16 Pruebas no-paramétricas: pruebas de signo y rango
En los capítulos anteriores todas las pruebas exigían conocer la familia de la distribución (normal, Poisson, etc.) o estimar sus parámetros. Pero ¿qué ocurre cuando el histograma no se parece a ninguna distribución conocida? Este capítulo responde esa pregunta con pruebas no paramétricas: herramientas que no suponen una forma específica para los datos y que cierran el bloque de inferencia del libro. Estas pruebas se apoyan solo en el orden y el signo de las observaciones, por lo que siguen siendo válidas aunque la forma de la distribución sea desconocida; el precio que se paga es, por lo general, una menor potencia que la de una prueba paramétrica correctamente especificada.
16.1 Prueba de signo
Sean \(X_1,\dots,X_n\) una muestra aleatoria de una distribución desconocida continua. Recordemos que no toda distribución tiene media; por ejemplo, la distribución Cauchy1. Sin embargo, toda distribución continua sí tiene una mediana \(\eta\) definida. Necesitamos entonces una prueba que hable de la mediana sin suponer la forma de la distribución: ese es el papel de la prueba de signo.
La mediana es una popular medida de ubicación, que satisface
\[ \mathbb P(X_i\leq \eta)=0{,}5. \]
Suponga que queremos probar
\[\begin{align*} H_0: & \ \eta\leq \eta_{0} \\ H_1: & \ \eta > \eta_{0} \end{align*}\]
La clave es traducir una pregunta sobre la mediana en una pregunta sobre una probabilidad, porque una probabilidad sí podemos estimarla contando, sin conocer la distribución. Por la definición de mediana,
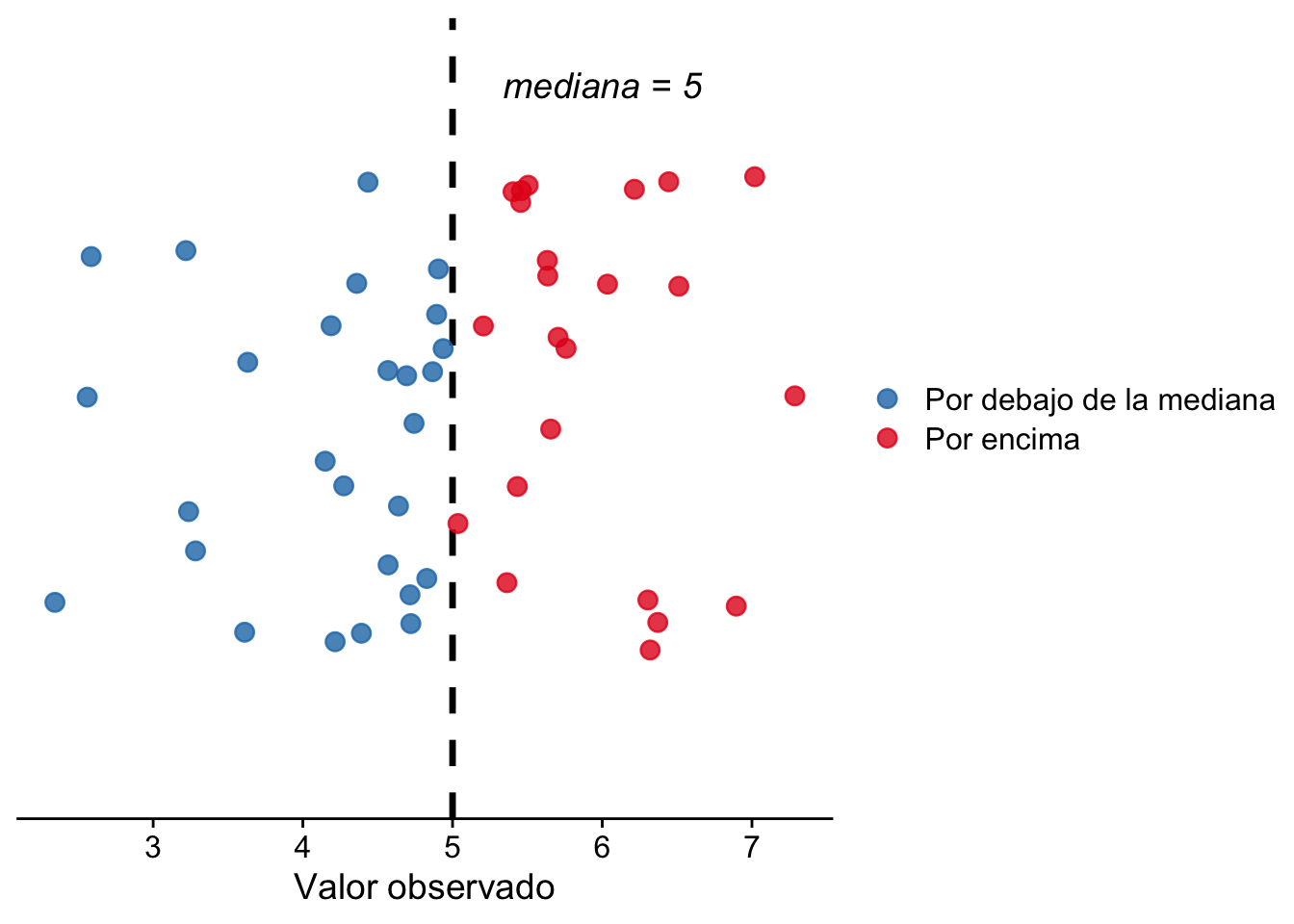
\[ \eta\leq \eta_0 \iff \mathbb P(X_i\leq \eta_0)\geq 0{,}5 . \]
Si la mediana está en \(\eta_0\) o por debajo, entonces al menos la mitad de la masa de probabilidad queda en \(\eta_0\) o por debajo. De forma más gráfica, en el caso límite \(\eta=\eta_0\) es como lanzar una moneda: la mitad de las veces un valor de \(X\) caería por debajo de \(\eta_0\) y la otra mitad por encima.
