Al finalizar este capítulo, el estudiante será capaz de:
Recordar la definición formal de estimador insesgado y sesgo, e identificarlos en ejemplos concretos.
Comprender por qué el insesgamiento no garantiza que un estimador sea el mejor, y cuándo conviene priorizar el MSE en lugar del sesgo.
Aplicar la descomposición sesgo–varianza del MSE para comparar estimadores alternativos de un mismo parámetro.
Analizar la información de Fisher de una distribución y verificar si un estimador insesgado alcanza la cota de Cramér-Rao.
Evaluar las propiedades asintóticas del MLE (consistencia, normalidad, eficiencia) y distinguirlas de las propiedades en muestras finitas.
En capítulos anteriores aprendimos a construir estimadores usando el método de máxima verosimilitud y el método de los momentos. Ahora que sabemos cómo obtener estimadores, surge la pregunta natural: ¿cómo saber si un estimador es bueno? Este capítulo desarrolla las herramientas para responder esa pregunta: el sesgo, el error cuadrático medio, la información de Fisher y la cota de Cramér-Rao. Estas herramientas son la base para los capítulos siguientes de intervalos de confianza y pruebas de hipótesis, donde necesitaremos cuantificar la incertidumbre de nuestras estimaciones.
7.1 Estimadores insesgados y sesgo
Un estimador es una función que calcula una estimación o predicción de un parámetro desconocido en una distribución de probabilidad. En estadística, uno de los criterios importantes para evaluar la calidad de un estimador es si es insesgado.
Un estimador se considera insesgado si su valor esperado es igual al valor verdadero del parámetro que se está estimando. Esto se puede expresar matemáticamente como:
donde \(\delta(x)\) es el estimador, \(g(\theta)\) es el parámetro que se está estimando y \(\mathbb E_{\theta}\) es el valor esperado bajo la distribución de probabilidad \(f(x\vert \theta)\). A la diferencia entre \(\mathbb{E}[\delta(x)]\) y \(g(\theta)\) se le conoce como el sesgo del estimador.
Es importante distinguir dos conceptos relacionados: un estimador es una función de la muestra —una variable aleatoria que varía de muestra en muestra—, mientras que una estimación es el valor numérico concreto que produce ese estimador para una muestra particular. Cuando escribimos \(\delta(X_1,\dots,X_n)\) con letras mayúsculas, nos referimos al estimador como variable aleatoria; cuando sustituimos datos observados \(x_1,\dots,x_n\), obtenemos la estimación \(\delta(x_1,\dots,x_n)\). El insesgamiento es una propiedad del estimador (como variable aleatoria), no una garantía sobre ninguna estimación individual. A lo largo del capítulo usaremos \(\delta(x)\) cuando nos refiramos a un estimador genérico; en ejemplos concretos adoptaremos la notación específica del parámetro de interés (por ejemplo, \(\hat{\theta}\), \(T\), \(\theta_U\)).
Ejemplo 7.1 Un ejemplo de un estimador insesgado es el promedio muestral \(\bar{X}_n\) cuando tenemos una muestra \(X_1,\dots,X_n\) de una distribución con media \(\mu\) cualquiera. En este caso: \[
\mathbb E[\bar{X}_n] = \dfrac 1n \sum_{i=1}^n\mathbb E(X_i) = \mu
\]
Lo que significa que \(\bar{X}_n\) es estimador insesgado de la media poblacional \(\mu\).
Aunque la propiedades ser insesgado pareciera natural en los estimadores, no siempre tenemos esto.
Ejemplo 7.2 Considere una muestra \(X_1, X_2, X_3 \sim \mathrm{Exp}(\theta)\) con función de densidad \(f(x|\theta) = \theta e^{-\theta x}\).
De acuerdo a los ejemplos de capítulos pasados, el estimador de máxima verosimilitud de \(\theta\) es
Podemos preguntarnos si \(\hat\theta\) es un estimador insesgado de \(\theta\). Para responder a esta pregunta, realizamos una simulación para estimar el sesgo de \(\hat\theta\) utilizando valores generados aleatoriamente.
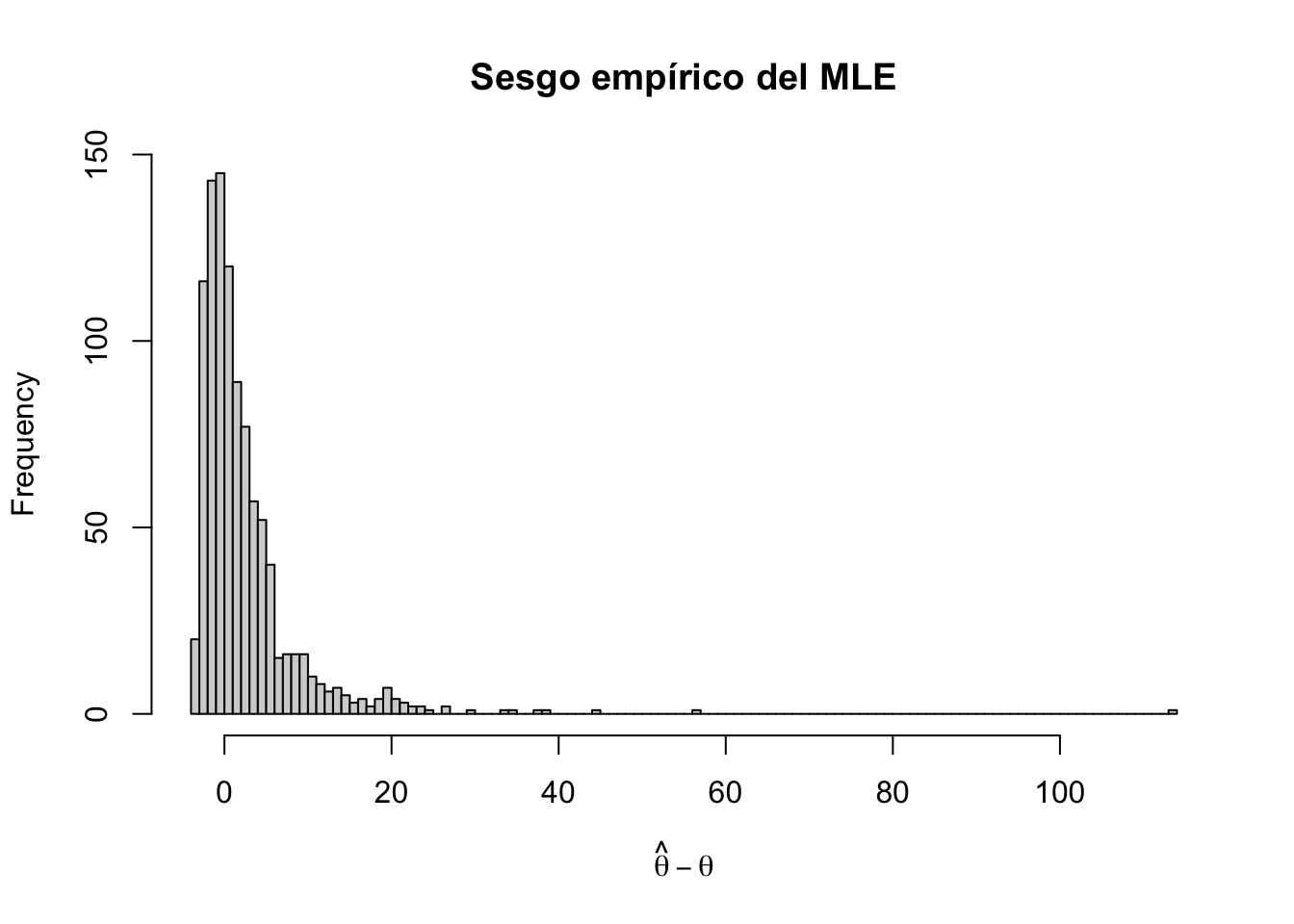
set.seed(42)theta_real <-5# Generar 1000 muestras de tamaño n=3 de Exp(θ)muestra <-matrix(rexp(n =1000*3, rate = theta_real), ncol =3)# T = suma de la muestra (estadístico suficiente para θ)suma_muestra <-apply(X = muestra, MARGIN =1, FUN = sum)# MLE: θ̂ = 3/Ttheta_techo <-3/ suma_muestra# Histograma del sesgo empírico (esperamos sesgo ≈ θ/2 = 2.5)hist(theta_techo - theta_real, breaks =100,xlab =expression(hat(theta) - theta),main ="Sesgo empírico del MLE")
Código
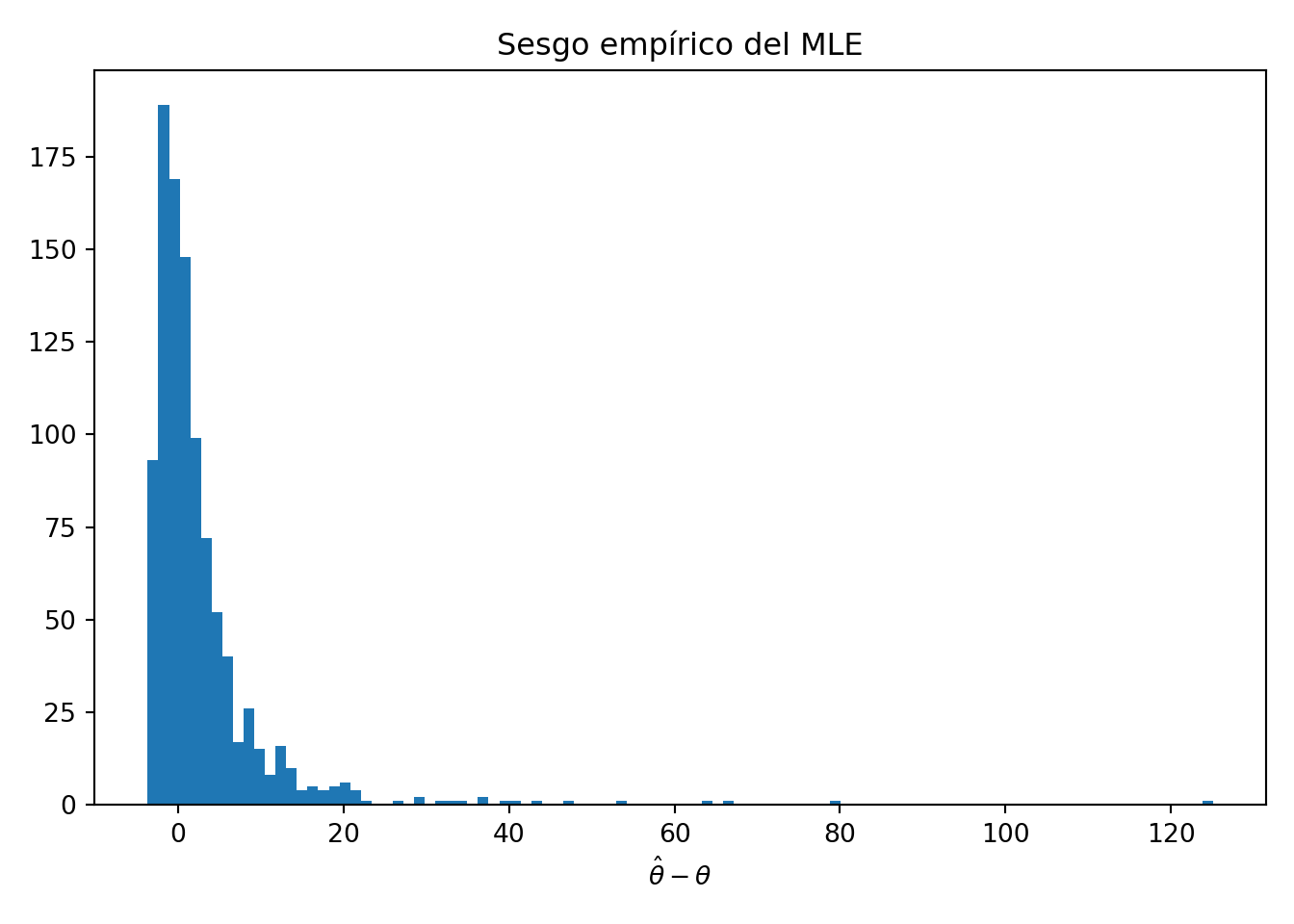
import numpy as npimport matplotlib.pyplot as pltrng = np.random.default_rng(42)theta_real =5# Generar 1000 muestras de tamaño n=3 de Exp(θ)muestra = rng.exponential(scale=1/theta_real, size=(1000, 3))# T = suma de la muestra (estadístico suficiente para θ)suma_muestra = muestra.sum(axis=1)# MLE: θ̂ = 3/Ttheta_techo =3/ suma_muestra# Histograma del sesgo empírico (esperamos sesgo ≈ θ/2 = 2.5)plt.hist(theta_techo - theta_real, bins=100)plt.xlabel(r"$\hat{\theta} - \theta$")plt.title("Sesgo empírico del MLE")plt.tight_layout()plt.show()
El histograma muestra la diferencia entre las estimaciones \(\hat{\theta}\) y el valor verdadero \(\theta\). Teóricamente, podemos calcular el sesgo de \(\hat{\theta}\) y encontramos que:
Por lo que \(\hat \theta\) es un estimador sesgado, con sesgo \[
\text{sesgo}(\hat\theta) = \dfrac{3\theta}{2} -\theta = \dfrac \theta 2.
