9 Intervalos de confianza
En los capítulos anteriores aprendimos a encontrar un único valor \(T\) que estima \(\theta\). El problema es que ese valor tiene incertidumbre: si repitiéramos el experimento con otra muestra obtendríamos un \(T\) diferente. En lugar de reportar solo el punto, este capítulo desarrolla la idea de reportar un intervalo que captura esa incertidumbre de forma probabilística. La herramienta central es la cantidad pivotal: una función de los datos y el parámetro cuya distribución no depende del valor desconocido de \(\theta\), lo que permite construir intervalos con garantías exactas sobre la probabilidad de contener al parámetro.
9.1 Intervalos de confianza para la media de una distribución normal
Dado \(\theta\) un parámetro en \(\mathbb{R}\) hemos estudiado procedimientos para encontrar estadísticos \(T\in \mathbb R\) para estimarlo. La limitación que tenemos acá es que no sabemos qué tan aleatorio es \(T\). Entonces podemos sustituir este estadístico \(T\) con otros dos estadísticos \(T_1\) y \(T_2\) de modo que sepamos que
\[\begin{equation*} T_1 \leq \theta \leq T_2 \end{equation*}\]
9.2 Caso normal
El punto de partida más natural es el caso más común en la práctica: queremos estimar la media \(\mu\) de una distribución normal con varianza desconocida. Ya sabemos que \(\bar{X}_n\) es el estimador puntual; ahora construiremos el intervalo a partir del estadístico pivotal \(U = \sqrt{n}(\bar{X}_n-\mu)/s \sim t_{n-1}\).
En el caso normal, \(\bar{X}_n\) es un estimador puntual de \(\mu\). ¿Será posible encontrar un estimador para un intervalo?
Para efectos didácticos, primero defina \(U = \dfrac{\sqrt{n}(\bar{X}_n-\mu)}{s} \sim t_{n-1}\). Recuerde que \(s^2\) se define como la varianza muestral, cuya fórmula es \[ s^2 = \dfrac{1}{n-1} \sum_{i=1}^n (X_i - \bar{X}\_n)^2. \]
Ahora para \(c>0\), queremos encontrar la probabilidad que \(U\) esté en el intervalo \((-c,c)\). Para esto, usaremos la distribución de \(U\):
\[\begin{align*} \mathbb P[-c<U<c] & = \mathbb P \bigg[ -c<\dfrac{\sqrt{n}(\bar{X}_n-\mu)}{s} <c\bigg] \\ & = \mathbb P \bigg[-\dfrac{cs}{\sqrt n} < \bar{X}_n - \mu <\dfrac{cs}{\sqrt n}\bigg] \\ & = \mathbb P \bigg[ \bar{X}_n -\dfrac{cs}{\sqrt n} < \mu < \bar{X}_n + \dfrac{cs}{\sqrt n}\bigg] \end{align*}\]
El intervalo
\[\begin{equation*} T = \bigg[\bar{X}_n - \dfrac{c s}{\sqrt n},\bar{X}_n + \dfrac{c s}{\sqrt n}\bigg] \end{equation*}\]
es un intervalo aleatorio que “contiene” a \(\mu\). Tome \(\alpha \in (0,1)\) de modo que: \[ \mathbb P(\mu\in T) = 1-\alpha. \]
Para que se cumpla lo anterior, seleccione \(c\) tal que
\[\begin{align*} 1-\alpha = \mathbb P( \mu \in T) & = \mathbb{P}_{t_{n-1}}(U \leq c)- \mathbb{P}_{t_{n-1}}(U \leq -c) \\ & = F_{t_{n-1}}(c)-F_{t_{n-1}}(-c) \\ & = F_{t_{n-1}}(c) - [1-F_{t_{n-1}}(c)] \\ & = 2F_{t_{n-1}}(c) - 1 \end{align*}\]
Entonces despejando se obtiene que
\[\begin{align*} 1-\frac{\alpha}{2} & = F_{t_{n-1}}(c) \\ \implies c & = F_{t_{n-1}}^{-1}\left(1-\frac{\alpha}{2}\right). \end{align*}\]
Definición 9.1 Si \(X\) es una variable aleatoria continua con distribución \(F\) (monótona creciente), entonces \(x=F^{-1}(p)\) es el cuantil de orden \(p\) de \(F\) (\(p\)-cuantil).