Podemos verlo simulando. Tomamos una distribución con mediana conocida (una normal con mediana \(\eta_0=0\)), ponemos el corte exactamente en la mediana y contamos cuántos datos caen por debajo: la proporción ronda \(0{,}5\). Si repetimos el experimento muchas veces, el conteo \(W\) se distribuye como una Binomial\((n, 0{,}5)\) centrada en \(n/2\), justo como la suma de \(n\) lanzamientos de una moneda:
Definamos entonces \(p = \mathbb P(X_i\leq \eta_0)\). Las hipótesis se vuelven puramente sobre \(p\):
\[ H_0: p\geq 0{,}5 \quad\text{vs}\quad H_1: p< 0{,}5 . \]
Ahora \(p\) es fácil de estimar: a cada dato le ponemos una marca \(Y_i = 1\) si \(X_i\leq \eta_0\) (cae bajo el corte) y \(Y_i = 0\) si no. Cada \(Y_i\sim \text{Bernoulli}(p)\) y, como \(X_1,\dots,X_n\) son independientes, los \(Y_1,\dots,Y_n\) también lo son. Por lo tanto su suma
\[ W = \sum_{i=1}^n Y_i \sim \text{Binomial}(n,p) \]
cuenta cuántas observaciones quedaron en \(\eta_0\) o por debajo.
¿Cuándo rechazamos? Bajo \(H_0\) (\(p\geq 0{,}5\)) esperamos que al menos la mitad de los datos estén por debajo, es decir, \(W\) grande (cercano o mayor que \(n/2\)). Bajo \(H_1\) (\(\eta>\eta_0\), o sea \(p<0{,}5\)) esperamos pocos datos por debajo: \(W\) pequeño. Por eso rechazamos \(H_0\) cuando \(W\) es pequeño.
Para tener una prueba de tamaño \(\alpha_{0}\), escoja \(c\) tal que
\[ \sum_{w=0}^c{n\choose w}\left( \dfrac 12\right)^n \leq \alpha_0 < \sum_{w=0}^{c+1}{n\choose w}\left( \dfrac 12\right)^n . \]
Se rechaza \(H_0\) si \(W\leq c\).
La prueba descrita es llamada prueba de signo pues está basada en el número de observaciones en las cuales \(X_i-\eta_0\) es negativo.
Si se desea hacer una prueba de dos colas
\[\begin{align*} H_0: & \ \eta = \eta_{0} \quad (p = \tfrac{1}{2}) \\ H_1: & \ \eta \neq \eta_{0} \quad (p \neq \tfrac{1}{2}) \end{align*}\]
se rechaza \(H_0\) si \(W\leq c\) o \(W \geq n-c\), y para obtener un nivel de significancia \(\alpha_{0}\) se selecciona \(c\) tal que
\[ \sum_{w=0}^c{n\choose w}\left( \dfrac 12\right)^n \leq \dfrac{\alpha_0}{2} < \sum_{w=0}^{c+1}{n\choose w}\left( \dfrac 12\right)^n . \]
La función de potencia (probabilidad de rechazar para un valor real de \(p\)) es
\[ \mathbb P(W\leq c) =\sum_{w=0}^c{n\choose w}(1-p)^{n-w}p^w . \]
Ejemplo 16.1 En 1986 la revista Consumer Reports publicó un análisis de laboratorio de las calorías y el sodio de 54 marcas de salchichas, clasificadas en tres tipos: res, carne mixta y ave.
Supongamos que una afirmación de la industria sostiene que una salchicha de res “típica” tiene 150 calorías, y queremos contrastarla con los datos. Como no tenemos ninguna razón para suponer que las calorías sigan una distribución normal (el reparto entre marcas bien podría ser asimétrico), evitamos la prueba \(t\) y usamos la prueba de signo, para trabajar solo con la mediana y no exige forma alguna para la distribución.
Estos fueron los datos:
Código
x <- c(
186, 181, 176, 149, 184, 190, 158, 139, 175, 148, 152, 111, 141, 153, 190, 157, 131, 149, 135, 132