\]
Si por ejemplo \(\theta=5\), entonces la diferencia debería ser aproximadamente \(\dfrac{5}{2}\approx 2.5\). Calculemos la diferencia promedio entre el estimador y el valor real:
Con esto concluimos que el estimador de máxima verosimilitud no siempre es insesgado. Cabe mencionar que, aunque el MLE puede ser sesgado para muestras finitas, bajo condiciones de regularidad es consistente (converge en probabilidad al verdadero parámetro cuando \(n\to\infty\)) y asintóticamente insesgado (su sesgo tiende a cero). Estas son propiedades distintas: la consistencia es más fuerte que el insesgamiento asintótico.
En un mundo ideal, nos gustaría tener estimadores insesgados pero que además tengan varianza pequeña. Nótese que la condición \(\text{Var}(\delta(x))\to 0\) es una propiedad asintótica: exige que la varianza del estimador se reduzca conforme crece el tamaño de muestra \(n\to\infty\), lo cual es parte de la definición de consistencia.
Ejemplo 7.3 Considere una muestra \(X_1, X_2, \dots, X_n \sim \mathrm{Exp}(\theta)\). De acuerdo a los ejemplos de capítulos pasados, el estimador de máxima verosimilitud de \(\theta\) es \(\frac{1}{\bar{X}_n}\)
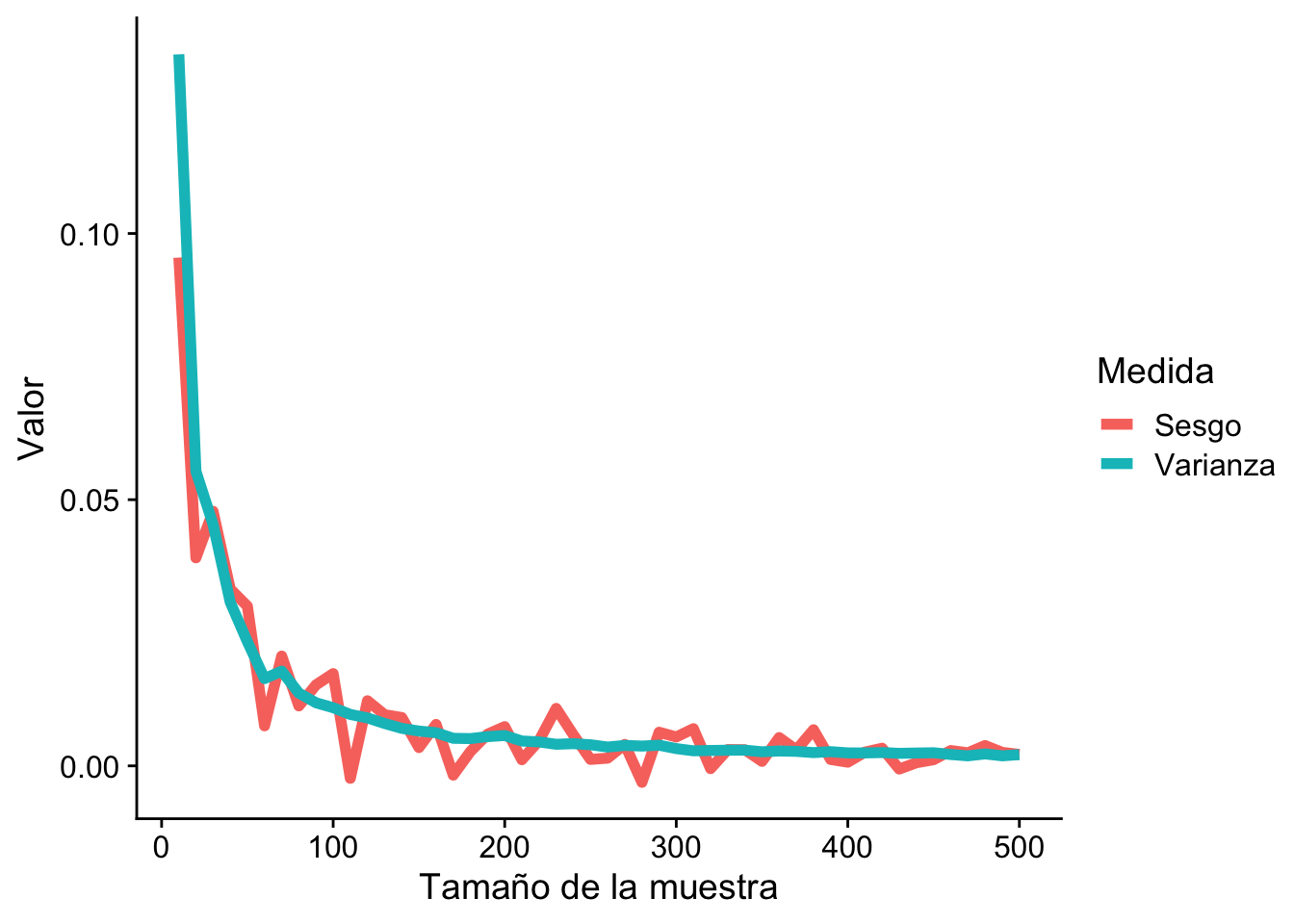
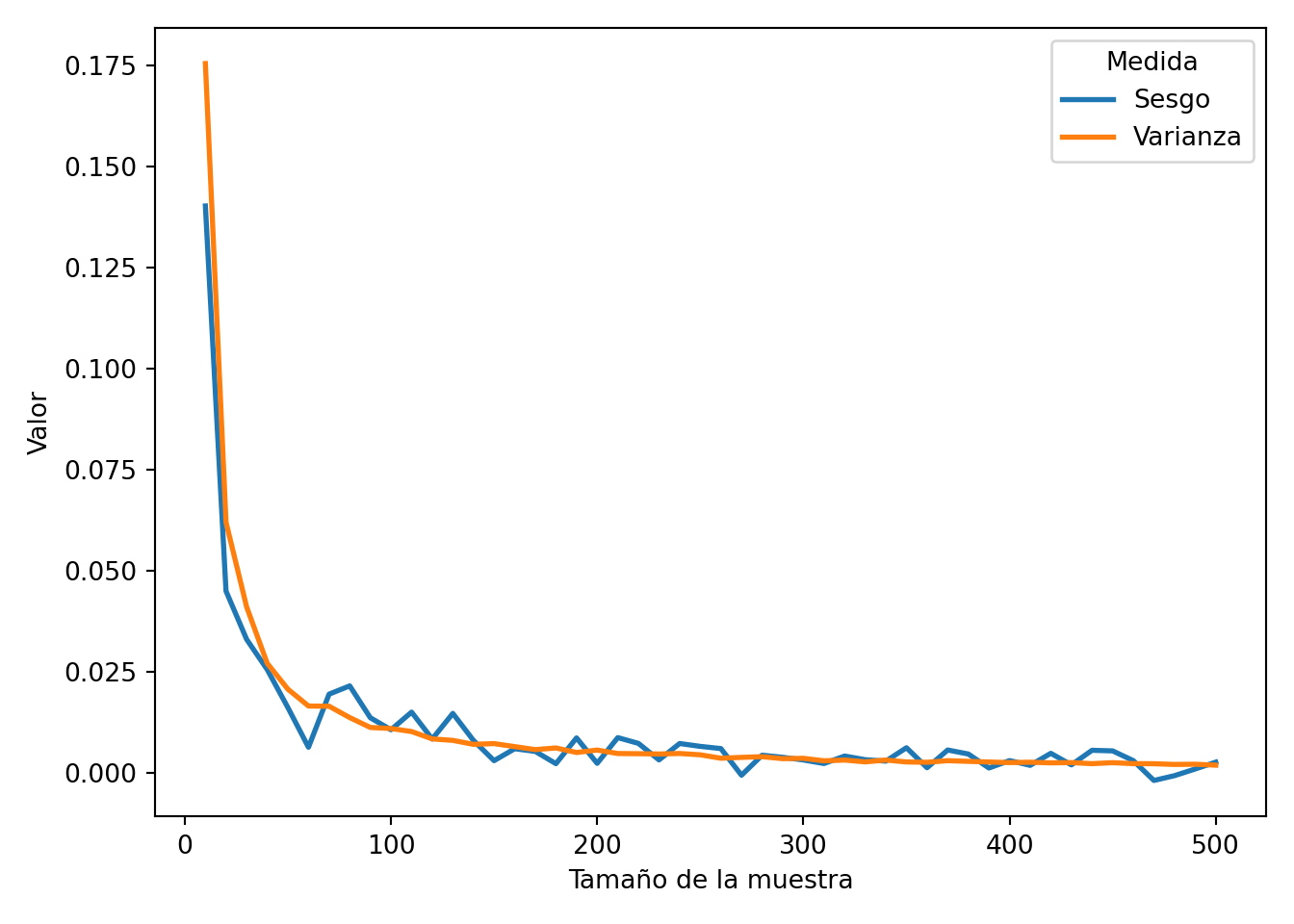
Generaremos múltiples muestras de una distribución exponencial con un \(\theta\) verdadero.
Estimaremos \(\theta\) para cada muestra utilizando el MLE.
Calcularemos el sesgo y la varianza de nuestras estimaciones.
Graficaremos cómo varían el sesgo y la varianza con el tamaño de la muestra.
Sesgo y Varianza del MLE para θ de una distribución exponencial
Sesgo y Varianza del MLE para θ de una distribución exponencial
Viendo el gráfico queda la pregunta
Importante
¿Cómo controlar sesgo y varianza?
Para esto definamos el error cuadrático medio (MSE) de \(\delta(x)=\hat{\theta}\) como \(\mathrm{MSE}(\hat{\theta}) = \mathbb{E}[(\hat{\theta}-\theta)^2]\).
Escribiendo la defnición de esta cantidad, podemos desagregar el MSE en dos partes:
\(\theta_{U}\) es mejor estimador en términos de MSE que el \(\hat\theta\).