Con esta notación, el intervalo de confianza para \(\mu\) al \(100(1-\alpha)\%\) queda:
\[\begin{equation*} \Bigg[\bar{X}_n - F_{t_{n-1}}^{-1}\!\left(1-\frac{\alpha}{2}\right)\frac{s}{\sqrt{n}},\; \bar{X}_n + F_{t_{n-1}}^{-1}\!\left(1-\frac{\alpha}{2}\right)\frac{s}{\sqrt{n}}\Bigg]. \end{equation*}\]
Definición 9.2 Sea \(X = (X_1,\dots,X_n)\) una muestra con parámetro \(\theta\). Sea \(g(\theta)\) una característica de la distribución que genera la muestra. Sea \(A < B\) dos estadísticos que cumplen (\(\forall \theta\)): \[ \mathbb P [A<g(\theta)<B]\geq 1-\alpha. \tag{9.1}\]
Al intervalo \((A,B)\) le llamamos intervalo de confianza al \(100 (1-\alpha)\%\). En el caso que Ecuación 9.1 tenga una igualdad, el intervalo es exacto.
Observación. En algunos textos se usa \(\gamma\) en lugar de \(1-\alpha\), donde \(\gamma\) es cercano a 1. En este caso, se dice que el intervalo es un intervalo de confianza al \(100\gamma \%\), y se escribe como \[\begin{equation*} \bigg[\bar{X}_n - F_{t_{n-1}}^{-1}\!\left(\frac{1+\gamma}{2} \right)\dfrac{s}{\sqrt{n}},\;\bar{X}_n + F_{t_{n-1}}^{-1}\!\left(\frac{1+\gamma}{2} \right)\dfrac{s}{\sqrt{n}}\bigg] \end{equation*}\]
Observación. Si observamos \(X\), calculamos \(A=a\), \(B=b\). Entonces \((a,b)\) es el valor observado de un intervalo de confianza.
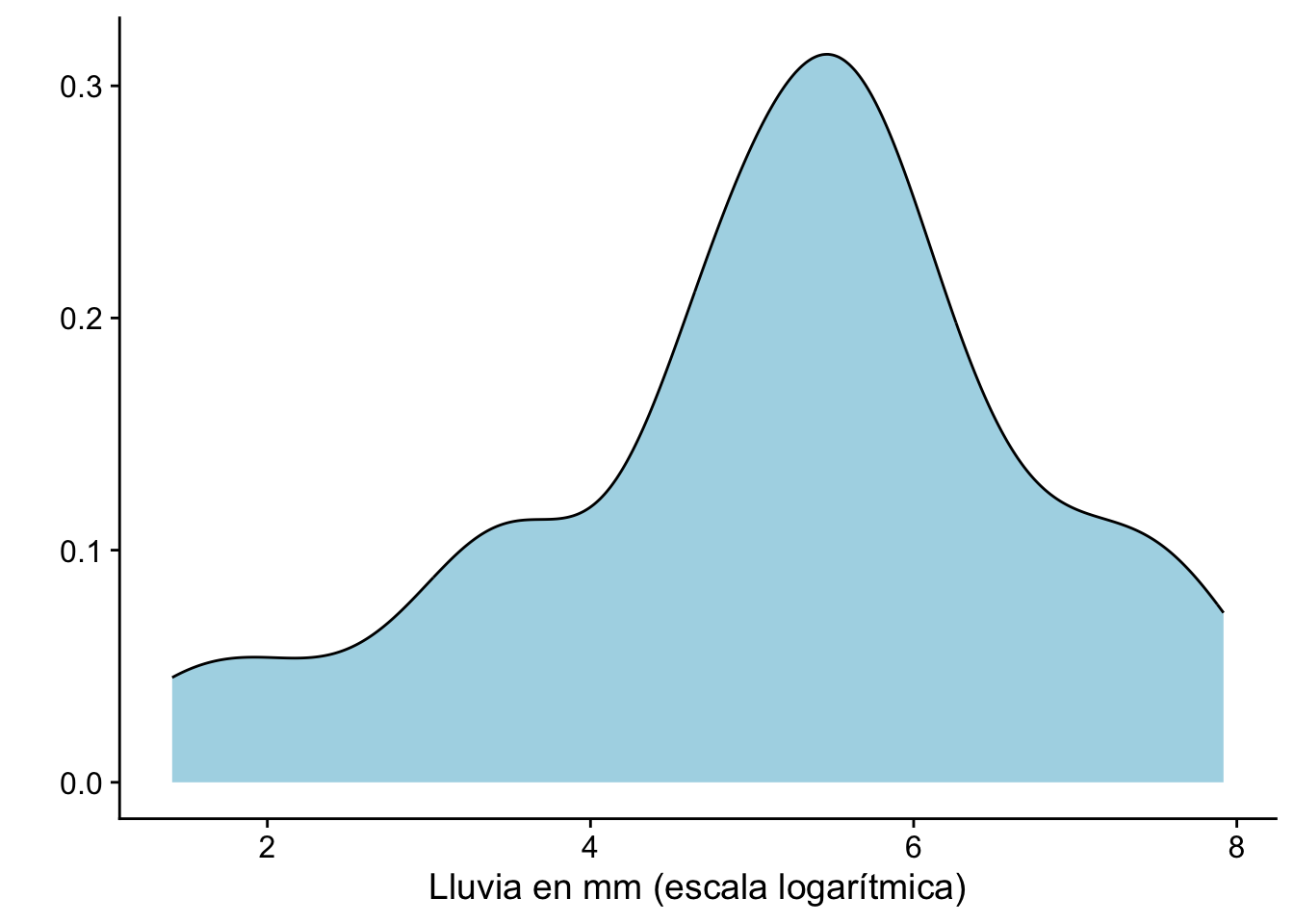
Ejemplo 9.1 Se realiza un experimento donde se inyectan nubes con sulfato de plata y de obtiene la cantidad de agua de lluvia. El experimento se hizo con \(n=26\) observaciones. Se desea hacer inferencia sobre \(\mu\), la cantidad de lluvia media (escala logarítmica). Los datos se pueden aproximadamente así
Para \(\alpha=0.05\), se calcula