)Código
import numpy as np
x = np.array(
[
186,
181,
176,
149,
184,
190,
158,
139,
175,
148,
152,
111,
141,
153,
190,
157,
131,
149,
135,
132,
]
)Un diagrama de caja resume la posición de los datos:
Código
ggplot(as.data.frame(x), aes(y = x)) +
geom_boxplot() +
theme_minimal()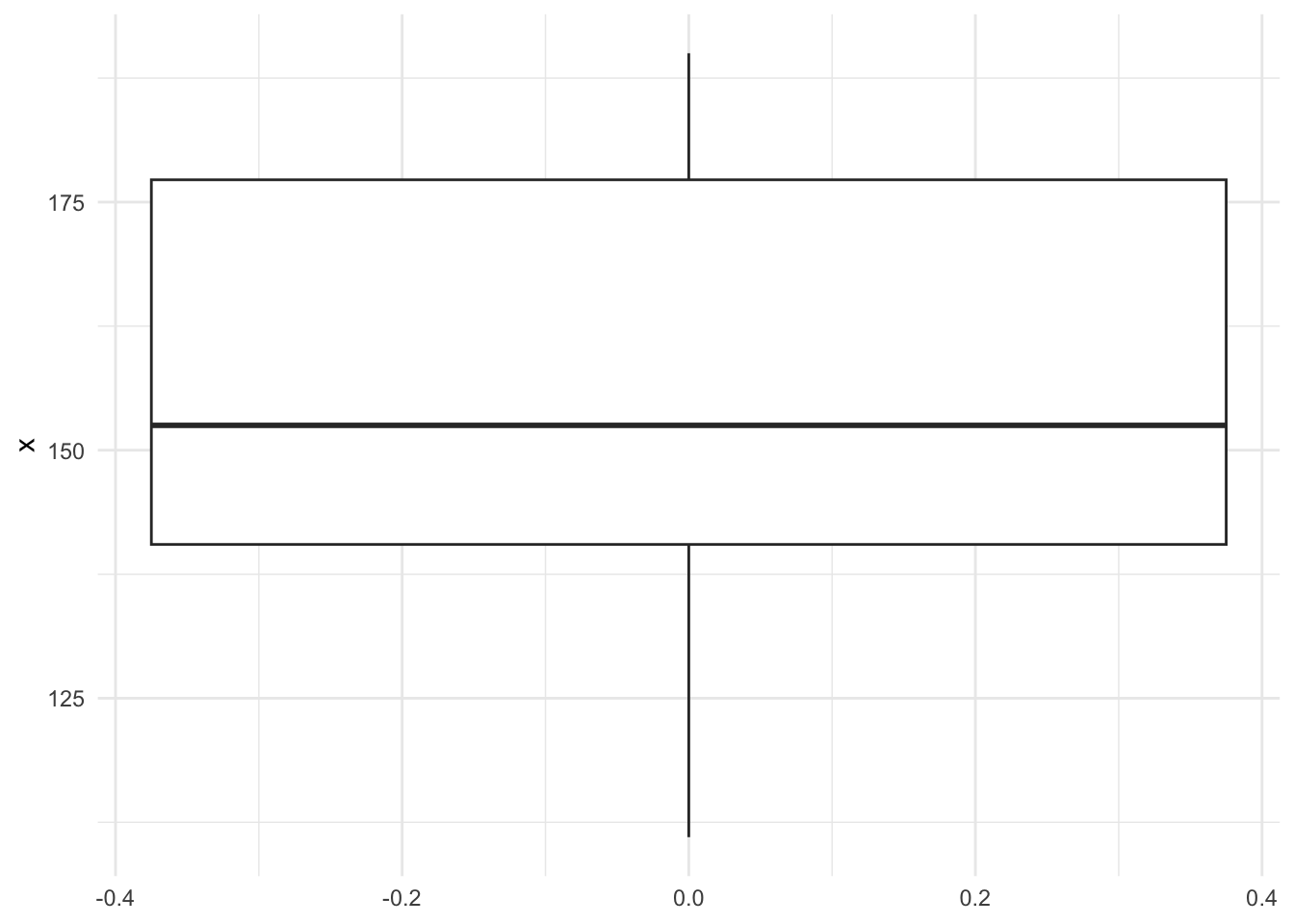
Código
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.boxplot(x){'whiskers': [<matplotlib.lines.Line2D object at 0x1422705f0>, <matplotlib.lines.Line2D object at 0x142270920>], 'caps': [<matplotlib.lines.Line2D object at 0x142270c50>, <matplotlib.lines.Line2D object at 0x142270f50>], 'boxes': [<matplotlib.lines.Line2D object at 0x1421a6420>], 'medians': [<matplotlib.lines.Line2D object at 0x142271280>], 'fliers': [<matplotlib.lines.Line2D object at 0x1421bfe00>], 'means': []}Código
ax.set_ylabel("Calorías")
plt.show()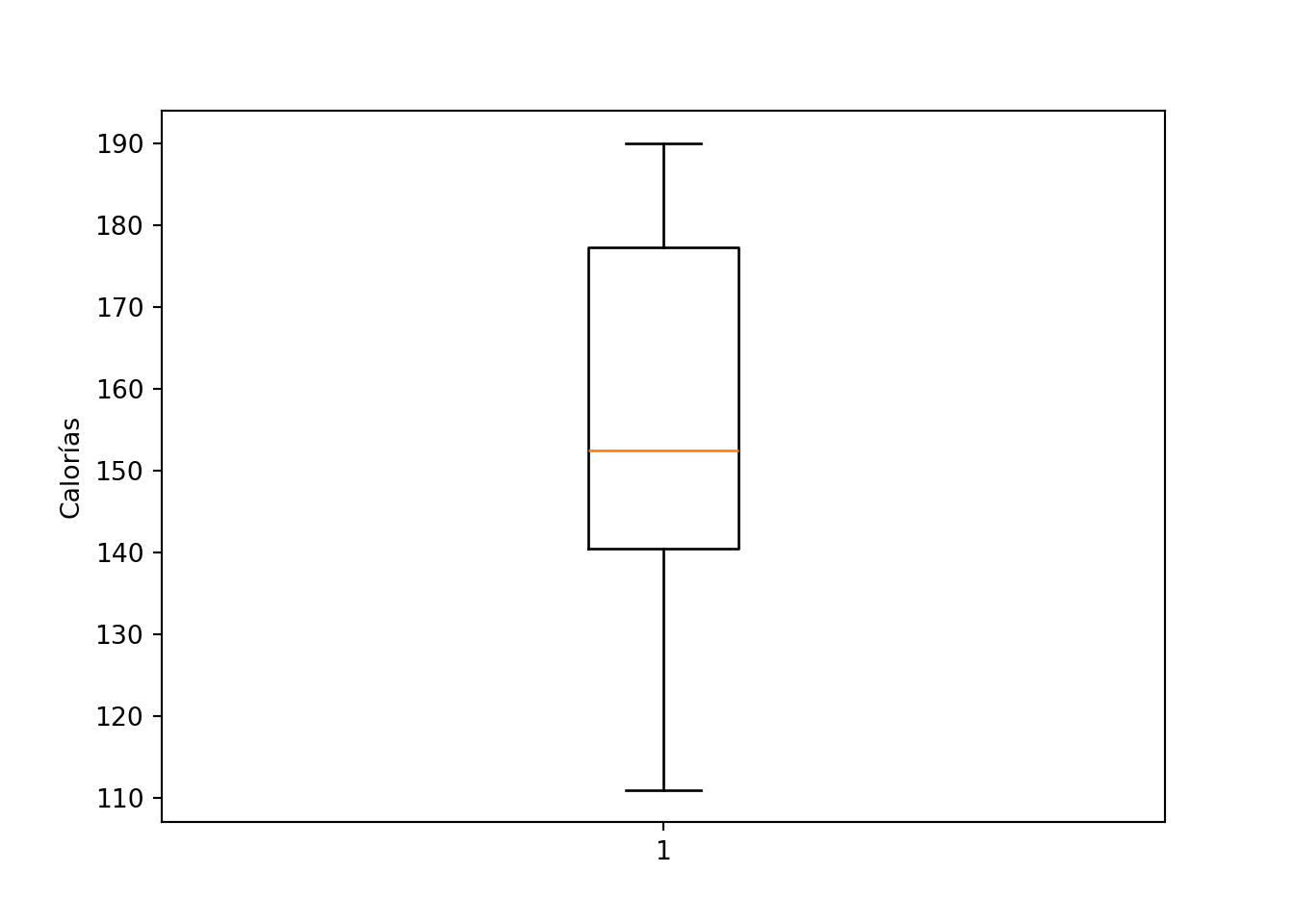
Se quiere hacer el supuesto de que la mediana es igual a 150 (\(\eta = 150\)). Entonces se plantea la hipótesis
\[\begin{align*} H_0: & \ \eta = 150 \\ H_1: & \ \eta \neq 150 \end{align*}\]
La prueba de signo cuenta cuántas veces \(X_i - 150\) es negativo. Observe que para estos datos tenemos:
Código
(M <- data.frame(
diferencias = x - 150,
signo_negativo = x - 150 < 0
)) diferencias signo_negativo
1 36 FALSE
2 31 FALSE
3 26 FALSE
4 -1 TRUE
5 34 FALSE
6 40 FALSE
7 8 FALSE
8 -11 TRUE
9 25 FALSE
10 -2 TRUE
11 2 FALSE
12 -39 TRUE
13 -9 TRUE
14 3 FALSE
15 40 FALSE
16 7 FALSE
17 -19 TRUE
18 -1 TRUE
19 -15 TRUE
20 -18 TRUECódigo
summary(M$signo_negativo) Mode FALSE TRUE
logical 11 9 Código
import pandas as pd
M = pd.DataFrame({
"diferencias": x - 150,
"signo_negativo": (x - 150) < 0,
})
print(M.to_string(index=False)) diferencias signo_negativo
36 False
31 False
26 False
-1 True
34 False
40 False
8 False
-11 True
25 False
-2 True
2 False
-39 True
-9 True
3 False
40 False
7 False
-19 True
-1 True
-15 True
-18 TrueCódigo
print(M["signo_negativo"].value_counts())signo_negativo
False 11
True 9
Name: count, dtype: int64Hay \(W = 9\) signos negativos de \(n = 20\). El valor-\(p\) de dos colas (porque \(W=9 < n/2\), se duplica la cola inferior) es:
Código
2 * pbinom(q = 9, size = 20, prob = 1 / 2)[1] 0.8238029Código
from scipy import stats
print(2 * stats.binom.cdf(9, 20, 0.5))0.8238029479980469El valor-\(p\) es \(\approx 0.824\): solo rechazaríamos la hipótesis nula con un nivel de significancia \(\alpha_0\geq 0.824\), es decir, no rechazamos que la mediana sea 150.
Este mismo problema se puede resolver con la función binom.test de R (x es el número de signos negativos y n es el número total de datos):
Código
binom.test(x = 9, n = 20)
Exact binomial test
data: 9 and 20
number of successes = 9, number of trials = 20, p-value = 0.8238
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.2305779 0.6847219
sample estimates:
probability of success
0.45 Código