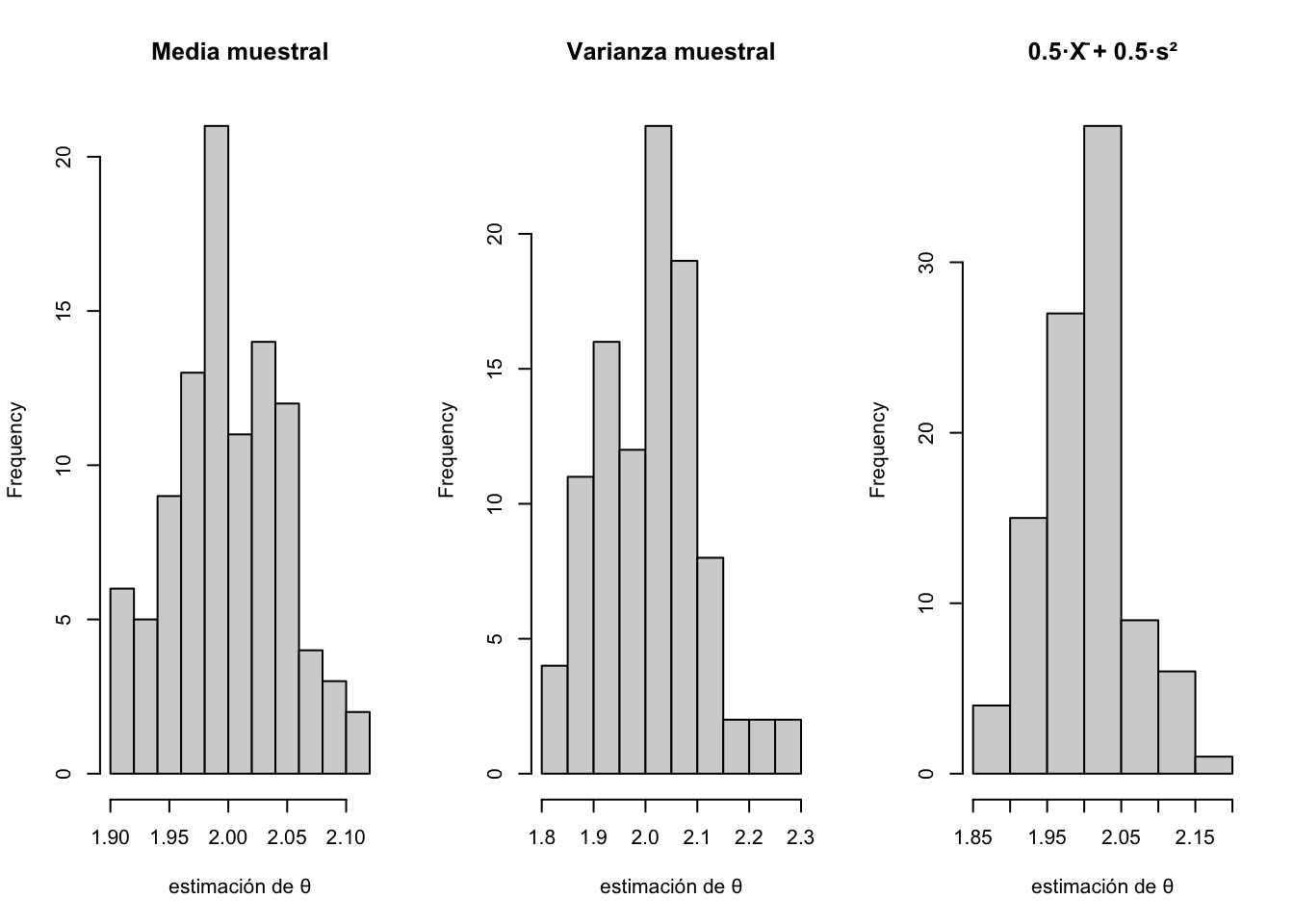
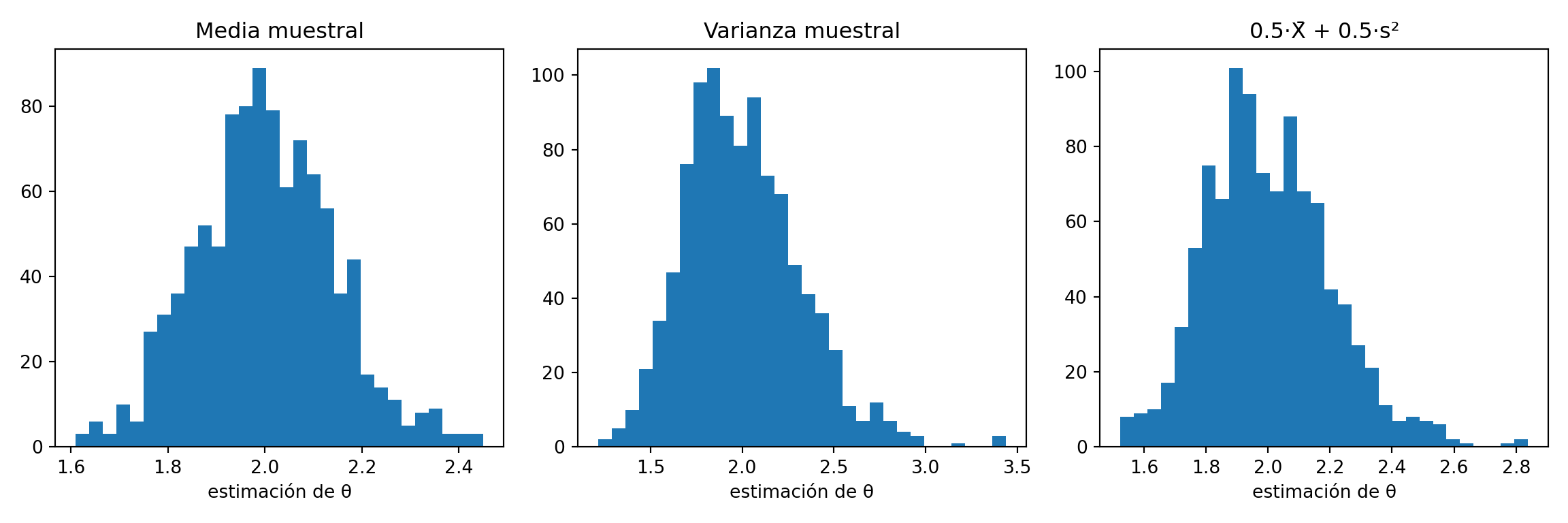
Observación. Bajo el enfoque bayesiano, si se asume la distribución a priori \(\theta \sim \text{Gamma}(1, 2)\) (forma, tasa) —equivalente a \(\theta \sim \text{Exponencial}(2)\)— y dado que \(T = \sum_{i=1}^{3}X_i \sim \text{Gamma}(3, \theta)\), la distribución posterior resulta ser \(\theta \mid T \sim \text{Gamma}(4, 2+T)\). El estimador de Bayes bajo pérdida cuadrática es la media posterior: \[
\theta_{Bayes} = \dfrac{4}{2+T}.
\] Este estimador tiene un MSE menor que \(\hat\theta\) y \(\theta_U\), a costa de introducir un sesgo pequeño que proviene del prior. La ventaja bayesiana es más pronunciada con muestras pequeñas; cuando \(n\to\infty\), el prior se diluye y \(\theta_{Bayes}\) converge al MLE.
Llegados a este punto, hemos estudiado con mucho detalle los estimadores de la media de una distribución. Hemos visto que, bajo ciertas condiciones de regularidad, estimadores como la media muestral \(\bar{X}_n\) son insesgados, suficientes, consistentes y eficientes para la media poblacional — aunque estas propiedades no se cumplen simultáneamente para todos los parámetros ni para todas las distribuciones. Sin embargo, en muchas ocasiones nos interesa encontrar un estimador insesgado de la varianza de una distribución. Para esto, consideremos una muestra \(X_1,\dots,X_n\) de una distribución \(F_{\theta}\) con varianza finita.
Ambas son idénticas a excepción del denominador \(n\) o \(n-1\). Sin embargo, la diferencia fundamental reside en este teorema.
Teorema 7.1 Si \(X_1,\dots, X_n \sim F_{\theta}\) con varianza finita y \(g(\theta) = \text{Var}(X_1)\) entonces \[
s^2 = \dfrac{1}{n-1}\sum(X_i-\bar{X}_n)^2
\] es un estimador insesgado de \(\sigma^2\).
Ejemplo 7.6 En caso de distribuciones normales, ¿Cuál estimador tiene menor MSE, \(\hat{\sigma}^2\) o \(s^2\)?
Defina \(T_c = c\sum_{i=1}^{n}\left(X_{i}-\bar{X}_{n}\right)^{2}\). Si \(c = 1/n\), \(T_c = \hat\sigma^2\) y si \(c = 1/(n-1)\), \(T_c = s^2\). De esta manera,
se encuentra que \(\hat c = \dfrac 1{n+1}\). Así, \(T_{\frac{1}{n+1}} = \dfrac{\sum_{i=1}^{n}\left(X_{i}-\bar{X}_{n}\right)^{2}}{n+1}\) es el mejor estimador de \(\sigma^2\) en el sentido de MSE. Aunque se puede demostrar que este estimador es inadmisible.
Observación. Un estimador \(\delta_1\) es inadmisible si existe otro estimador \(\delta_2\) tal que \(\mathrm{MSE}(\delta_2) \leq \mathrm{MSE}(\delta_1)\) para todo \(\theta\), con desigualdad estricta para al menos un \(\theta\). En otras palabras, \(\delta_1\) es inadmisible cuando siempre existe una alternativa que no lo puede hacer peor. El estimador \(T_{1/(n+1)}\) es el óptimo en MSE dentro de la familia \(\{T_c\}\), pero fuera de esa familia existen estimadores que lo dominan.
Ejercicio 7.1 Calcule el MSE de \(\hat\sigma^2\) y \(s^2\) y compare los resultados.
Observación. En el capítulo sobre estadísticos suficientes se estudiará el teorema de Rao-Blackwell: si \(\delta(X)\) es un estimador insesgado de \(\theta\) y \(T\) es un estadístico suficiente, entonces \(\delta^*(X) = \mathbb E[\delta(X)\mid T]\) es también insesgado y satisface \(\mathrm{Var}(\delta^*) \leq \mathrm{Var}(\delta)\) para todo \(\theta\). En otras palabras, siempre es posible mejorar la varianza de un estimador insesgado condicionando sobre el estadístico suficiente. Este resultado conecta directamente con el criterio de eficiencia que se desarrolla en las secciones siguientes.
TipIdeas clave: sesgo, varianza y MSE
Un estimador insesgado satisface \(\mathbb E[\delta(X)] = \theta\) para todo \(\theta\), pero el insesgamiento no garantiza que sea el mejor estimador.
El MSE descompone el error total en sesgo² + varianza; un estimador sesgado puede tener MSE menor que uno insesgado si su varianza es suficientemente pequeña.
El estimador que minimiza el MSE dentro de la familia \(\{T_c\}\) para la varianza normal es \(T_{1/(n+1)}\), con denominador intermedio entre \(n\) y \(n-1\).
El enfoque bayesiano permite incorporar información previa en forma de una distribución a priori, y el estimador resultante puede dominar a los clásicos en MSE a costa de un pequeño sesgo.
7.3 Información de Fisher
La Información de Fisher es una herramienta fundamental en inferencia estadística que nos permite cuantificar la cantidad de información que una muestra proporciona acerca de un parámetro desconocido.
Consideremos una variable aleatoria \(X\) con función de densidad \(f(x|\theta)\), donde \(\theta \in \Omega \subset \mathbb R\) es un parámetro fijo. \(X\) satisface las siguientes condiciones de regularidad:
Soporte independiente de \(\theta\): para cada \(x \in \mathcal{X}\), \(f(x|\theta) > 0\) para todo \(\theta \in \Omega\). El dominio de \(f\) no depende de \(\theta\).
Diferenciabilidad: \(f(x|\theta)\) es dos veces diferenciable con respecto a \(\theta\).
Intercambio derivada-integral: es posible intercambiar el orden de la derivada y la integral: \[\begin{equation*}
\dfrac{d}{d\theta}\int_{\mathcal X}f(x|\theta)\,dx = \int_{\mathcal X}\dfrac{d}{d\theta}f(x|\theta)\,dx.
\end{equation*}\]
Ejemplo 7.7 Si \(X\) sigue una distribución uniforme en el intervalo \([0,\theta]\), es decir, \(X\sim\text{Unif}[0,\theta]\), entonces \(f(x|\theta) = 1_{(0,\theta)}(x)\). En este caso, el primer supuesto no se cumple, ya que si \(x>\theta\), entonces \(f(x|\theta) = 0\). Esto significa que el dominio de la distribución no debe depender de \(\theta\).
La siguiente función será clave para definir la información de Fisher.
Definición 7.1 La log-verosimilitud de \(X\) es: \[
\lambda(x|\theta) = \ln f(x|\theta).
\] La función score es su primera derivada con respecto a \(\theta\): \[
\lambda^{\prime}(x|\theta) = \dfrac{\partial}{\partial\theta}\ln f(x|\theta).
\] La segunda derivada es: \[
\lambda^{\prime\prime}(x|\theta) = \dfrac{\partial^2}{\partial\theta^2}\ln f(x|\theta).