\[ c=F^{-1}_{t_{25}}\left(1-\frac{\alpha}{2}\right) =F^{-1}_{t_{25}}(0.975) = 2.060 \]
Note que \(1-\frac{\alpha}{2}=\) \(0.975\) y \(n-1 = 26-1=25\). El valor final se obtiene de una tabla de valores de la \(t\)-student o de la expresión qt(p = 0.975, df = 25) = \(2.06\)
Warning in geom_point(aes(x = 2.06, y = 0.975), size = 2): All aesthetics have length 1, but the data has 7001 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.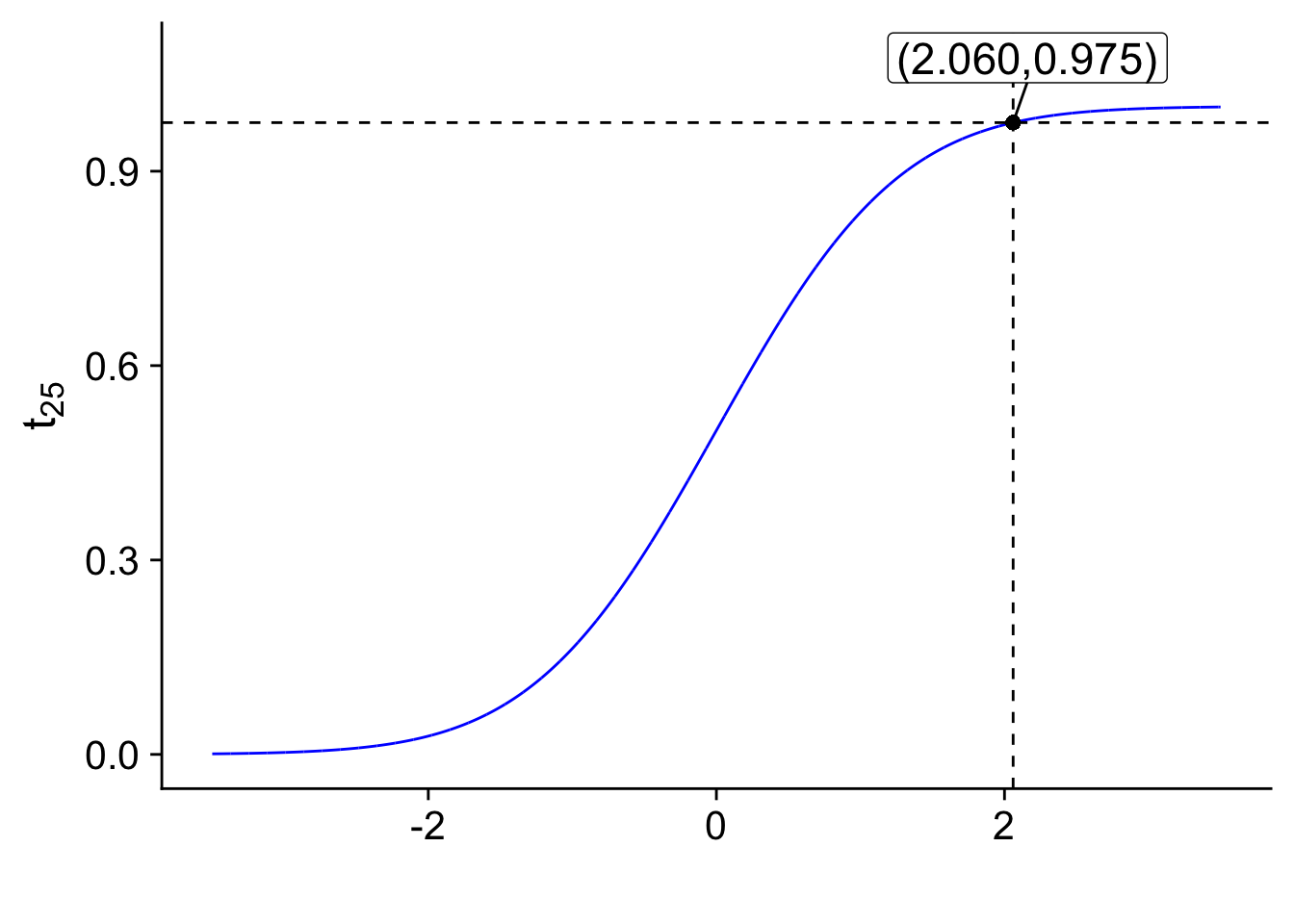
El intervalo de confianza para \(\mu\) al \(95\%\) es
\[\begin{align*} \bar{X}_n & \pm \frac{c}{\sqrt{n}} s \\ \bar{X}_n & \pm \frac{2.060}{\sqrt{26}}s \\ \bar{X}_n & \pm 0.404 s \end{align*}\]
Si \(\bar{X}_n = 5.134\) y \(s = 1.6\) el valor observado del intervalo de confianza al \(95\%\) para \(\mu\) corresponde a