print(stats.binomtest(9, 20, 0.5))BinomTestResult(k=9, n=20, alternative='two-sided', statistic=0.45, pvalue=0.8238029479980469)
TipIdeas clave de esta sección
- La prueba de signo convierte una hipótesis sobre la mediana en una prueba binomial sobre el número de observaciones por debajo de \(\eta_0\).
- Solo exige que la distribución sea continua; no supone normalidad ni simetría.
- El estadístico es \(W=\#\{X_i<\eta_0\}\) y, bajo \(H_0\), \(W\sim\text{Binomial}(n,1/2)\).
- Su sencillez tiene un costo: ignora la magnitud de las desviaciones, solo su signo, por lo que pierde potencia.
16.2 Prueba de Wilcoxon-Mann-Whitney
La prueba de signo resuelve el problema de una muestra contra una mediana fija, pero solo usa el signo de cada diferencia e ignora la magnitud. ¿Qué ocurre cuando queremos comparar dos muestras entre sí —por ejemplo, dos métodos de fabricación o dos tratamientos— sin saber si los datos son normales? Para ese caso necesitamos una prueba que use más información que el simple signo: los rangos. Esa es la idea central de la prueba de Wilcoxon-Mann-Whitney.
Dados dos conjuntos de variables \(X_1,\dots, X_m\overset{i.i.d}{\sim} F\) y \(Y_1, \dots, Y_{n}\overset{i.i.d}{\sim} G\), con \(F,G\) continuas, queremos probar
\[\begin{align*} H_0: & \ F = G \\ H_1: & \ F \neq G . \end{align*}\]
Observación. Aunque la hipótesis nula es \(F = G\), la prueba WMW tiene máxima potencia para detectar diferencias de localización cuando ambas distribuciones tienen la misma forma (es decir, \(G(x) = F(x - \Delta)\) para algún desplazamiento \(\Delta\)). Si las formas son distintas —por ejemplo, una distribución simétrica y otra asimétrica— un valor-\(p\) pequeño solo indica que \(F \neq G\), sin precisar si la diferencia está en la mediana, en la dispersión o en la forma. En la práctica, conviene inspeccionar los diagramas de caja antes de interpretar el resultado.
Esta hipótesis se puede abordar con las pruebas de Kolmogorov-Smirnov o la prueba \(t\) (dependiendo de \(F\) y \(G\)). Otra forma es usar la prueba de Wilcoxon-Mann-Whitney (prueba de rango), descubierta por F. Wilcoxon, H. B. Mann y D. R. Whitney en la década de 1940.
La lógica de la prueba reside en que, si unimos los dos conjuntos de valores y ambos tienen la misma distribución, entonces los datos, ordenados de menor a mayor, deberían quedar dispersos de manera equitativa entre las dos muestras. Bajo \(H_0\) unimos las dos muestras en un solo vector de tamaño \(m+n\):
\[ (W_1,\dots,W_{m+n}) = (X_1,\dots,X_m,Y_1,\dots,Y_n), \]
que se puede ordenar de menor a mayor:
\[ (W_{(1)},\dots,W_{(m+n)}). \]
Ahora viene la idea central de la prueba. Una vez ordenados los \(m+n\) valores, olvidamos sus magnitudes y nos quedamos solo con una pregunta: ¿en qué posiciones de esa fila ordenada cayeron las observaciones de la muestra \(X\)? A esas posiciones \(1, 2, \dots, m+n\) las llamamos rangos. Por eso “volvemos” a la muestra \(X\): no nos interesa el valor de cada \(X_i\), sino el rango que ocupa dentro del conjunto combinado.
