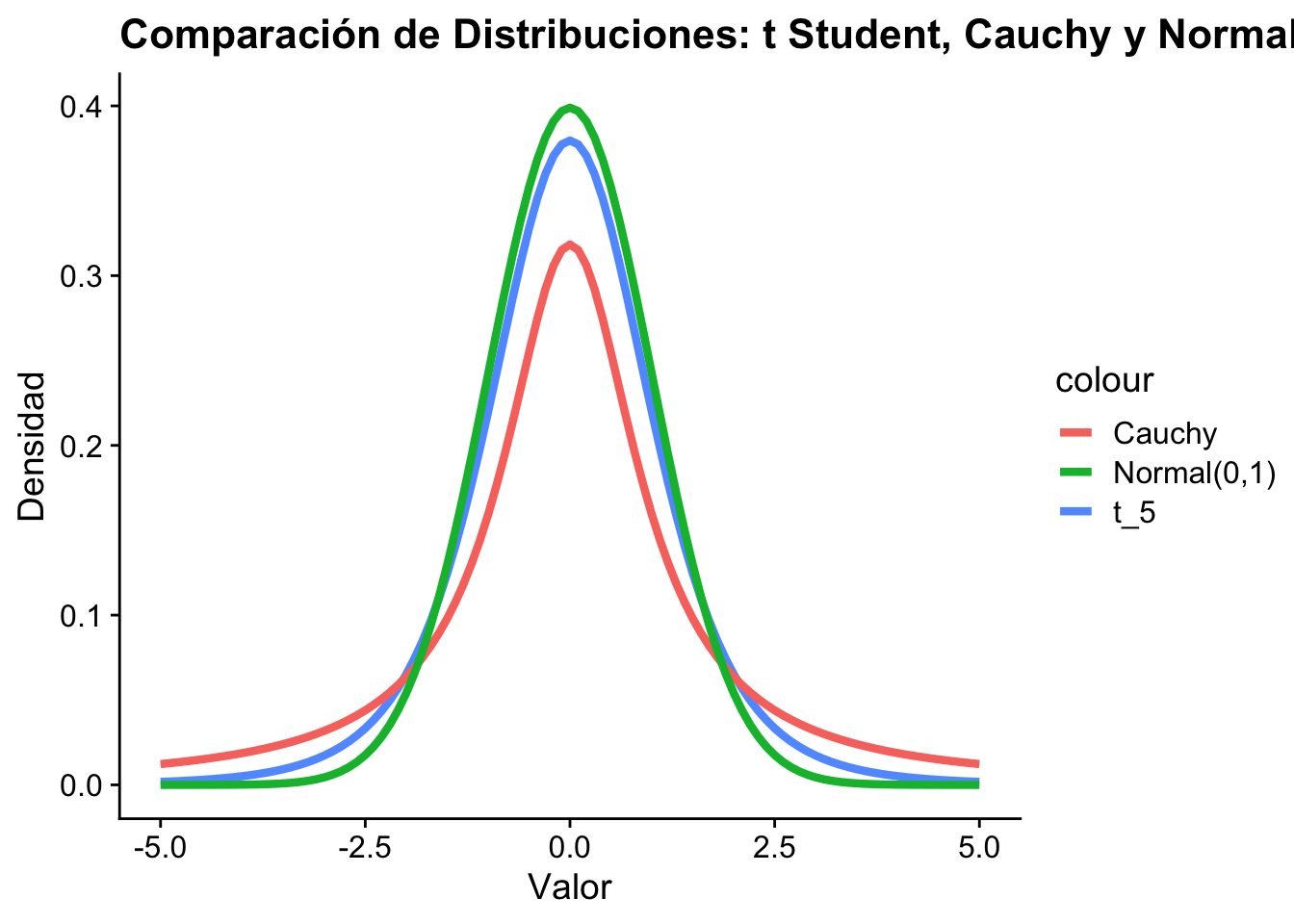
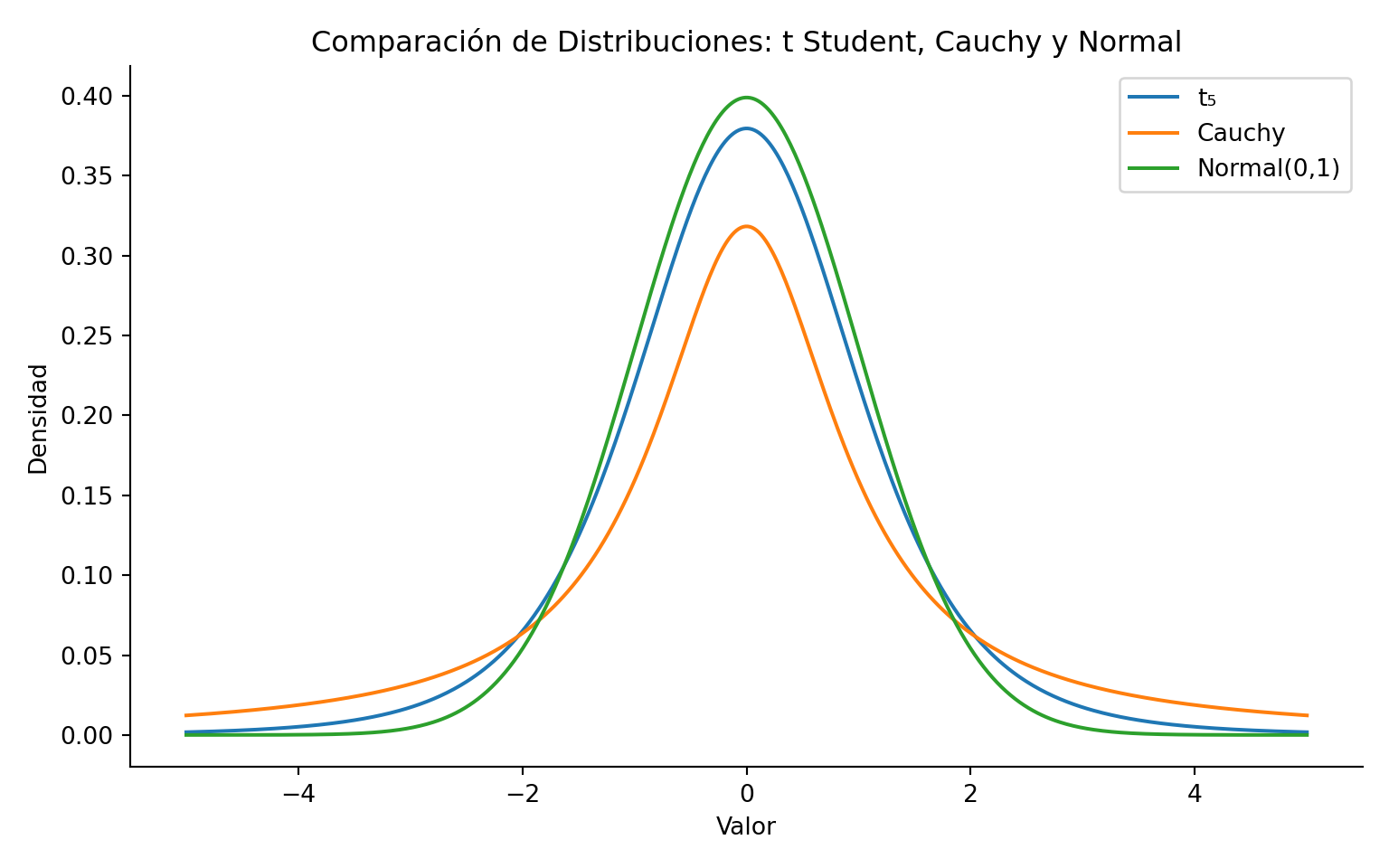
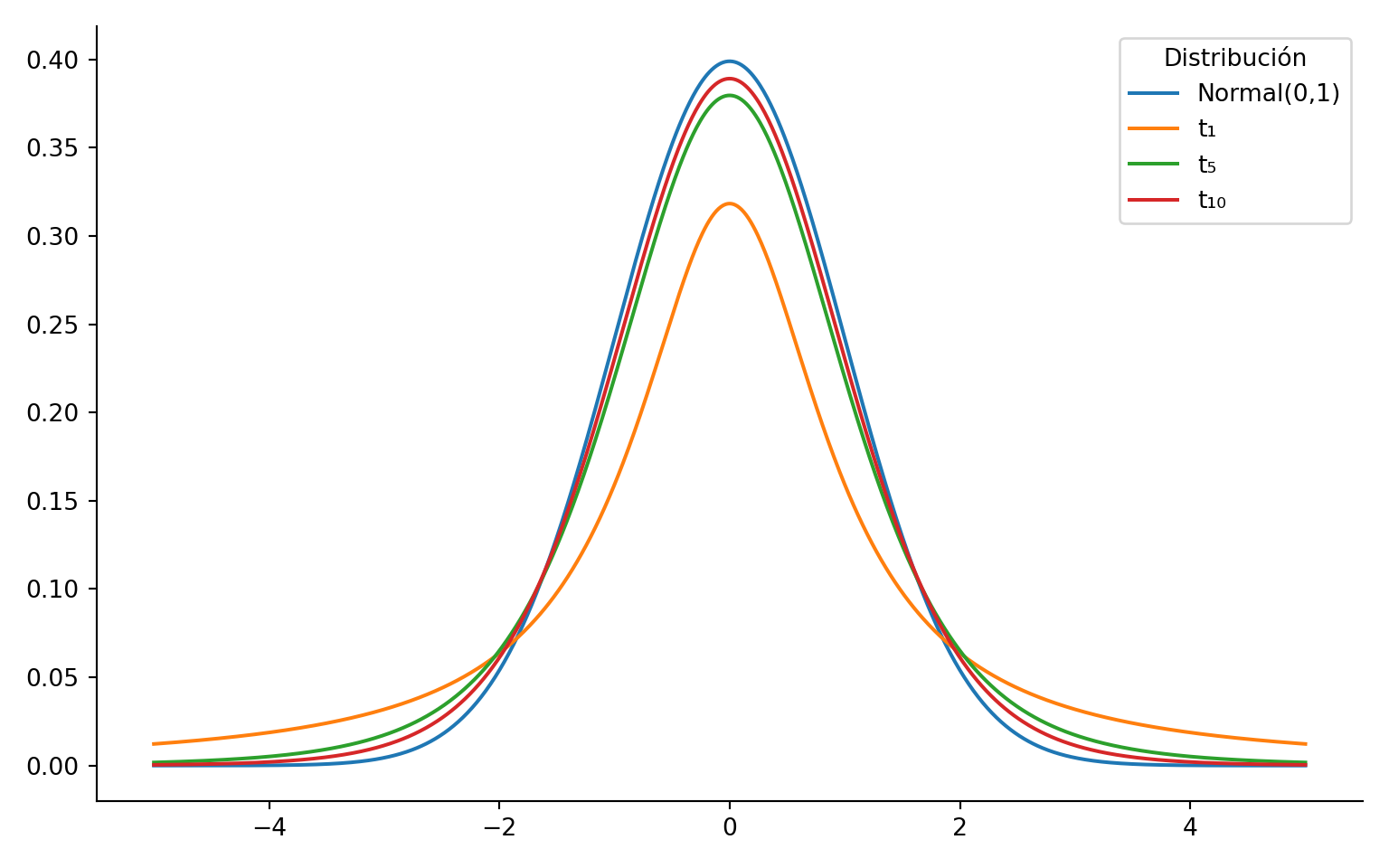
La distribución \(t\) de Student resuelve un problema práctico: cuando \(\sigma\) es desconocido, el estadístico \(\sqrt{n}(\bar{X}_n - \mu)/\sigma\) no puede calcularse directamente. Si reemplazamos \(\sigma\) por la desviación estándar muestral \(s_n\), el estadístico resultante ya no sigue una distribución normal estándar —sigue una distribución \(t\). Esta distribución tiene colas más pesadas que la normal, lo que refleja la incertidumbre adicional introducida por estimar \(\sigma\). Tanto la distribución \(\chi^2\) como la distribución \(t\) serán usadas extensivamente a lo largo de lo que resta de este libro.