\[\begin{equation*} [5.134 - 0.404\times 1.6,\; 5.134 + 0.404\times 1.6]= [4.49,\;5.78] \end{equation*}\]
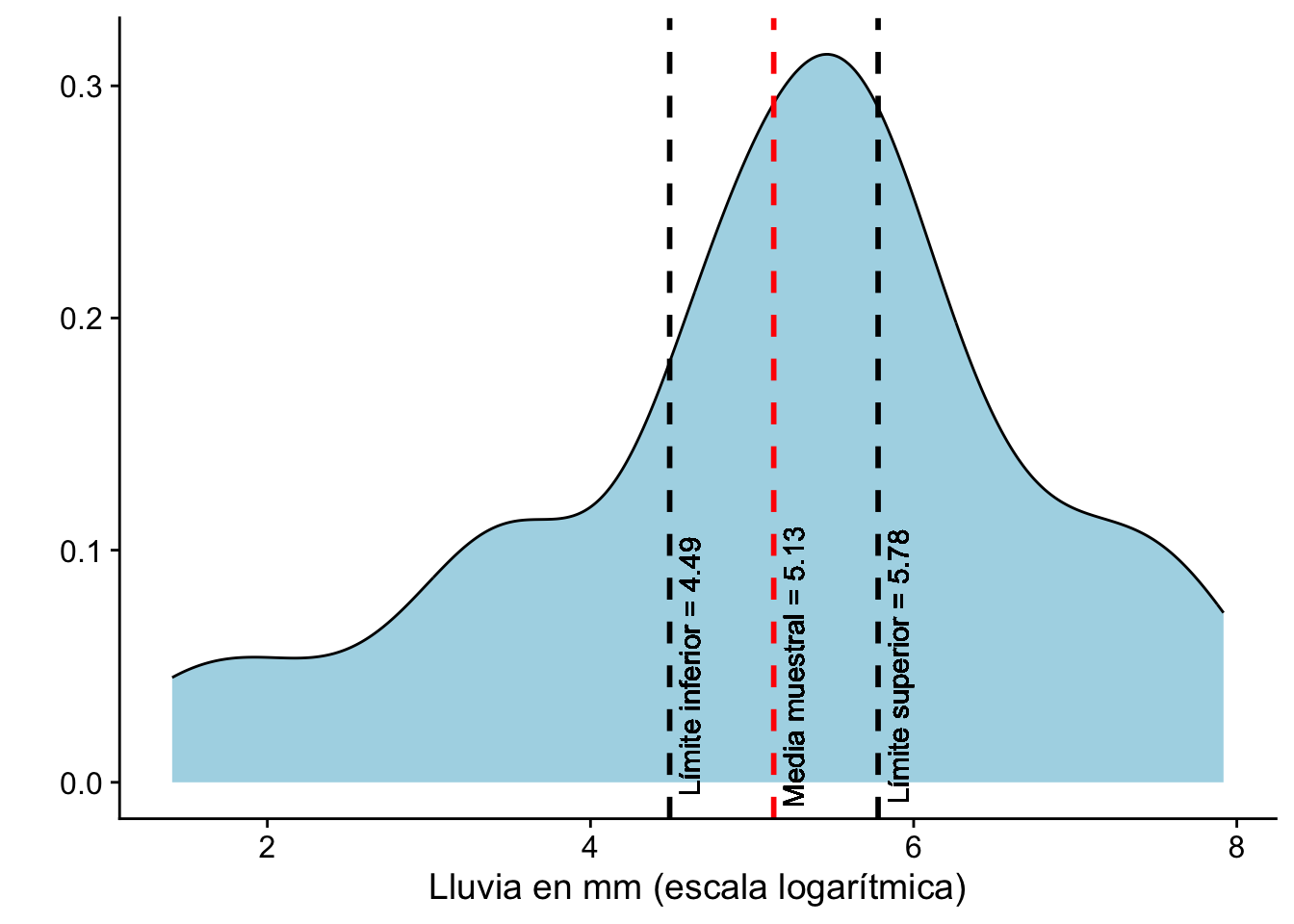
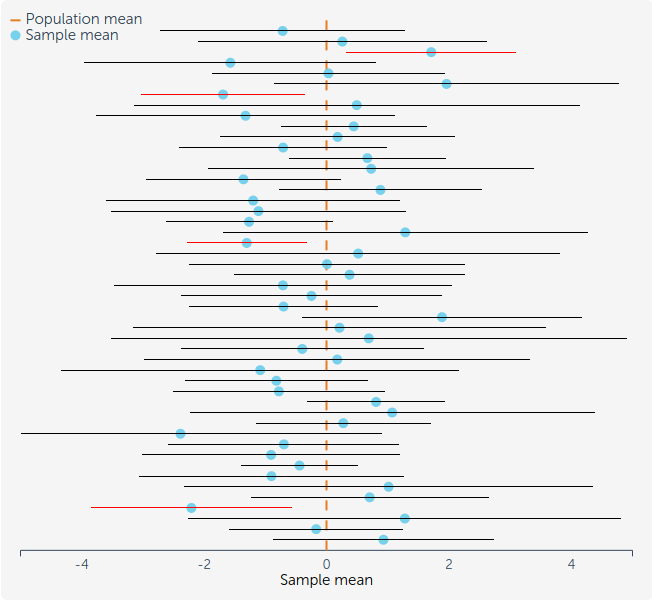
Observación (Interpretación correcta). Una vez observados los datos, el intervalo \([4.49,\,5.78]\) es un número fijo: o contiene a \(\mu\), o no. El \(95\%\) no es la probabilidad de que \(\mu\) esté en este intervalo específico, sino que el procedimiento que genera intervalos de esta forma produce intervalos que contienen al parámetro verdadero en el \(95\%\) de las muestras posibles.
La expresión \(\mathbb{P}(\mu\in T)=0.95\) en los pasos de derivación se refiere a la probabilidad antes de observar los datos, cuando \(T=[T_1,T_2]\) es aún aleatorio porque sus extremos dependen de \(\bar{X}_n\). Usualmente a \(\dfrac{c\,s}{\sqrt{n}}\) se le llama margen de error (MOE).