\]
Definición 7.2 Si \(X\) y \(f(x|\theta)\) cumplen con los supuestos mencionados, la información de Fisher de \(X\) está dada por: \[
I(\theta) =\mathbb E[(\lambda'(x|\theta))^2]
\] Donde la esperanza es una integral o suma, dependiendo de si \(X\) es continua o discreta. Por ejemplo, para una variable continua: \[
I(\theta)=\int_{\mathcal{X}}\left[\lambda^{\prime}(x \mid \theta)\right]^{2} f(x \mid \theta) d x
\]
Teorema 7.2 Bajo las condiciones anteriores, y suponiendo que las dos derivadas de \(\int_{\mathcal X}f(x|\theta)dx\) con respecto a \(\theta\) (Supuesto 3) se pueden calcular al intercambiar el orden de integración y derivación. Entonces
Se concluye, además, que \(\lambda'(x|\theta)\) es centrada y su varianza es \(I(\theta)\).
La Información de Fisher es una herramienta esencial en inferencia estadística que nos permite cuantificar la cantidad de información que una muestra proporciona acerca de un parámetro desconocido.
TipPropiedades del score y la información de Fisher
Dada la log-verosimilitud \(\lambda(x\vert \theta) = \ln f(x\vert \theta)\), bajo las condiciones de regularidad se tienen los siguientes resultados:
\(\lambda^{\prime}(x\vert \theta)\) es una variable aleatoria.
La varianza de \(\lambda^{\prime}(x\vert \theta)\) es igual a la información de Fisher: \[\begin{equation*}
\mathrm{Var}[\lambda^{\prime}(x\vert \theta)] = I(\theta) = - \mathbb E[\lambda^{\prime\prime}(x|\theta)].
\end{equation*}\]
Ejemplo 7.8 Si \(X\sim \text{Bernoulli}(p)\), entonces:
La función de densidad es \(f(x|p) = p^x(1-p)^{1-x}\) para \(x=0,1\), la cual satisface el supuesto 1.
Se puede comprobar que satisfacen el supuesto 3, es decir, \(\int_{\mathcal{X}} \frac{d}{dp}f(x|p)dx = \frac{d}{dp}\int_{\mathcal{X}} f(x|p)dx\).
La log-verosimilitud es \(\lambda(x|p) = x\ln p + (1-x)\ln(1-p)\).
Ejemplo 7.9 Para \(X\sim N(\mu,\sigma^2)\) con \(\mu\) desconocida y \(\sigma^2\) conocida:
La función de densidad es: \[
f(x\mid\mu) = \dfrac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\dfrac 1{2\sigma^2}(x-\mu)^2\right)
\] .
El tercer supuesto se cumple ya que \[\begin{align*}
\dfrac d{d\mu}\int_{\mathbb R} f(x|\mu)dx
& = \int_{\mathbb R}f'(x|\mu)dx \\
& = \int_{\mathbb R} \dfrac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} \cdot \dfrac{x-\mu}{\sigma^2}\,dx \\
& = \dfrac{1}{\sigma} \underbrace{\int_{\mathbb R}\dfrac{u}{\sqrt{2\pi}}e^{-\frac{u^2}{2}}du}_{\mathbb E[N(0,1)]\,=\,0} = 0, \quad u = \dfrac{x-\mu}\sigma
\end{align*}\]
Entonces:
La log-verosimilitud es \(\lambda(x|\mu) = -\dfrac 12 \ln (2\pi\sigma^2)-\dfrac 1{2\sigma^2}(x-\mu)^2\).
Las derivadas de la log-verosimilitud son:
\(\lambda'(x\mid\mu) = \dfrac{x-\mu}{\sigma^2}\).
\(\lambda''(x\mid\mu) = -\dfrac 1{\sigma^2}\).
La información de Fisher para esta distribución es: \[
I(\mu) = -\mathbb E[\lambda^{\prime\prime}(x\mid\mu)] = \dfrac{1}{\text{Var}(X)}
\]
Estos ejemplos fueron estimados usando solo un dato \(X\) de la distribución correspondiente. Sin embargo, este resultado se puede extender a una muestra \(X_1,\dots,X_n\)..
Definición 7.3 Suponga que \(X = (X_1,\dots,X_n)\) muestra de \(f(x|\theta)\) donde \(f\) satisface las condiciones anteriores. Defina \(\lambda_n(x\mid\theta) = \ln f_n(x|\theta)\). La información de Fisher de \(X\) es
Observación. La fórmula anterior, no es tan útil como quisieramos. En particular observe que \[
\lambda_n(x|\theta) = \ln f_n(x|\theta) = \sum_{i=1}^{n} \lambda(X_i|\theta)
\] lo que implica que \[
\lambda^{\prime\prime}_n(x|\theta) = \sum_{i=1}^n\lambda^{\prime\prime}(X_i|\theta).
\] De esta forma, \[
I_n(\theta) = -\mathbb E[\lambda^{\prime\prime}_n(x|\theta)] = - \sum_{i=1}^n\mathbb E[\lambda^{\prime\prime}(X_i|\theta)] = nI(\theta).
\]
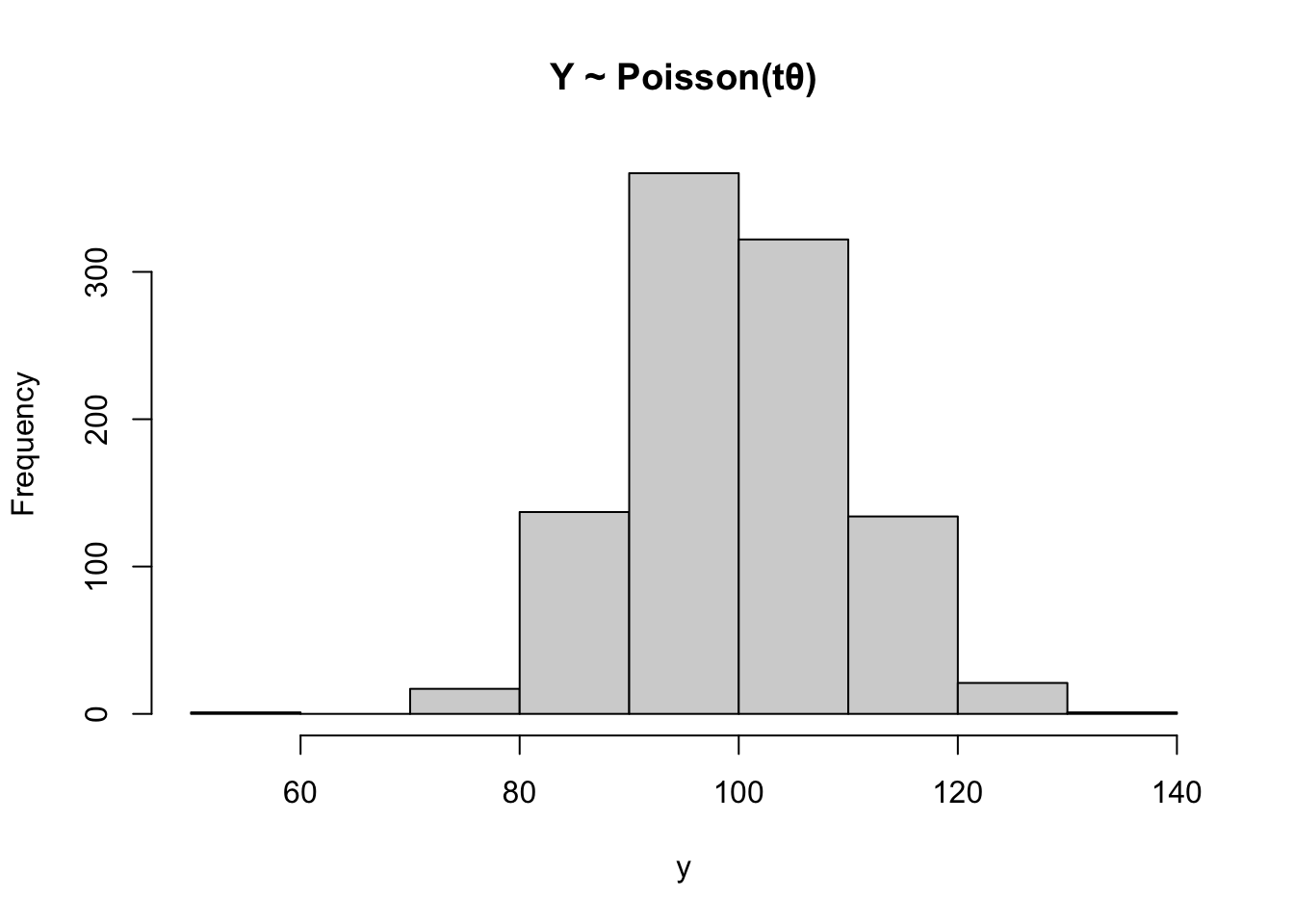
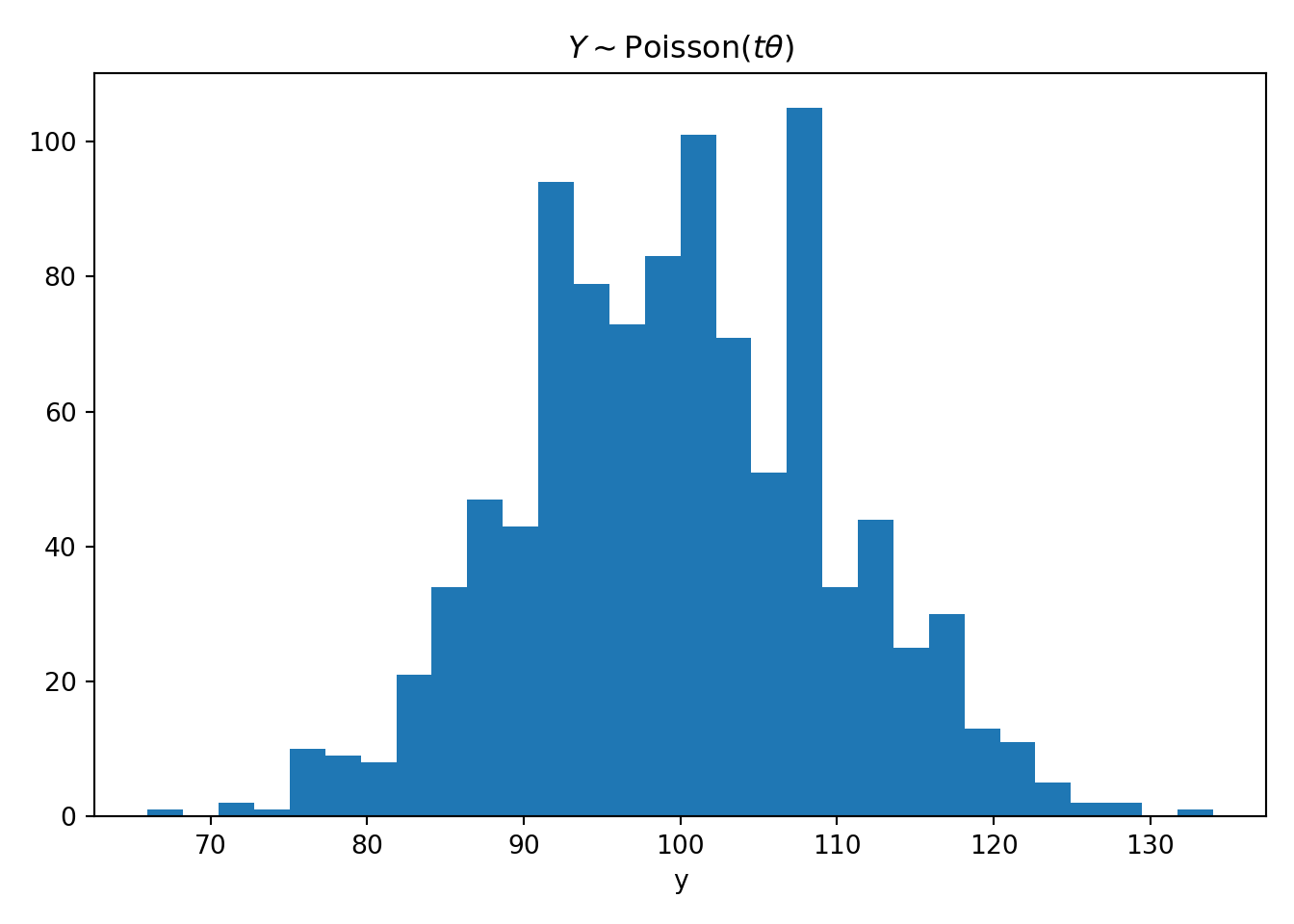
Ejemplo 7.10 Suponga que una compañía quiere conocer como se comportan sus clientes en sus tiendas. Hay dos propuestas para este modelo
Un modelo Poisson de parámetro \(t\theta\) (\(t\) es cualquier valor) para determinar la tasa promedio de llegada de clientes. \(Y\sim \text{Poisson}(\theta t)\).