Llamemos \(I_1,\dots,I_m\) a los rangos que les tocaron a las \(m\) observaciones de la muestra \(X\). Por ejemplo, si el dato más pequeño de todos es una \(X\), entonces uno de esos rangos es \(1\); si el más grande también es una \(X\), otro rango es \(m+n\).
Aquí está el punto clave: bajo \(H_0\) (\(F=G\)), las dos muestras provienen de la misma distribución, así que ninguna observación tiene preferencia por quedar arriba o abajo. En consecuencia, los \(m\) rangos que ocupa la muestra \(X\) son tan probables como cualquier otro subconjunto de \(m\) posiciones tomadas de \(\{1,\dots,m+n\}\) —es como repartir al azar \(m\) de las \(m+n\) posiciones a la muestra \(X\). Cada rango individual \(I_i\) es entonces uniforme sobre \(\{1,\dots,m+n\}\).
Para resumir esa información en un solo número, sumamos los rangos de la muestra \(X\):
\[ S = \sum_{i=1}^m I_i . \]
La intuición es directa: si la muestra \(X\) tiende a tomar valores grandes, ocupará rangos altos y \(S\) será grande; si tiende a valores pequeños, \(S\) será pequeño. Solo cuando ambas muestras se entremezclan (lo esperable bajo \(H_0\)) el valor de \(S\) queda cerca de su promedio.
El siguiente gráfico ilustra el mecanismo. Cada punto es una observación colocada en su rango dentro de la muestra combinada; el color indica de qué muestra proviene. Arriba, ambas muestras vienen de la misma distribución (\(H_0\)): los colores se entremezclan y la suma de rangos de \(X\) queda cerca de su valor esperado \(\mathbb E[S]=76\). Abajo, la muestra \(X\) está desplazada hacia la derecha (\(H_1\)): sus puntos acaparan los rangos altos y \(S\) se dispara muy por encima de \(76\).
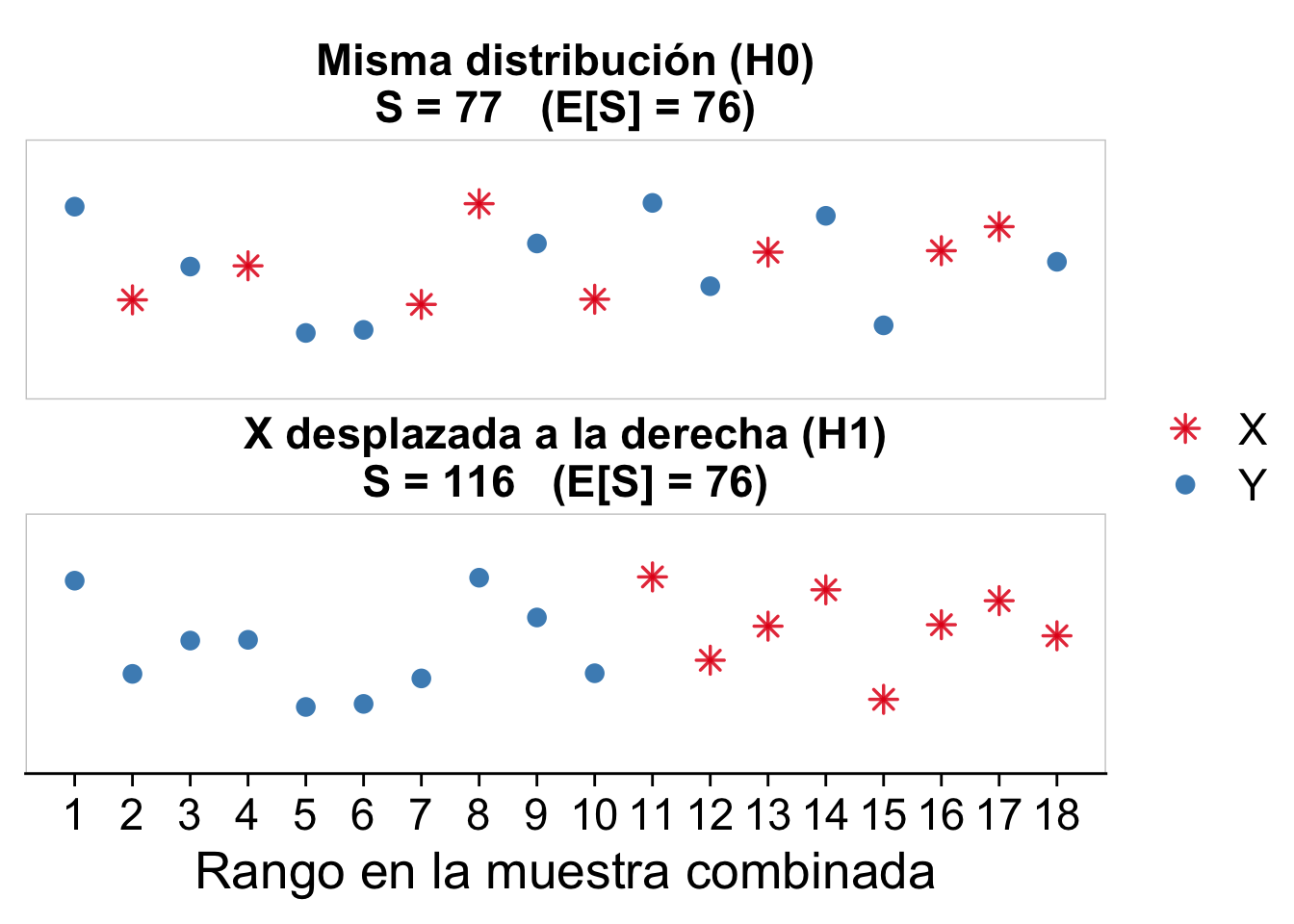
Se puede probar que, bajo \(H_0\),
\(\mathbb E[S] \overset{H_0}{=} \dfrac{m(m+n+1)}{2}\).
\(\text{Var}(S) \overset{H_0}{=} \dfrac{mn(m+n+1)}{12}\).