Definición 8.2 Considere \(Y\) y \(Z\) dos variables independientes tal que \(Y\sim \chi^2_m\) y \(Z\sim N(0,1)\). Defina la variable aleatoria \(X\) como \[\begin{equation*}
X = \dfrac Z{\sqrt{\dfrac Ym}}.
\end{equation*}\]
Entonces la distribución de \(X\) se llama distribución \(t\) de Student con \(m\) grados de libertad. Se denota como \(X\sim t_m\). Esta distribución tiene como densidad
Unas propiedades importantes de esta distribución se enuncian a continuación.
NotaPropiedades
La distribución \(t\) de Student es simétrica.
La media de \(X\) no existe si \(m\leq 1\). Si la media existe, es 0.
Las colas de una \(t\) de Student son más pesadas que una \(N(0,1)\). Esto quiere decir que la probabilidad de que una variable aleatoria \(X\) tome valores muy grandes o muy pequeños es mayor que la probabilidad de que una variable aleatoria \(Y\) tome valores muy grandes o muy pequeños, si \(X\sim t_m\) y \(Y\sim N(0,1)\).
Si \(m\) es entero, los primeros \(m-1\) momentos de \(X\) existen y no hay momentos de orden superior.
Si \(m>2\), entonces \(\text{Var}\left(X \right)=\dfrac m{m-2}\).
Si \(m=1\), \(X\sim \text{Cauchy}\).
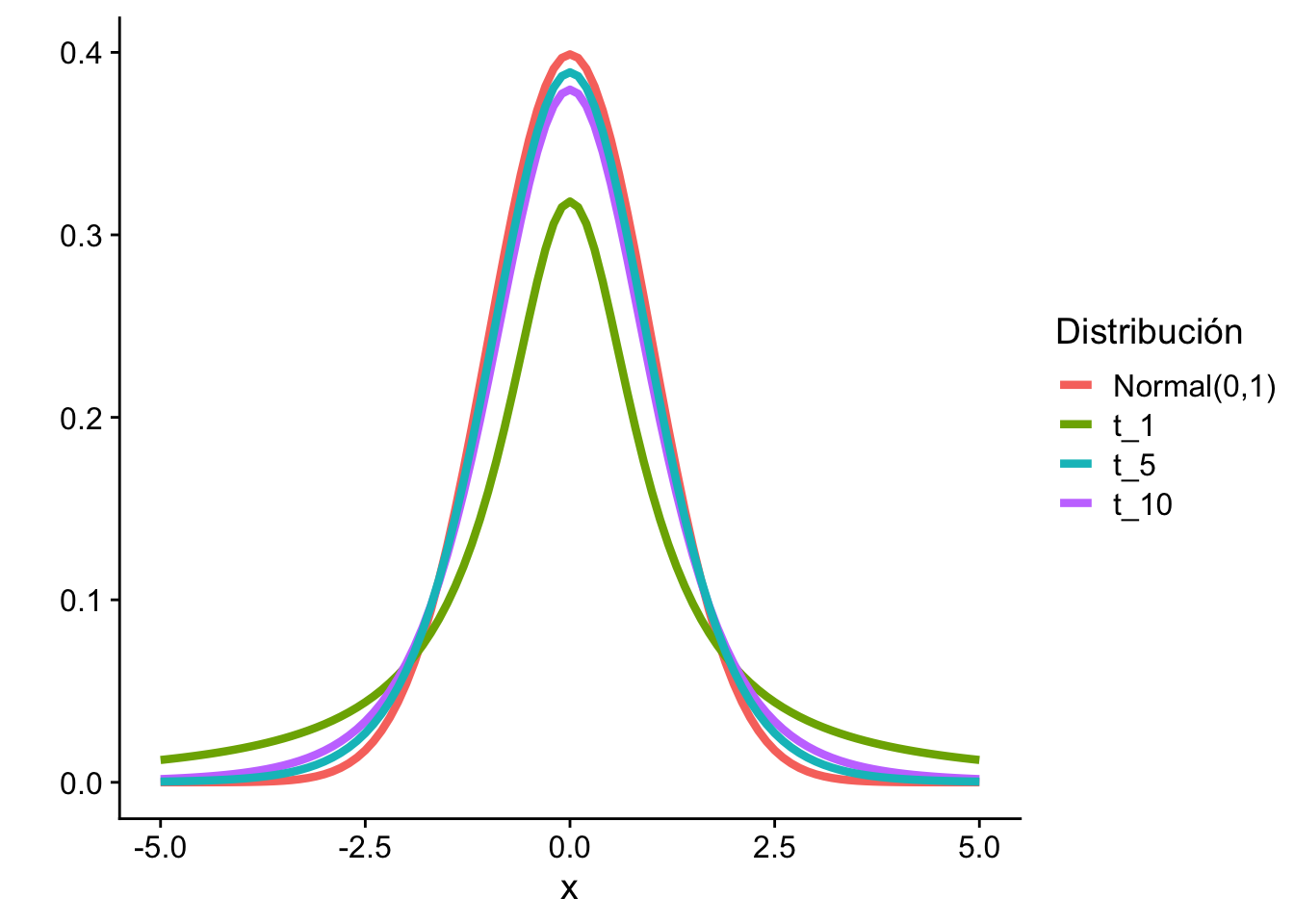
Ejercicio: Pruebe que \(f_x(x)\xrightarrow[m\to \infty]{}\Phi(x)\). Es decir, la distribución \(t\) de Student converge a la distribución normal estándar cuando \(m\) es grande (la distribución \(t\)-student sirve como aproximación de la normal). La discrepancia de ambas está en la cola y se disipa cuando \(m\) es grande.
Una propiedad importante es que nos va a permitir aproximar estadísticos cuando \(\mu\) y \(\sigma\) son desconocidos.