Un modelo donde cada cliente es una v.a. exponencial con tasa de llegada \(\theta\) y al final se sumará todas las variables para obtener una \(\mathrm{Gamma}(n,\theta)\). \(X\sim \sum_{i=1}^{n}\text{Exp}(\theta) = \Gamma(n,\theta)\)
El tiempo de llegada de cada cliente es independiente.
¿Cuál variable contiene más información de \(\theta\)\(X\) o \(Y\)?
A partir de este ejercicio vamos a hacer un pequeño ejemplo de simulación.
Suponga que \(t\) es el tiempo que se quiere medir la cantidad de clientes (minutos), \(\theta\) es la cantidad de clientes por minuto y \(n\) es el número de clientes que entran.
theta <-5tiempo <-20# t = tiempo (minutos)clientes <- tiempo * theta # n = número de clientes (coincide con t·θ)muestra_y <-rpois(n =1000, lambda = tiempo * theta)muestra_x <-rgamma(n =1000, shape = clientes, rate = theta)
Código
import numpy as nprng_fc = np.random.default_rng(42)theta_fc =5tiempo_fc =20# t = tiempo (minutos)clientes_fc = tiempo_fc * theta_fc # n = número de clientes (coincide con t·θ)muestra_y_fc = rng_fc.poisson(lam=tiempo_fc * theta_fc, size=1000)# scipy/numpy usa scale=1/rate → scale=1/thetamuestra_x_fc = rng_fc.gamma(shape=clientes_fc, scale=1/theta_fc, size=1000)
Según lo estimado ambas informaciones de Fisher debería dar aproximadamente igualdad.
Ejercicio 7.2 Basado en los valores de la simulación, proponga dos valores de \(t\) para que
\(X\) tenga más información que \(Y\).
\(Y\) tenga más información que \(X\).
TipIdeas clave: información de Fisher
La información de Fisher\(I(\theta)\) cuantifica cuánto “habla” una observación sobre \(\theta\): distribuciones más concentradas alrededor de \(\theta\) tienen mayor información.
Para \(n\) observaciones i.i.d., la información escala linealmente: \(I_n(\theta) = nI(\theta)\).
La información de Fisher no está definida para distribuciones cuyo soporte depende de \(\theta\) (como la Uniforme\([0,\theta]\)), ya que los supuestos de regularidad no se cumplen.
Dos distribuciones distintas (Poisson y Gamma en el ejemplo de clientes) pueden contener la misma información de Fisher sobre \(\theta\) cuando modelan fenómenos duales del mismo proceso estocástico.
7.4 Desigualdad de Cramér-Rao
La información de Fisher no solo mide cuánto sabe la muestra sobre \(\theta\): también impone un límite inferior a qué tan preciso puede ser cualquier estimador insesgado. Este límite es la cota de Cramér-Rao, y constituye uno de los resultados más importantes de la teoría de estimación. Un estimador que alcanza exactamente esta cota se llama eficiente, y en ese caso no existe ningún estimador insesgado con menor varianza.