El resultado importante de Mann y Whitney (1947) fue probar que, si \(m,n\) son grandes, entonces
\[ S\underset{H_0}{\approx}N\left(\dfrac{m(m+n+1)}{2},\ \dfrac{mn(m+n+1)}{12}\right). \]
Por lo tanto, el estadístico \(S\) estandarizado sigue aproximadamente una distribución normal estándar bajo \(H_0\), lo que permite calcular valores-\(p\) y regiones de rechazo usando la tabla normal. Rechazamos la hipótesis nula si \(S\) se desvía mucho de su media \(\mathbb E[S]\); en otras palabras, rechazamos \(H_0\) si
\[ \left|S- \frac{m(m+n+1)}{2}\right| \geq \left(\text{Var}(S)\right)^{\frac{1}{2}} \,\Phi^{-1}\!\left(1-\frac{\alpha}{2}\right). \]
Ejemplo 16.2 Supongamos que tenemos estos dos conjuntos de datos y queremos ver si tienen la misma distribución.
Código
x <- c(2.183, 2.431, 2.556, 2.629, 2.641, 2.715, 2.805, 2.840)
y <- c(2.120, 2.153, 2.213, 2.240, 2.245, 2.266, 2.281, 2.336, 2.558, 2.587)
dfx <- data.frame(W = x, variable = "x")
dfy <- data.frame(W = y, variable = "y")Código
x = np.array([2.183, 2.431, 2.556, 2.629, 2.641, 2.715, 2.805, 2.840])
y = np.array([2.120, 2.153, 2.213, 2.240, 2.245, 2.266, 2.281,
2.336, 2.558, 2.587])Lo primero es unirlos, ordenarlos y calcular su rango:
Código
dfw <- bind_rows(dfx, dfy) %>%
arrange(W) %>%
mutate(rango = 1:n()) # rango = posición en el vector combinado
dfw W variable rango
1 2.120 y 1
2 2.153 y 2
3 2.183 x 3
4 2.213 y 4
5 2.240 y 5
6 2.245 y 6
7 2.266 y 7
8 2.281 y 8
9 2.336 y 9
10 2.431 x 10
11 2.556 x 11
12 2.558 y 12
13 2.587 y 13
14 2.629 x 14
15 2.641 x 15
16 2.715 x 16
17 2.805 x 17
18 2.840 x 18Código
import pandas as pd
W = np.concatenate([x, y])
grupo = np.array(["x"] * len(x) + ["y"] * len(y))
orden = np.argsort(W) # ordenar el vector combinado
dfw = pd.DataFrame({"W": W[orden], "variable": grupo[orden]})
dfw["rango"] = np.arange(1, len(W) + 1) # rango = posición
print(dfw.to_string(index=False)) W variable rango
2.120 y 1
2.153 y 2
2.183 x 3
2.213 y 4
2.240 y 5
2.245 y 6
2.266 y 7
2.281 y 8
2.336 y 9
2.431 x 10
2.556 x 11
2.558 y 12
2.587 y 13
2.629 x 14
2.641 x 15
2.715 x 16
2.805 x 17
2.840 x 18Un diagrama de caja muestra que la muestra x tiende a tomar valores más altos:
Código
ggplot(dfw, aes(y = W, fill = variable)) +
geom_boxplot() +
cowplot::theme_cowplot(font_size = 20)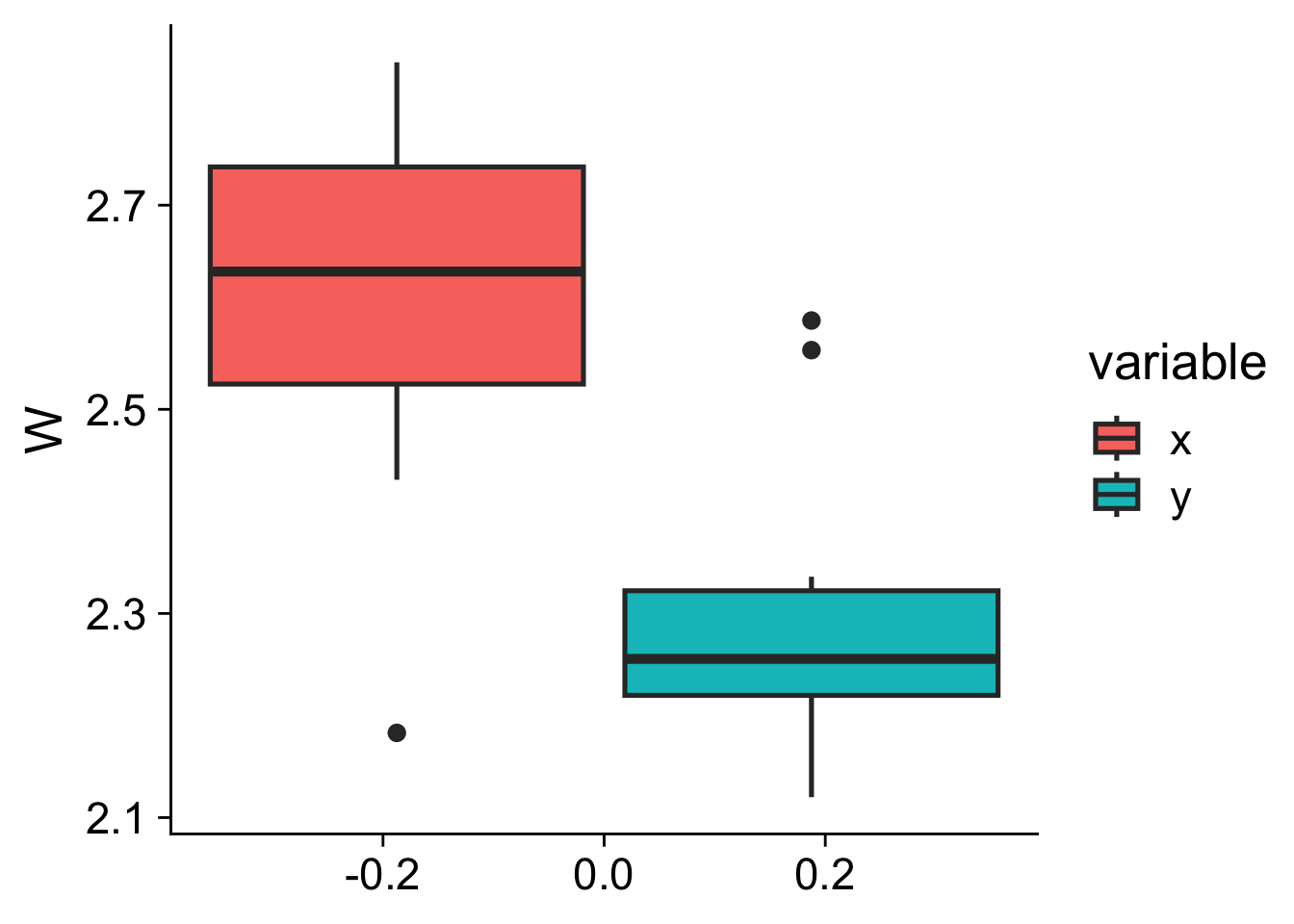
Código
fig, ax = plt.subplots()
ax.boxplot([x, y], labels=["x", "y"])<string>:1: MatplotlibDeprecationWarning: The 'labels' parameter of boxplot() has been renamed 'tick_labels' since Matplotlib 3.9; support for the old name will be dropped in 3.11.