Note primero que de la sección anterior, sabemos que si \(X_1,\dots,X_n \sim N(\mu,\sigma^2)\), entonces \(\bar{X}_n \sim N\left(\mu,\dfrac{\sigma^2}{n}\right)\) y \(\dfrac{n\hat\sigma^2}{\sigma^2}\sim \chi^2_{n-1}\) son independientes. Ademas definamos la varianza muestral como:
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import t, normx = np.linspace(-5, 5, 1000)# Densidades t para distintos df y la Normal estándarspecs = [ (norm.pdf(x), "Normal(0,1)"), (t.pdf(x, df=1), "t₁"), (t.pdf(x, df=5), "t₅"), (t.pdf(x, df=10), "t₁₀"),]fig, ax = plt.subplots(figsize=(8, 5))for y, label in specs: ax.plot(x, y, linewidth=1.5, label=label)ax.set_ylabel("")ax.legend(title="Distribución")ax.spines[["top", "right"]].set_visible(False)plt.tight_layout()plt.show()
TipIdeas clave: distribución \(t\) de Student
La distribución \(t_m\) surge al dividir una \(N(0,1)\) por la raíz de una \(\chi^2_m/m\) independiente.
Tiene colas más pesadas que la normal; cuando \(m \to \infty\), converge a \(N(0,1)\).
El estadístico \(\sqrt{n}(\bar{X}_n - \mu)/s_n \sim t_{n-1}\) es fundamental cuando \(\sigma\) es desconocido.
Usar \(t\) en lugar de \(Z\) cuando \(n\) es pequeño y \(\sigma\) desconocido no es opcional: ignorarlo produce intervalos de confianza demasiado estrechos.
8.4 Resumen
Distribución
Definición
Media
Varianza
Uso principal
\(\chi^2_m\)
\(\Gamma(m/2,\,1/2)\)
\(m\)
\(2m\)
Varianza muestral, bondad de ajuste
\(t_m\)
\(Z/\sqrt{Y/m}\), \(Z\perp Y\)
\(0\) (si \(m>1\))
\(m/(m-2)\) (si \(m>2\))
Media con \(\sigma\) desconocido
Resultados clave para muestras normales \(X_i \sim N(\mu, \sigma^2)\):