Teorema 7.3 Si \(X = (X_1,\dots, X_n)\) muestra de \(f(x|\theta)\). Todos los supuestos anteriores son válidos para \(f\). Sea \(T = r(X)\) un estadístico con varianza finita. Sea \(m(\theta) = \mathbb E_{\theta}[T]\) y asuma que \(m\) es diferenciable. Entonces:
La igualdad se da si y solo si existen funciones \(u(\theta)\) y \(v(\theta)\) que solo dependen de \(\theta\) tales que \[
T = u(\theta)\lambda_n'(x|\theta) + v(\theta).
\]
NotaPrueba
Para el caso univariado: \[
\int_{\mathcal X}f'(x|\theta)dx = 0.
\]
\[\begin{equation*}
m(\theta)=\int_{\mathcal{X}^n} \ldots \int_{S} r(\boldsymbol{x}) f_{n}(\boldsymbol{x} \mid \theta) d x_{1} \ldots d x_{n}
\end{equation*}\]
Usando el supuesto de intercabio de integrales, tenemos que \[\begin{equation*}
m^{\prime}(\theta)=\int_{\mathcal{X}^n} \ldots \int_{S} r(\boldsymbol{x}) f_{n}^{\prime}(\boldsymbol{x} \mid \theta) d x_{1} \ldots d x_{n}
\end{equation*}\]
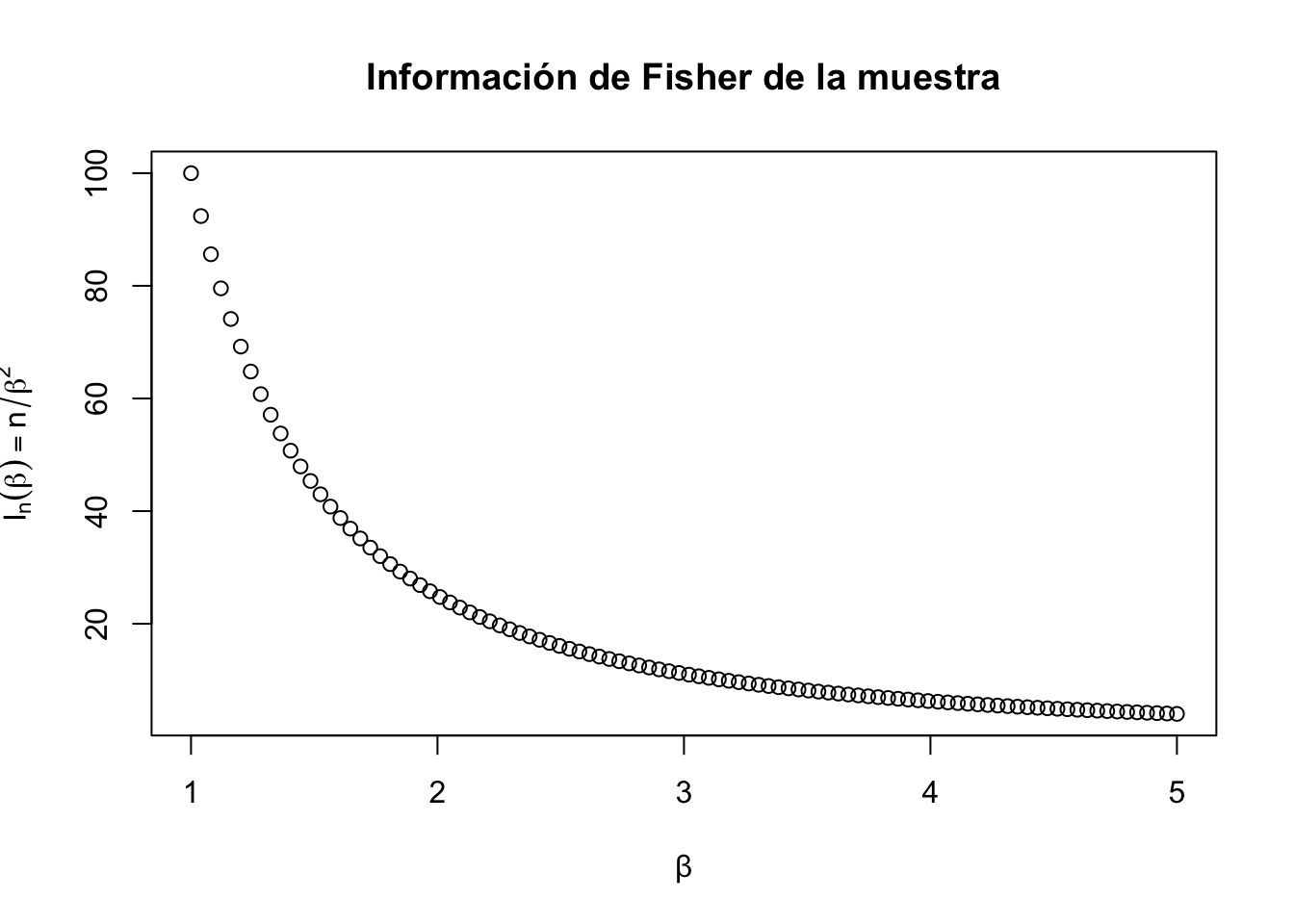
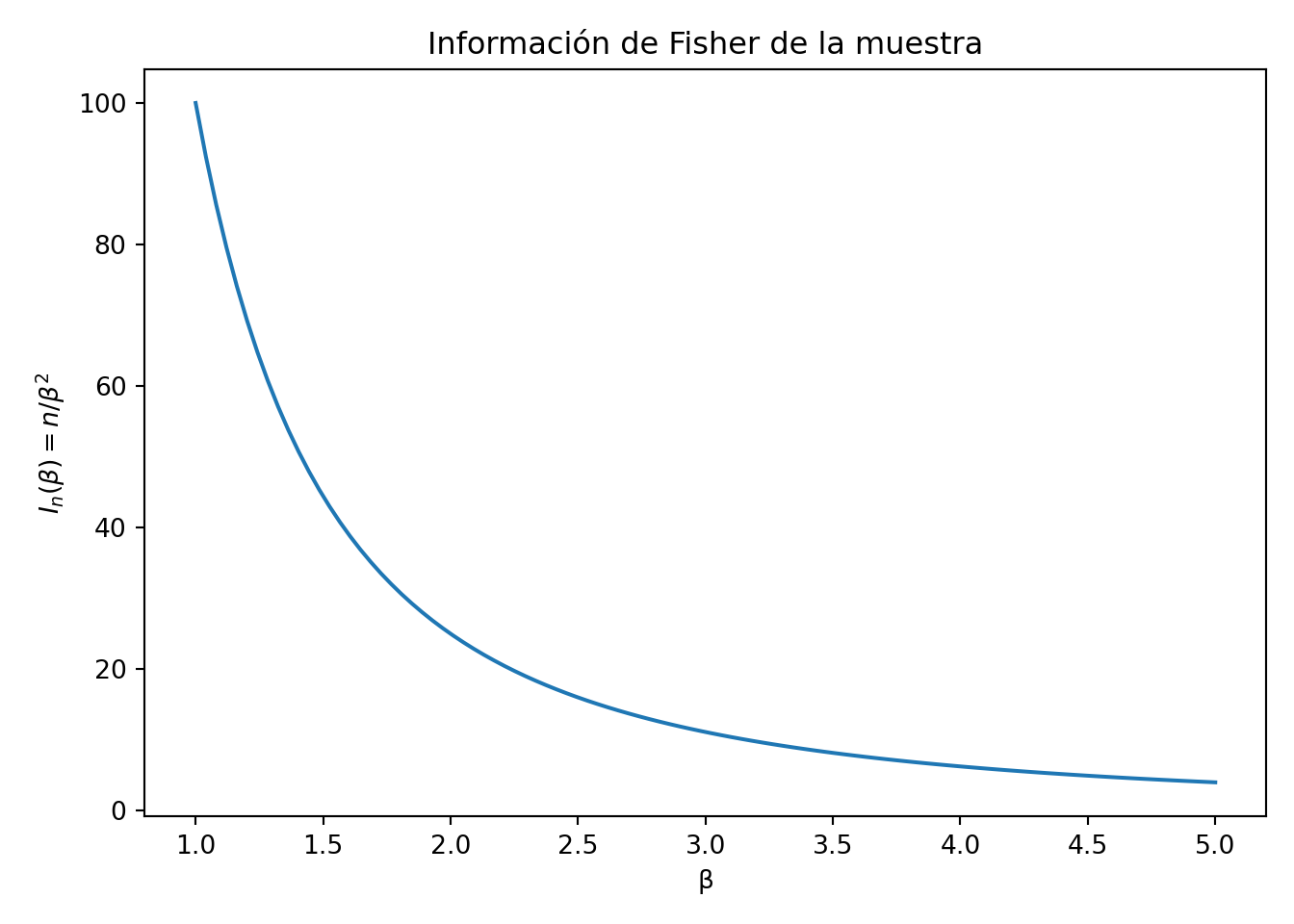
beta <-seq(1, 5, length.out =100)n <-100lista_muestras <-lapply(X = beta,FUN =function(b) {matrix(rexp(n = n *500, rate = b), nrow =500) })# I_n(β) = n/β² decrece cuando β creceplot(beta, n / beta^2,xlab ="β", ylab =expression(I[n](beta) == n/beta^2),main ="Información de Fisher de la muestra")
Código
import numpy as npimport matplotlib.pyplot as pltrng_cr = np.random.default_rng(42)beta_vals = np.linspace(1, 5, 100)n_cr =100# Generar listas de muestras para cada valor de βlista_muestras_py = [rng_cr.exponential(scale=1/b, size=(500, n_cr)) for b in beta_vals]# I_n(β) = n/β² decrece cuando β creceplt.plot(beta_vals, n_cr / beta_vals**2)plt.xlabel("β")plt.ylabel(r"$I_n(\beta) = n/\beta^2$")plt.title("Información de Fisher de la muestra")plt.tight_layout()plt.show()
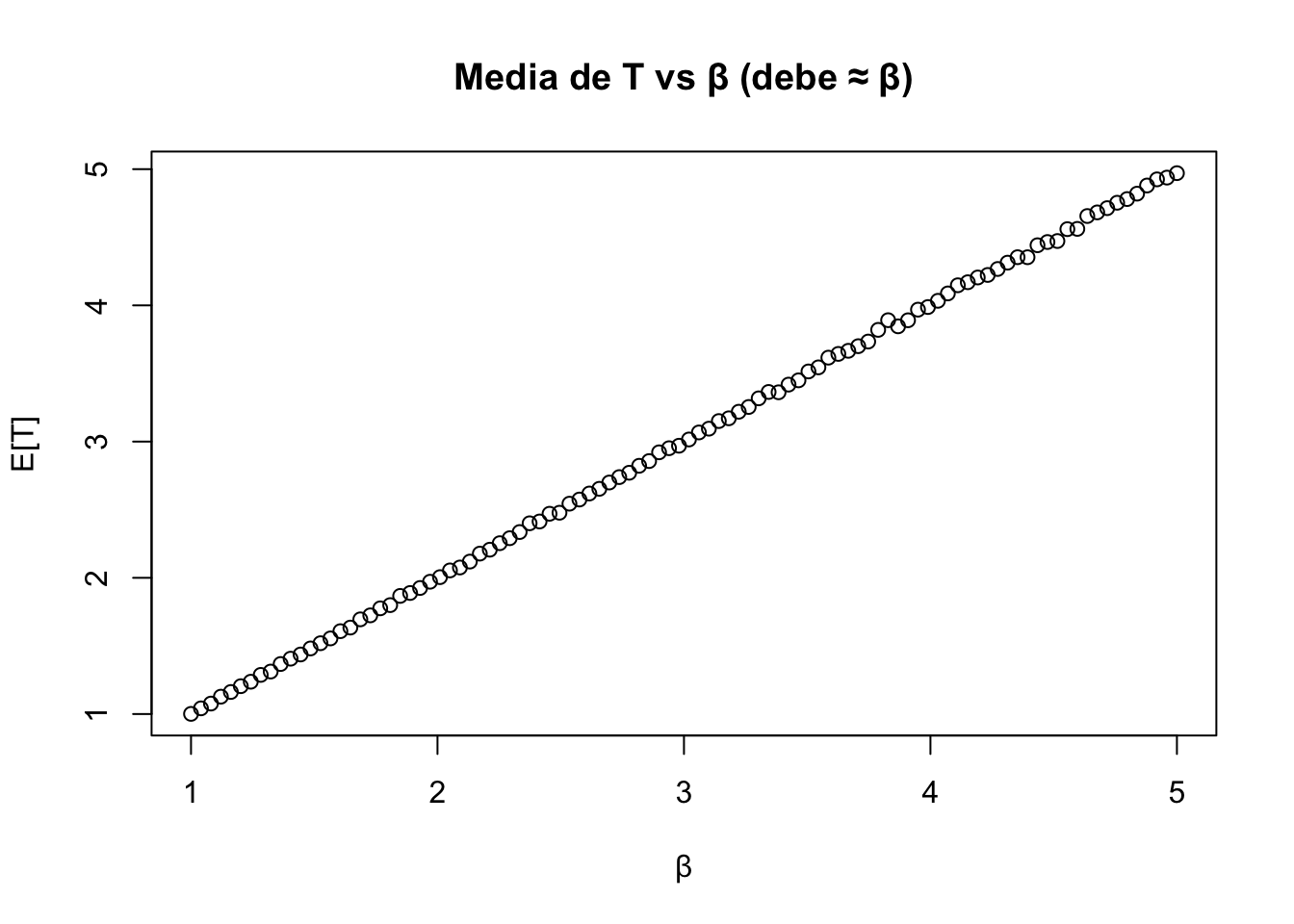
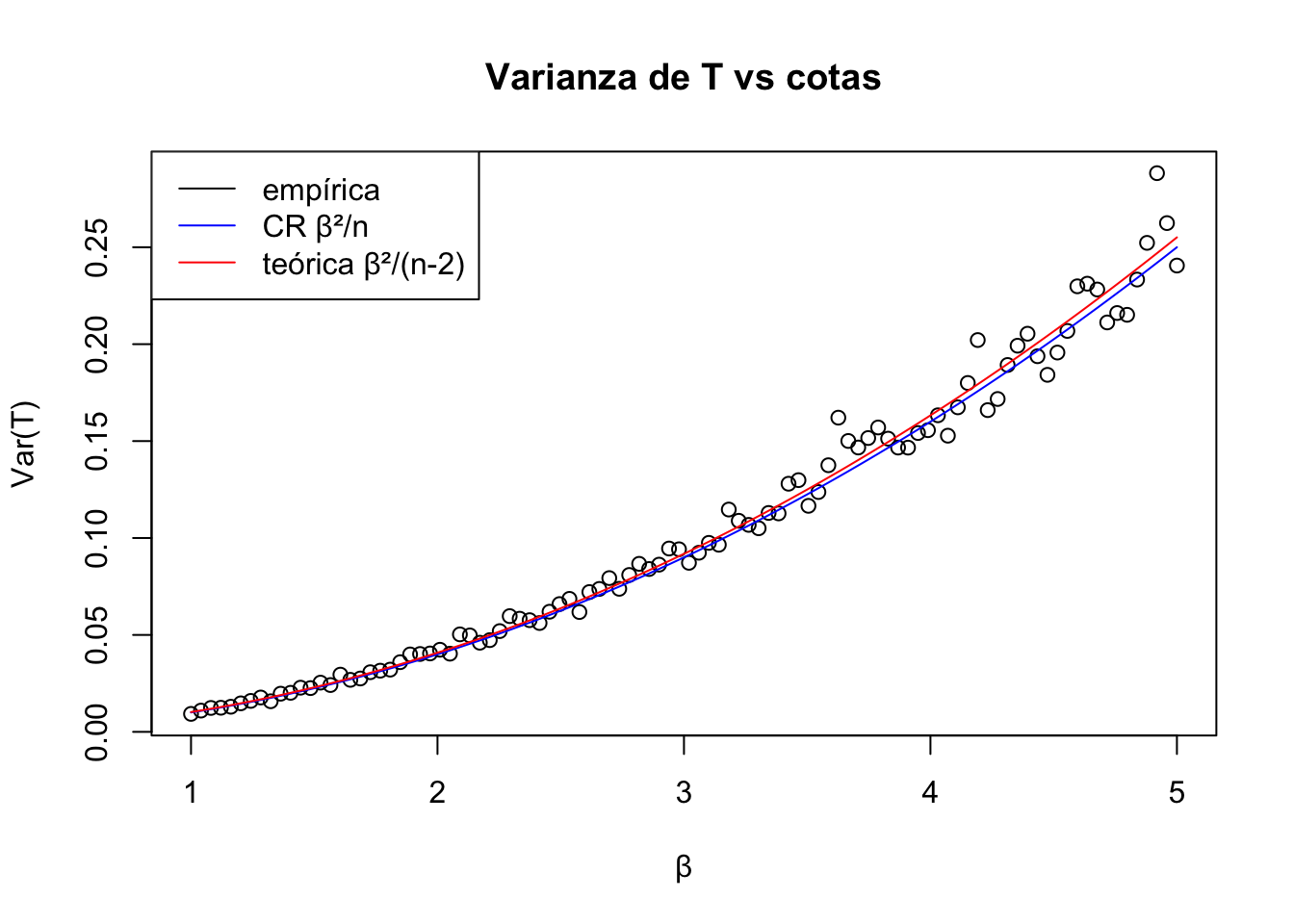
Considere el estadístico \(T = \dfrac{n-1}{\sum_{i=1}^n X_i}\) es un estimador insesgado de \(\beta\). La varianza de \(T\) es \(\dfrac{\beta^2}{n-2}\).
La cota de Cramer Rao, si \(T\) es insesgado, es
\[
\dfrac 1{I_n(\beta)} = \dfrac{\beta^2}{n},
\]
por lo que \(T\) no satisface la cota de Cramer Rao.
Este comportamiento podemos observarlo con nuestro ejemplo numérico.