{'whiskers': [<matplotlib.lines.Line2D object at 0x1480c5e20>, <matplotlib.lines.Line2D object at 0x1480de660>, <matplotlib.lines.Line2D object at 0x1480dd610>, <matplotlib.lines.Line2D object at 0x1480dd160>], 'caps': [<matplotlib.lines.Line2D object at 0x1480de930>, <matplotlib.lines.Line2D object at 0x1480dec00>, <matplotlib.lines.Line2D object at 0x1480df260>, <matplotlib.lines.Line2D object at 0x1480df590>], 'boxes': [<matplotlib.lines.Line2D object at 0x1480c5c10>, <matplotlib.lines.Line2D object at 0x1480dd7c0>], 'medians': [<matplotlib.lines.Line2D object at 0x1480def00>, <matplotlib.lines.Line2D object at 0x1480df890>], 'fliers': [<matplotlib.lines.Line2D object at 0x1480dddc0>, <matplotlib.lines.Line2D object at 0x1480dfbc0>], 'means': []}Código
ax.set_ylabel("W")
plt.show()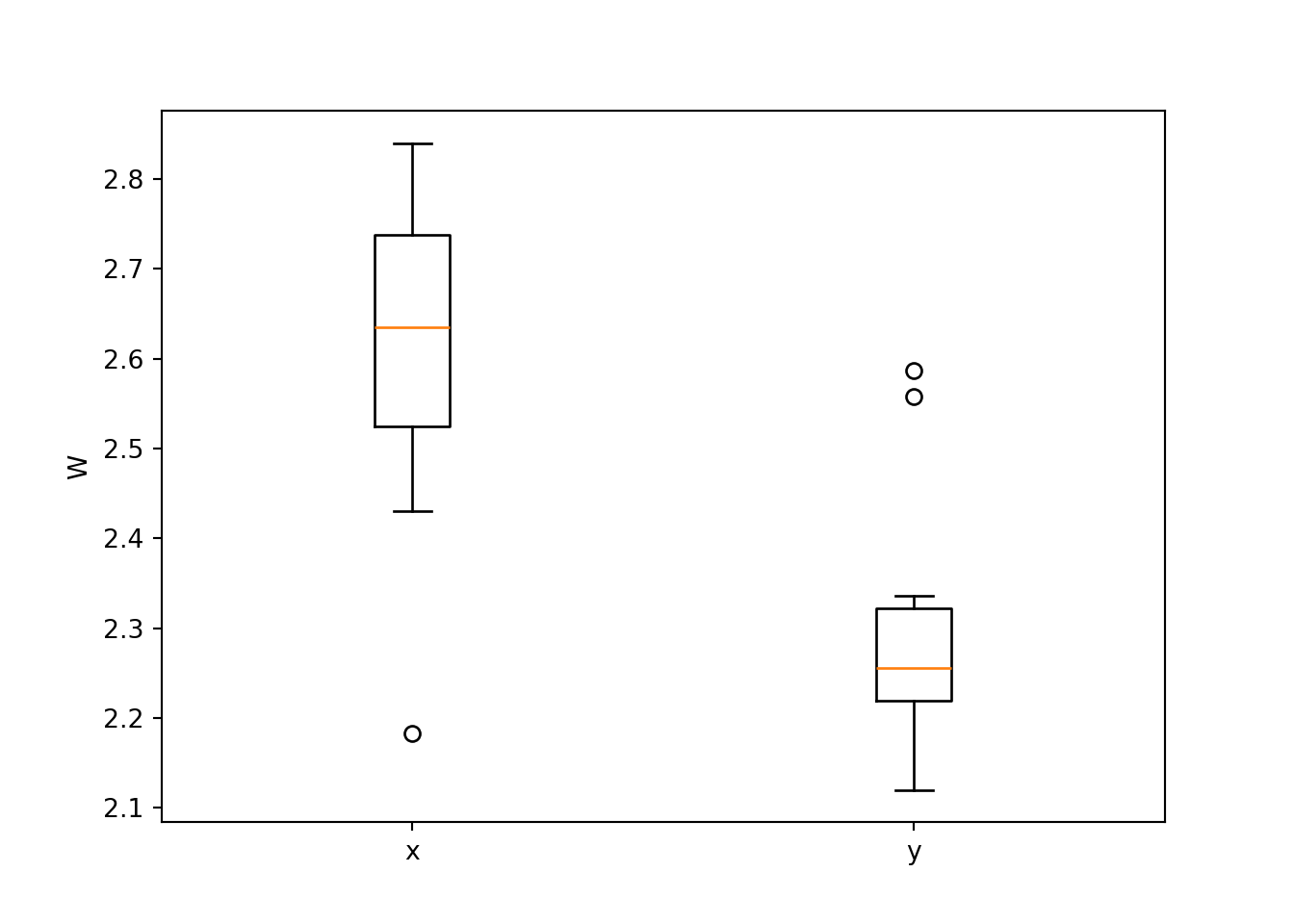
Definamos \(m\) y \(n\) de las muestras.