Observación (Interpretación gráfica). El proceso de construir un intervalo de confianza, quiere decir que si usted repitiera ese experimento muchas veces, el \(100(1-\alpha)\%\) (e.g, 95% o 99%) de la veces, el intervalo escogido tendría el parámetro real de la población \(\theta\).
TipIdeas clave — IC para la media normal
- El estadístico pivotal es \(U = \sqrt{n}(\bar{X}_n-\mu)/s \sim t_{n-1}\).
- El margen de error es \(\mathrm{MOE} = t_{n-1,\,1-\alpha/2}\cdot s/\sqrt{n}\); crece con \(s\) y decrece con \(n\).
- La distribución \(t\) (no la normal estándar) es necesaria porque \(\sigma^2\) es desconocida y se estima con \(s^2\).
- La cobertura \(1-\alpha\) es una propiedad del procedimiento, no del intervalo observado: una vez calculado, el intervalo o contiene a \(\mu\) o no.
9.3 Intervalos de Confianza Asimétricos
Los intervalos de confianza no siempre son simétricos en torno a un valor estimado. En ciertos contextos, puede ser útil considerar intervalos de confianza de un solo lado.
Dado un nivel de confianza \(1-\alpha\), supongamos que existen dos valores \(\gamma_1\) y \(\gamma_2\) con \(\gamma_2 -\gamma_1 = 1-\alpha\). Definamos el estadístico \(U\) como:
\[ U = \frac{\sqrt n}{s}(\bar{X}\_n-\mu) \]
Si \(T_{n-1}^{-1}(c)\) representa el cuantil de nivel \(c\) de la distribución \(t_{n-1}\), los límites del intervalo de confianza son:
\[ A = \bar{X}_n - T_{n-1}^{-1}(\gamma_2)\dfrac{s}{\sqrt{n}}, \qquad B = \bar{X}_n - T_{n-1}^{-1}(\gamma_1)\dfrac{s}{\sqrt{n}}. \]
Estos límites se obtienen despejando \(\mu\) de \(T_{n-1}^{-1}(\gamma_1) < U < T_{n-1}^{-1}(\gamma_2)\), lo que invierte el sentido de las desigualdades al multiplicar por \(-s/\sqrt{n}\). El intervalo \((A,B)\) tiene nivel \(100(1-\alpha)\%\) ya que:
\[ \mathbb{P}[\mu \in (A,B)] = \gamma_2-\gamma_1 = 1-\alpha. \]
9.3.1 Intervalos de confianza de una cola
En ciertos problemas solo interesa acotar el parámetro por uno de sus lados: por ejemplo, demostrar que la tasa de fallas de un componente no supera un umbral. Para eso se definen los intervalos abiertos.
Definición 9.3 En ciertas situaciones, puede ser útil considerar intervalos de confianza que no están acotados en uno de sus extremos.
Límite Inferior de Confianza: Si \(A\) es un estadístico que cumple: \[ \mathbb P [A<g(\theta)]\geq 1-\alpha \] Entonces, \(A\) es el límite inferior de confianza al \(100(1-\alpha)\%\). El intervalo \((A,\infty)\) es el intervalo de confianza inferior al \(100(1-\alpha)\%\).
Límite Superior de Confianza: De manera análoga, si \(B\) cumple: \[ \mathbb P [g(\theta)<B]\geq 1-\alpha \] El intervalo \((- \infty,B)\) es el intervalo de confianza superior para \(g(\theta)\) con nivel \(1-\alpha\). Si se cumple la igualdad, el intervalo es exacto.