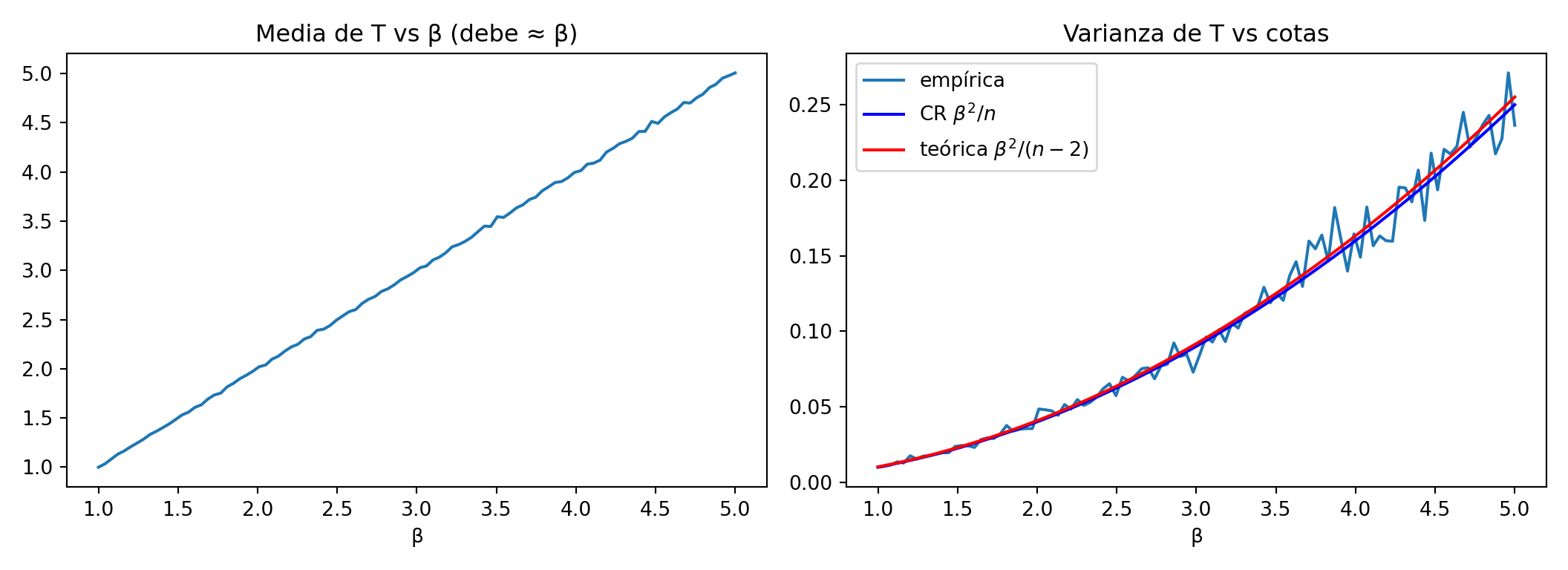
# T = (n-1)/sum(X_i): insesgado de β, pero Var(T) = β²/(n-2) > β²/n (cota CR)estimador1 <-sapply(X = lista_muestras,FUN =function(x) {apply(x, 1, function(xx) (n -1) /sum(xx)) })plot(beta, apply(X = estimador1, MARGIN =2, FUN = mean),xlab ="β", ylab ="E[T]", main ="Media de T vs β (debe ≈ β)")
Código
plot(beta, apply(X = estimador1, MARGIN =2, FUN = var),xlab ="β", ylab ="Var(T)", main ="Varianza de T vs cotas")lines(beta, beta^2/ n, col ="blue") # cota CR (no alcanzada)lines(beta, beta^2/ (n -2), col ="red") # varianza teórica reallegend("topleft", legend =c("empírica", "CR β²/n", "teórica β²/(n-2)"),col =c("black", "blue", "red"), lty =1)
Código
import numpy as npimport matplotlib.pyplot as plt# T = (n-1)/sum(X_i): insesgado de β, pero Var(T) = β²/(n-2) > β²/n (cota CR)estimador1_py = np.array([(n_cr -1) / m.sum(axis=1) for m in lista_muestras_py]).Tfig, axes = plt.subplots(1, 2, figsize=(11, 4))axes[0].plot(beta_vals, estimador1_py.mean(axis=0))axes[0].set_xlabel("β"); axes[0].set_title("Media de T vs β (debe ≈ β)")axes[1].plot(beta_vals, estimador1_py.var(axis=0, ddof=1), label="empírica")axes[1].plot(beta_vals, beta_vals**2/ n_cr, color="blue", label=r"CR $\beta^2/n$")axes[1].plot(beta_vals, beta_vals**2/ (n_cr -2), color="red", label=r"teórica $\beta^2/(n-2)$")axes[1].set_xlabel("β"); axes[1].set_title("Varianza de T vs cotas")axes[1].legend()plt.tight_layout()plt.show()
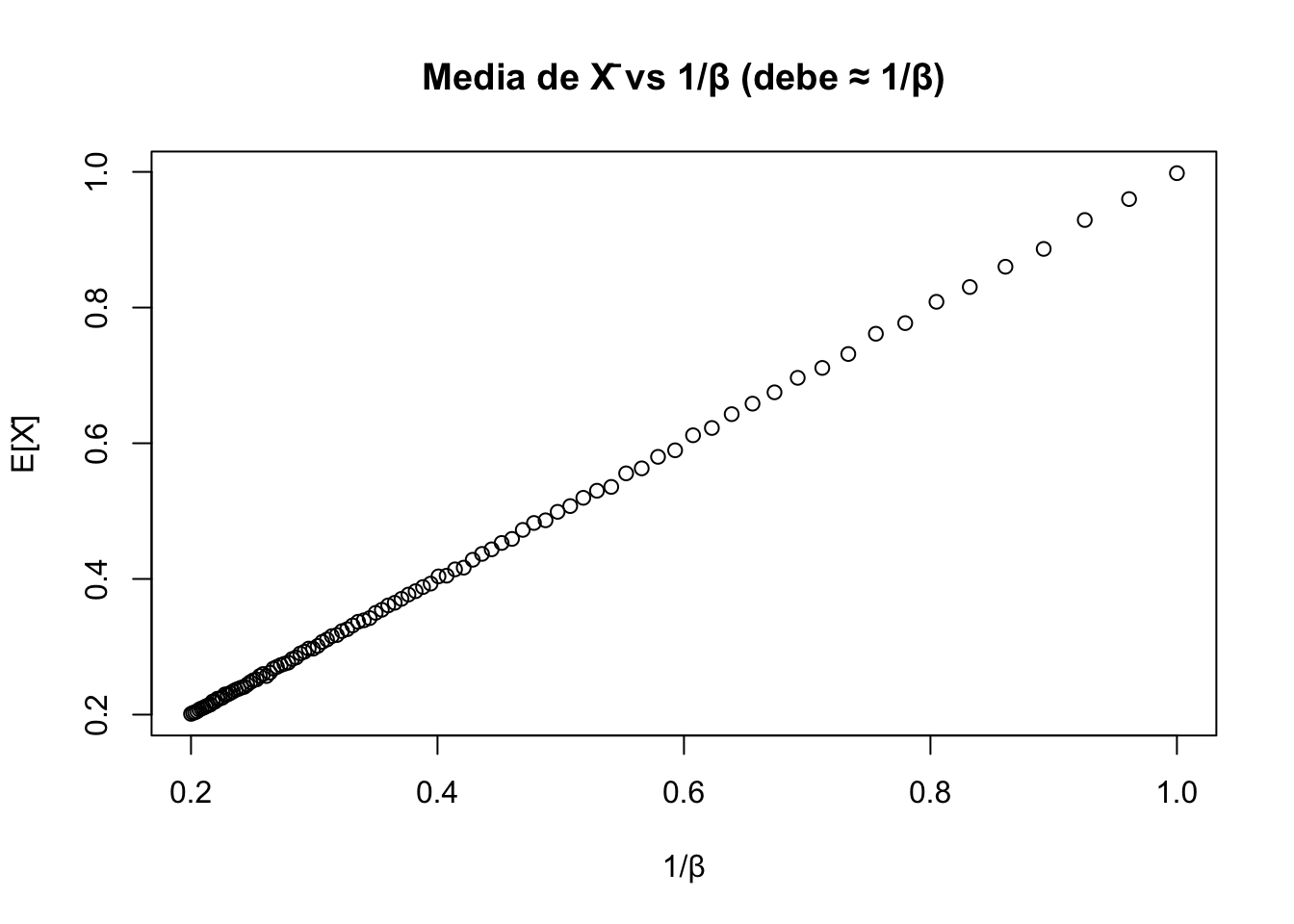
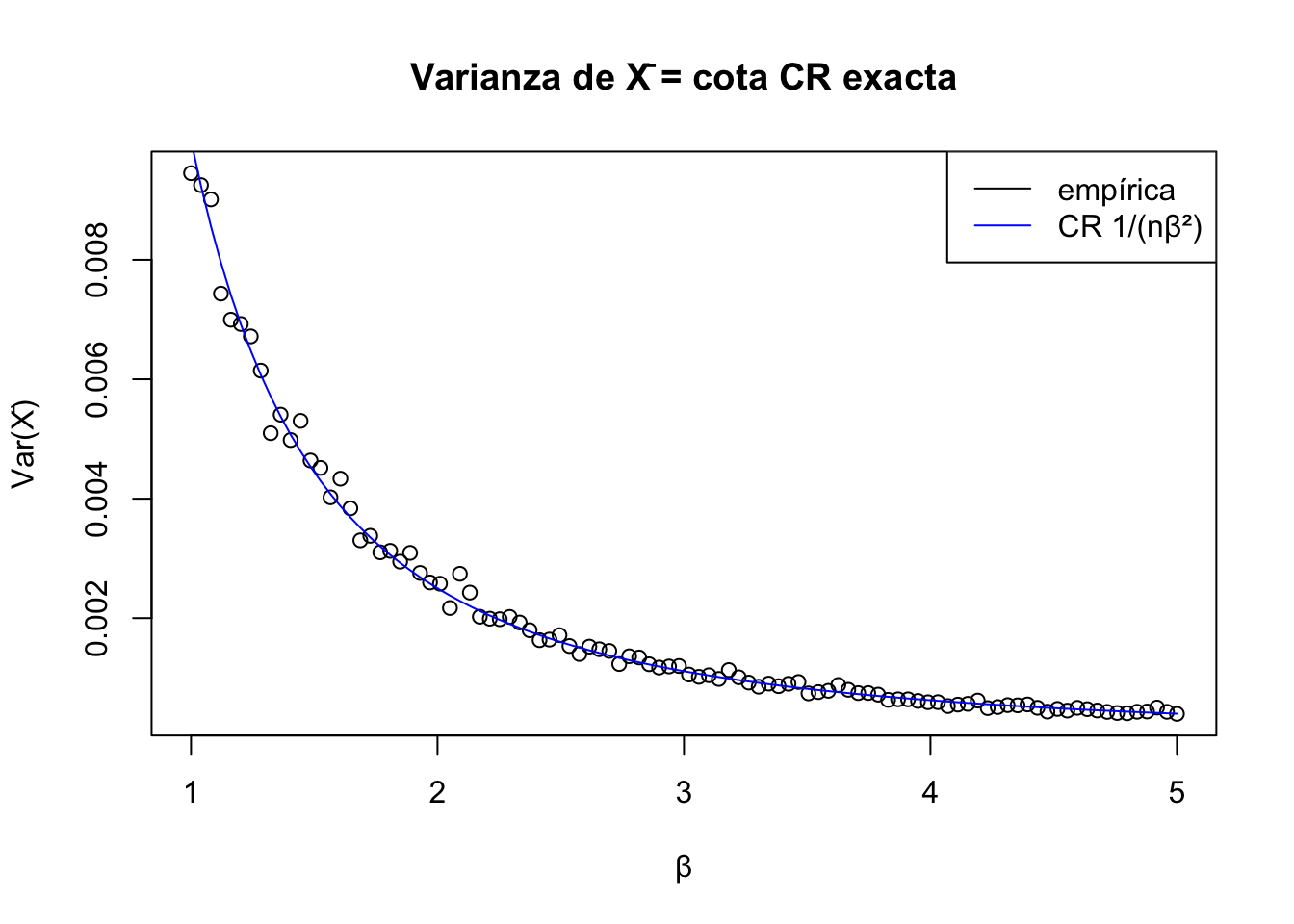
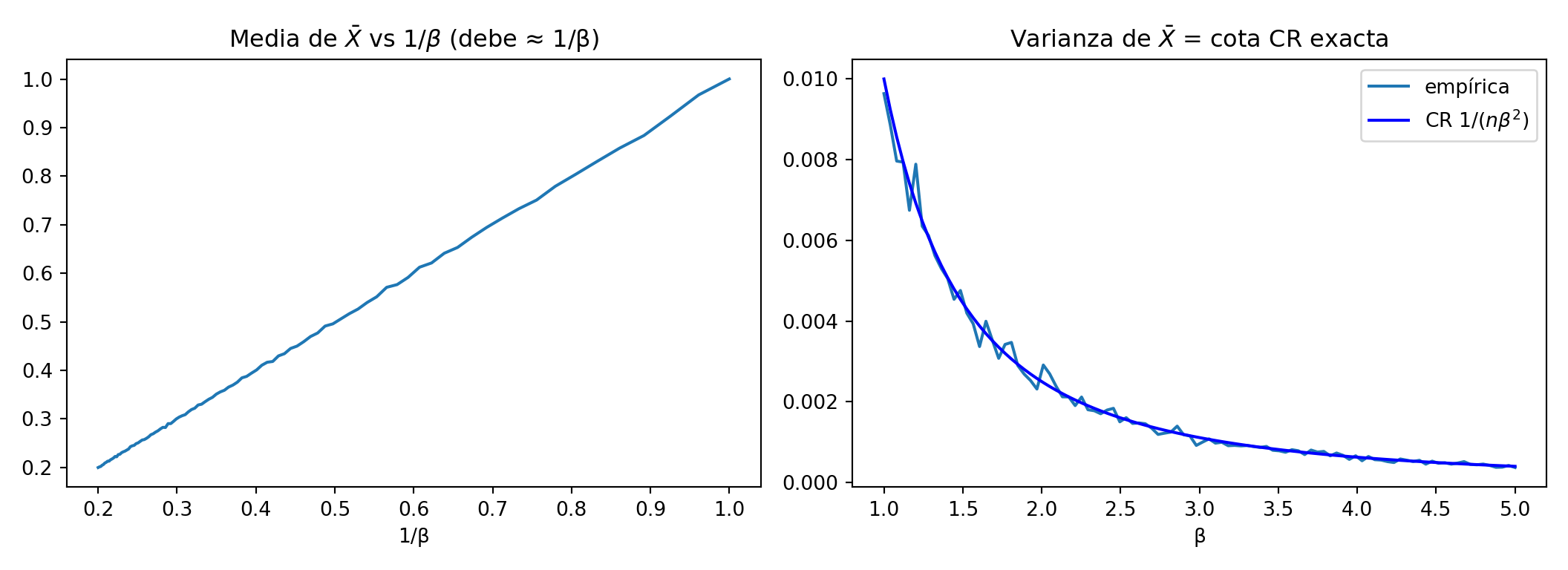
Ahora, estime \(\theta = \dfrac 1\beta = m(\beta)\). Un estimador insesgado de \(\theta\) es \(T =\bar{X}_n\):
\(\bar{X}_n\) satisface la cota de Cramer-Rao y además \[
\lambda^{\prime}(X|\beta) = \dfrac n\beta - n\bar{X}_n =\dfrac n\beta - nT \implies T = \underbrace{-\dfrac 1n}_{u(\beta)}\lambda_n'(X|\beta)+ \underbrace{\dfrac 1\beta}_{v(\beta)}.