Nota
Convención: tomaremos siempre como \(m\) el tamaño del conjunto de datos más pequeño, y \(S\) será la suma de los rangos de esa misma muestra.
Código
(m <- length(x)) # muestra más pequeña[1] 8Código
(n <- length(y))[1] 10Código
m, n = len(x), len(y)
print(f"m = {m}")m = 8Código
print(f"n = {n}")n = 10Construimos las media y varianza teóricas de la suma de rangos:
Código
(media_S <- m * (m + n + 1) / 2)[1] 76Código
(var_S <- m * n * (m + n + 1) / 12)[1] 126.6667Código
media_S = m * (m + n + 1) / 2
var_S = m * n * (m + n + 1) / 12
print(f"media_S = {media_S}")media_S = 76.0Código
print(f"var_S = {var_S:.4f}")var_S = 126.6667Tomamos la suma de todos los rangos de la muestra más pequeña; en este caso, los x:
Código
S <- dfw %>%
filter(variable == "x") %>% # muestra más pequeña (tamaño m)
summarise(S = sum(rango))
(S <- as.numeric(S))[1] 104Código
S = dfw.loc[dfw["variable"] == "x", "rango"].sum() # muestra más pequeña (tamaño m)
print(f"S = {S}")S = 104La variable \(S\) sigue, bajo \(H_0\), una distribución \(N(76,\ 126.67)\) (media \(76\), varianza \(126.67\)). Por lo tanto, su valor-\(p\) de dos colas es:
Código
(pivote <- (S - media_S) / sqrt(var_S))[1] 2.487865Código
2 * (1 - pnorm(q = pivote))[1] 0.01285124Código
print(2 * (1 - stats.norm.cdf((S - media_S) / np.sqrt(var_S))))0.012851240187496504El valor-\(p\) es \(\approx 0.0128\), de modo que rechazamos \(H_0\) para cualquier nivel de significancia \(\alpha_0 > 0.0128\): hay evidencia de que las dos muestras no provienen de la misma distribución.
La función wilcox.test de R (y mannwhitneyu de SciPy) calcula la misma prueba, aunque aplica algunos ajustes adicionales a los rangos y usa la distribución exacta para muestras pequeñas, por lo que los valores-\(p\) son ligeramente diferentes. Los detalles pueden consultarse en la ayuda de la función.
Nota
¿Por qué R reporta \(W = 68\) y no \(S = 104\)? R no usa la suma de rangos \(S\) directamente, sino el estadístico \(U\) de Mann-Whitney, que es la misma información en otra escala:
\[ U = S - \dfrac{m(m+1)}{2} = 104 - \dfrac{8\cdot 9}{2} = 104 - 36 = 68. \]
El término \(m(m+1)/2 = 1+2+\cdots+m\) es la suma mínima posible de rangos para \(m\) observaciones; restarlo hace que \(U\) mida cuánto se aleja \(S\) de ese mínimo. De forma equivalente, \(U\) cuenta el número de pares \((x_i, y_j)\) en los que \(x_i > y_j\). Como \(U\) y \(S\) se obtienen uno del otro por una constante, ambos conducen exactamente a la misma decisión.
Código
wilcox.test(x, y)
Wilcoxon rank sum exact test
data: x and y
W = 68, p-value = 0.01166
alternative hypothesis: true location shift is not equal to 0Código
print(stats.mannwhitneyu(x, y, alternative="two-sided"))MannwhitneyuResult(statistic=np.float64(68.0), pvalue=np.float64(0.011655011655011656))
TipIdeas clave de esta sección
- WMW compara dos distribuciones completas usando solo los rangos del vector combinado, sin suponer normalidad.
- Bajo \(H_0\) la suma de rangos \(S\) tiene media \(m(m+n+1)/2\) y varianza \(mn(m+n+1)/12\); para \(m,n\) grandes es aproximadamente normal.
- Se rechaza \(H_0\) cuando \(S\) se aleja de su media más de \(\Phi^{-1}(1-\alpha/2)\) desviaciones estándar.
- Para muestras pequeñas o con empates,
wilcox.testusa la distribución exacta y correcciones; la aproximación normal es solo asintótica.
16.3 Resumen
Las pruebas no paramétricas permiten contrastar hipótesis sin conocer la forma de la distribución, apoyándose en el signo o el rango de las observaciones. La siguiente tabla reúne los resultados principales del capítulo.
| Prueba | Pregunta | Estadístico | Bajo \(H_0\) | Se rechaza \(H_0\) si |
|---|---|---|---|---|
| Signo | ¿La mediana es \(\eta_0\)? | \(W=\#\{X_i<\eta_0\}\) | \(W\sim\text{Binomial}(n,\tfrac12)\) | \(W\leq c\) (una cola) o \(W\leq c,\ W\geq n-c\) (dos colas) |
| Wilcoxon-Mann-Whitney | ¿\(F=G\)? | \(S=\sum_{i=1}^m I_i\) | \(S\approx N\!\left(\tfrac{m(m+n+1)}{2},\tfrac{mn(m+n+1)}{12}\right)\) | \(\left\lvert S-\mathbb E[S]\right\rvert\geq \sqrt{\text{Var}(S)}\,\Phi^{-1}(1-\tfrac\alpha2)\) |
TipPara recordar
- Use pruebas no paramétricas cuando los supuestos distribucionales de las pruebas paramétricas no se cumplen; si sí se cumplen, la paramétrica suele ser más potente.
- La prueba de signo solo usa el signo de \(X_i-\eta_0\); WMW usa los rangos, por lo que aprovecha más información.
- Ambas pruebas suponen variables continuas (sin empates); los empates requieren correcciones que R aplica automáticamente.
- La aproximación normal de WMW es asintótica: para muestras pequeñas conviene la distribución exacta de
wilcox.test.
La densidad de una distribución Cauchy se define como \(\displaystyle f(x;x_{0},\gamma )=\frac{1}{\pi \gamma }\left[\frac{\gamma ^{2}}{(x-x_{0})^{2}+\gamma ^{2}}\right]\), donde \(x_0\) y \(\gamma\) son parámetros de localización y escala respectivamente. Esta distribución no tiene ningún momento definido y su mediana es \(x_0\).↩︎