Ejemplo 9.2 Consideremos una distribución normal. Queremos encontrar un valor \(B\) tal que \(\mathbb P(\mu<B) = 1-\alpha\). Sabemos que:
\[ F_{t_{n-1}}(c) = \mathbb P(U>-c) = \mathbb P \left(\dfrac{\sqrt n(\mu - \bar{X}_n)}{ s}<c\right) \]
De aquí, podemos expresar \(1-\alpha\) como:
\[ 1-\alpha = \mathbb P\left(\mu < \bar{X}_n + \dfrac{ s}{\sqrt n}c\right) \]
Para encontrar \(c\), igualamos la expresión de la línea anterior con \(1-\alpha\):
\[ F_{t_{n-1}}(c) = 1-\alpha \implies c = F_{t_{n-1}}^{-1}(1-\alpha). \]
Finalmente, el límite superior \(B\) del intervalo de confianza es:
\[ B = \bar{X}_{n} + \frac{s_{n}}{\sqrt{n}}F^{-1}_{t_{n-1}}(1-\alpha) \]
Ejemplo 9.3 Ahora si retomamos el Ejemplo 9.1, pero ahora queremos el 90% intervalo de confianza para \(\mu\). Entonces \(T_{25}^{-1}(0.9)\) se calcula con el comando qt(p = 0.90, df = 25) = \(1.316\). El intervalo de confianza quedaría
\[\begin{equation*} a = 5.1314 - 1.316 \frac{1.600}{\sqrt{26}} = 5.1314 - 0.413 = 4.719. \end{equation*}\]
TipIdeas clave — IC asimétricos y de una cola
- Un IC asimétrico resulta de elegir \(\gamma_1 \neq \alpha/2\); en el caso simétrico se tiene \(\gamma_1=\alpha/2\), \(\gamma_2=1-\alpha/2\).
- La fórmula general con la distribución \(t\) es \(A = \bar{X}_n - T_{n-1}^{-1}(\gamma_2)\,s/\sqrt{n}\), \(B = \bar{X}_n - T_{n-1}^{-1}(\gamma_1)\,s/\sqrt{n}\).
- El IC de una cola se usa cuando solo interesa acotar el parámetro por arriba (o por abajo), p.ej., demostrar que una tasa de falla no supera un umbral.
9.4 Intervalos de confianza en otros casos
La distribución \(t_{n-1}\) funcionó como pivotal en el caso normal porque la distribución de \(U = \sqrt{n}(\bar{X}_n-\mu)/s\) es completamente conocida, sin depender de ningún parámetro desconocido. Para otros modelos (exponencial, Poisson, varianza normal) debemos encontrar un pivotal específico a cada distribución. La receta es siempre la misma:
Importante
Recuerden lo siguiente: para calcular un intervalo de confianza ustedes solo necesitan saber el estadístico del parámetro \(\theta\) y la distribución de ese estadístico. Con esa distribución calculan el cuantil de tamaño \(1-\alpha\) de modo que la probabilidad de que el parámetro \(\theta\) esté en el intervalo sea \(1-\alpha\).
Ejemplo 9.4 Retomemos el ejemplo de los componentes electrónicos que fallan. Recordemos que el tiempo de vida de estos componentes sigue una distribución exponencial con parámetro \(\theta\). En el experimento, se observaron 3 aparatos, es decir, \(n=3\) y \(X_i \sim \text{Exp}(\theta)\). A partir de nuestros datos, determinamos que si \(T = \sum_{i=1}^3X_i\), entonces \(\theta T \sim \Gamma(3,1)\).
Queremos construir un intervalo de confianza superior para \(\theta\) al \(100(1-\alpha)\%\) (exacto). Esto se traduce en encontrar un valor \(B\) tal que \(\mathbb P[\theta<B] = 1-\alpha\).
Si \(G\) representa la función de distribución acumulada de la distribución gamma, entonces:
\[ 1-\alpha = \mathbb{P}[\theta T<G^{-1}(1-\alpha)] = \mathbb{P}\left[\theta<\frac{G^{-1}(1-\alpha)}{T}\right] \]
Por lo tanto, el límite superior del intervalo de confianza es:
\[ B = \frac{G^{-1}(1-\alpha)}{T} \]
Código
# Establecemos una semilla para reproducibilidad
set.seed(123)
# Definimos el valor de theta
theta <- 2
# Generamos 3 valores aleatorios de una distribución exponencial
(X <- rexp(3, rate = theta))[1] 0.4217286 0.2883051 0.6645274Código
# Calculamos la suma de estos valores — estadístico suficiente
(T <- sum(X))[1] 1.374561Código
# Cuantil 0.95 de Gamma(3, 1): pivotal theta*T ~ Gamma(3,1)
(G_inv <- qgamma(p = 0.95, shape = 3, rate = 1))[1] 6.295794Código
# Límite superior del IC: B = G^{-1}(0.95) / T
c(0, G_inv / T)[1] 0.000000 4.580221Código
import numpy as np
from scipy.stats import gamma as gamma_dist
rng = np.random.default_rng(123)
theta = 2.0
# Generamos 3 observaciones de Exp(theta)
X = rng.exponential(scale=1/theta, size=3)
print(f"X = {X}")X = [0.29848625 0.05851553 0.12589735]Código
# Estadístico suficiente T = sum(X_i)
T = X.sum()
print(f"T = {T:.6f}")T = 0.482899Código
# Cuantil 0.95 de Gamma(3, 1): pivotal theta*T ~ Gamma(3, 1)
# scipy: gamma(a=shape, scale=1/rate) → scale=1 cuando rate=1
G_inv = gamma_dist.ppf(0.95, a=3, scale=1)
print(f"G_inv = {G_inv:.6f}")G_inv = 6.295794Código
# Límite superior del IC: B = G^{-1}(0.95) / T
ic = (0, G_inv / T)
print(f"IC superior 95%: (0, {ic[1]:.4f})")IC superior 95%: (0, 13.0375)El siguiente concepto encierra la esencia de la construcción de los intervalos de confianza. Básicamente, trataremos de transformar nuestro estimador a una cantidad que no dependa del parámetro \(\theta\) o una cantidad pivotal. Para esto primero debemos definir este término.