\]
# X̄_n: estimador eficiente de 1/β = m(β) — alcanza la cota CR exactamenteestimador2 <-sapply(X = lista_muestras,FUN =function(x) {apply(x, 1, mean) })plot(1/ beta, apply(X = estimador2, MARGIN =2, FUN = mean),xlab ="1/β", ylab ="E[X̄]", main ="Media de X̄ vs 1/β (debe ≈ 1/β)")
Código
plot(beta, apply(X = estimador2, MARGIN =2, FUN = var),xlab ="β", ylab ="Var(X̄)", main ="Varianza de X̄ = cota CR exacta")lines(beta, 1/ (n * beta^2), col ="blue")legend("topright", legend =c("empírica", "CR 1/(nβ²)"),col =c("black", "blue"), lty =1)
Código
import numpy as npimport matplotlib.pyplot as plt# X̄_n: estimador eficiente de 1/β = m(β) — alcanza la cota CR exactamenteestimador2_py = np.array([m.mean(axis=1) for m in lista_muestras_py]).Tfig, axes = plt.subplots(1, 2, figsize=(11, 4))axes[0].plot(1/ beta_vals, estimador2_py.mean(axis=0))axes[0].set_xlabel("1/β"); axes[0].set_title(r"Media de $\bar{X}$ vs $1/\beta$(debe ≈ 1/β)")axes[1].plot(beta_vals, estimador2_py.var(axis=0, ddof=1), label="empírica")axes[1].plot(beta_vals, 1/ (n_cr * beta_vals**2), color="blue", label=r"CR $1/(n\beta^2)$")axes[1].set_xlabel("β"); axes[1].set_title(r"Varianza de $\bar{X}$ = cota CR exacta")axes[1].legend()plt.tight_layout()plt.show()
7.5 Estimadores eficientes
Ya sabemos que la cota de Cramér-Rao establece un piso para la varianza de cualquier estimador insesgado. La pregunta natural es: ¿existe algún estimador que alcance exactamente ese piso? A estos estimadores los llamamos eficientes, y representan el ideal teórico de precisión máxima dado el tamaño de muestra.
Definición 7.4 Sea \(T\) un estimador insesgado de \(m(\theta)\) con varianza finita. \(T\) es un estimador eficiente de \(m(\theta)\) si alcanza exactamente la cota de Cramér-Rao: \[
\text{Var}_\theta(T) = \dfrac{[m'(\theta)]^2}{I_n(\theta)} \quad \text{para todo } \theta \in \Omega.
\] Ningún otro estimador insesgado de \(m(\theta)\) puede tener varianza menor. La cota de Cramér-Rao puede no ser alcanzable — su utilidad es dar un piso teórico.
Ejemplo 7.12 Sea \(X_1,\dots, X_n\sim \text{Poisson}(\theta)\). \(\bar{X}_n\) es un estimador eficiente.
La información de Fisher de la muestra es \(I_n(\theta) = -\mathbb E[\lambda_n''(X|\theta)] = \dfrac{n}{\theta^2}\mathbb E[\bar{X}_n]\), y como \(\mathbb E[\bar{X}_n]=\theta\): \[
I_n(\theta) = \dfrac{n}{\theta^2}\cdot\theta = \dfrac n{\theta}.
\]
La cota de Cramér-Rao es \(\dfrac 1{I_n(\theta)} = \dfrac \theta n\), pero \[
\text{Var}(\bar{X}_n) = \dfrac{\text{Var}(X_{1})}{n} = \dfrac \theta n.
\] Por lo que \(\bar{X}_n\) es eficiente.
Los otros candidatos para estimar \(\theta\)\[
s^2=\dfrac 1{n-1}\sum_{i=1}^{n}\left(X_{i}-\bar{X}_{n}\right)^{2},
\] y \[
\alpha \bar{X}_{n} + (1-\alpha)s^{2}
\] no son lineales con respecto a \(\lambda^{\prime}(X|\theta)\) por lo que tienen mayor varianza que \(\bar{X}_n\).
TipIdeas clave: estimadores eficientes
Un estimador eficiente alcanza exactamente la cota de Cramér-Rao; es el más preciso posible entre todos los estimadores insesgados.
La eficiencia es rara en muestras finitas: en el ejemplo Poisson, \(\bar{X}_n\) es eficiente porque \(\lambda'_n\) es lineal en \(\bar{X}_n\).
\(s^2\) y \(\alpha\bar{X}_n + (1-\alpha)s^2\) no son eficientes para Poisson porque no tienen forma lineal en \(\lambda'_n\).
La cota de Cramér-Rao puede no ser alcanzable — su existencia da información valiosa aunque no haya estimador que la iguale.
7.6 Comportamiento asintótico del MLE
Hemos visto que algunos estimadores eficientes existen en muestras finitas, pero son la excepción. Sin embargo, para el MLE ocurre algo notable: aunque en muestras pequeñas puede ser sesgado e ineficiente, su comportamiento mejora sistemáticamente con \(n\). Los dos teoremas siguientes formalizan esto.
Teorema 7.4 (Normalidad asintótica de estimadores eficientes) Bajo las condiciones anteriores y si \(T\) es un estimador eficiente de \(m(\theta)\) y \(m'(\theta) \neq 0\), entonces \[
\dfrac 1{\sqrt{\sigma^2_{\mathrm{CR}}}}\left[T-m(\theta)\right]\xrightarrow{d}N(0,1)
\]
donde \(\sigma^2_{\mathrm{CR}}\) es la varianza de la cota de Cramer-Rao.
NotaPrueba
Recuerde que \(\lambda'_n(X|\theta) = \sum_{i=1}^n\lambda^{\prime}(X_i|\theta)\). Como \(X\) es una muestra, \(\lambda^{\prime}(X_i|\theta)\) son i.i.d, y
El teorema anterior aplica cuando existe un estimador eficiente en muestras finitas. El siguiente resultado es más poderoso: el MLE siempre es asintóticamente normal y asintóticamente eficiente bajo condiciones de regularidad, aunque no sea eficiente en muestras finitas.
Teorema 7.5 (Normalidad asintótica del MLE) Recuerde que el MLE \(\hat \theta_n\) se obtiene al resolver la ecuación \(\lambda^{\prime}(x|\theta) = 0\). Si \(\lambda^{\prime\prime}(x|\theta)\) y \(\lambda'''(x|\theta)\) existen y las condiciones de regularidad son válidas. Entonces, la distribución asintótica de \(\hat\theta_n\) cumple que: \[
\left[nI(\theta)\right]^{1/2}(\hat\theta_n-\theta) \xrightarrow{d} N(0,1).
\] En particular, el MLE es asintóticamente eficiente: su varianza converge a la cota de Cramér-Rao cuando \(n\to\infty\).
Ejemplo 7.13 Sea \(X_1,\dots, X_n \sim N(0,\sigma^2)\), \(\sigma\) desconocida. \(\hat\sigma = \bigg[\dfrac 1n \sum_{i=1}^{n}\left(X_{i}-\bar{X}_{n}\right)^{2}\bigg]^{1/2}\) es MLE de \(\sigma\) y \(I(\sigma) = \dfrac 2{\sigma^2}\). Usando el teorema,
\[
\sqrt{\dfrac{2n}{\sigma^2}} (\hat{\sigma} - \sigma) \underset{n\to\infty}{\to} N\left(0,1\right).
\] O lo que es equivalente a \[
\hat{\sigma} \underset{n\to\infty}{\to}
N\left(\sigma,\dfrac{\sigma^2}{2n}\right).
\]
TipIdeas clave: comportamiento asintótico del MLE
Todo estimador eficiente (en muestras finitas) tiene distribución asintótica \(N(m(\theta),\, [m'(\theta)]^2/I_n(\theta))\).
El MLE \(\hat\theta_n\) es asintóticamente normal: \([nI(\theta)]^{1/2}(\hat\theta_n - \theta) \xrightarrow{d} N(0,1)\).
En consecuencia, el MLE es asintóticamente eficiente: su varianza converge a la cota de Cramér-Rao cuando \(n\to\infty\).
Para muestras finitas el MLE puede ser sesgado e ineficiente; estas propiedades son garantías asintóticas, no exactas.
Observación. El MLE es invariante bajo transformaciones biyectivas: si \(\hat\theta_n\) es el MLE de \(\theta\), entonces para cualquier función biyectiva \(g\), el MLE de \(g(\theta)\) es \(g(\hat\theta_n)\). Esta propiedad se usó implícitamente en el ejemplo de la Exponencial(\(\beta\)): como \(\hat\beta_n = 1/\bar{X}_n\) es el MLE de \(\beta\), el MLE de \(m(\beta) = 1/\beta\) es \(1/\hat\beta_n = \bar{X}_n\). Si \(g\) no es biyectiva, la propiedad no se garantiza en general.
7.7 Estimador MLE en el caso bayesiano
El resultado asintótico del MLE tiene una consecuencia directa en el mundo bayesiano: cuando \(n\) es grande, el prior pierde influencia y la posterior se concentra alrededor del MLE. Este resultado explica por qué frecuentistas y bayesianos llegan a conclusiones similares con muestras grandes.
NotaPropiedad general (posterior asintótica)
Si la distribución a priori de \(\theta\) es positiva y diferenciable en un intervalo, y se cumplen las condiciones de regularidad del MLE, entonces la distribución a posteriori de \(\theta\) dado \(X_1,\dots,X_n\) es aproximadamente: \[
\theta \mid X_1,\dots,X_n \;\underset{n\to\infty}{\approx}\; N\!\left(\hat\theta_n,\; \dfrac{1}{nI(\hat\theta_n)}\right),
\] donde \(\hat\theta_n\) es el MLE. La varianza posterior \(1/[nI(\hat\theta_n)]\) coincide con la cota de Cramér-Rao: el prior se “diluye” y la información proviene casi en su totalidad de los datos.
Ejemplo 7.14 Sea \(X_1,\dots,X_n \sim N(0,\sigma^2)\) con \(\sigma\) desconocida. El MLE es \(\hat\sigma_n = \sqrt{\frac{1}{n}\sum X_i^2}\) e \(I(\sigma) = 2/\sigma^2\) (ver sección anterior). Por la propiedad general, para cualquier prior positivo y diferenciable en \(\sigma > 0\): \[
\sigma \mid X_1,\dots,X_n \;\underset{n\to\infty}{\approx}\; N\!\left(\hat\sigma_n,\; \dfrac{\hat\sigma_n^2}{2n}\right).
\]
El siguiente código ilustra que la varianza posterior decrece a razón de \(1/n\):
for n in n_vals_bn: x = rng_bn.normal(0, sigma_true_bn, n) mle = np.sqrt(np.mean(x**2)) # MLE de sigma se_post = mle / np.sqrt(2* n) # DE asintótica: 1/sqrt(n·I(σ̂)), I(σ)=2/σ²print(f"{n:>6}{mle:>8.4f}{se_post:>14.4f}")
Con \(n\) grande, la posterior es aproximadamente \(N(\hat\theta_n,\; 1/[nI(\hat\theta_n)])\) independientemente del prior (siempre que sea positivo y diferenciable).
La varianza posterior \(1/[nI(\hat\theta_n)]\) coincide con la cota de Cramér-Rao: el MLE es asintóticamente óptimo también desde la perspectiva bayesiana.
Para \(n\) pequeño, el prior sí importa; la diferencia entre enfoques es más pronunciada cuanto menor es la muestra.
7.8 Resumen
Concepto
Definición / Fórmula
Observación clave
Estimador insesgado
\(\mathbb E[\delta(X)] = g(\theta)\)
Propiedad en esperanza; no garantiza precisión por muestra