Definición 9.4 Dada una muestra \(X = (X_1,\dots,X_n)\) proveniente de una distribución \(F_\theta\), si tenemos una variable aleatoria \(V(X,\theta)\) cuya distribución no depende de \(\theta\), entonces decimos que \(V\) es una cantidad pivotal.
En mucho casos el truco para construir intervalos de confianza, es invertir la cantidad pivotal. La idea es encontrar una función \(r(v,x)\) que satisface:
\[ r(V(X,\theta), X) = g(\theta) \]
donde \(g\) es una función arbitraria.
Si esta función existe, entonces es posible encontrar un intervalo de confianza para \(\theta\) al \(100(1-\alpha)\%\) de la siguiente manera:
NotaIntervalos asimétricos
Si la función \(r(v,x)\) es creciente en \(v\) para cada \(x\) y tenemos que \(\gamma_2 > \gamma_1\) con \(\gamma_2-\gamma_1=1-\alpha\), entonces los límites del intervalo de confianza son:
\[\begin{align*} A & = r(G^{-1}(\gamma_1),X) \\ B & = r(G^{-1}(\gamma_2),X) \end{align*}\]
Si \(r(v,x)\) es decreciente, simplemente intercambiamos \(A\) y \(B\).
Ejemplo 9.5 Retomando el ejemplo anterior donde \(V(X,\theta) = \theta T\), podemos elegir:
\[ r(v,x) = \frac{v}{t} \]
donde \(t = \sum_{i=1}^{3} X_i\). Así, obtenemos:
\[ r(V(X,\theta),X) = \frac{V(X,\theta)}{T} = \theta = g(\theta). \]
Ejemplo 9.6 Suponga que \(X_1,\dots, X_n \stackrel{i.i.d}{\sim} N(\mu,\sigma^2)\). Encuentre A, B tales que \(\mathbb P[A<\sigma^2<B] = 1-\alpha\).
Se sabe que \[ \dfrac{n\hat\sigma^2}{\sigma^2}\sim \chi^2_{n-1}. \]
Tome \(V(X,\sigma^2) = \dfrac{n\hat\sigma^2}{\sigma^2}\). Entonces
\[ 1-\alpha = \mathbb P[\chi^2_{n-1,\gamma_1}<V(X,\sigma^2)<\chi^2_{n-1,\gamma_2}] \]
Ahora, defina la función \[ r(v,X) =\frac{\sum_{i=1}^{n}{(X_i -\bar{X}_n)}^2}{v} = \dfrac{n\hat{\sigma}^2}{v}. \]
Esta función cumple que
\[ r(V(X,\sigma^2),X) = \dfrac{n\hat{\sigma}^2}{\dfrac{n\hat{\sigma}^2}{\sigma^2}} = \sigma^2. \]
Entonces las siguientes igualdades son verdaderas
\[\begin{align*} & = \mathbb{P}\left[\chi^2_{n-1,\gamma_1}<V(X,\sigma^2)<\chi^2_{n-1,\gamma_2}\right] \\ & =\mathbb{P}\left[\chi^2_{n-1,\gamma_1}<\frac{n\hat{\sigma}^2}{\sigma^2}<\chi^2_{n-1,\gamma_2}\right] \\ & = \mathbb{P}\left[ r(\chi^2_{n-1,\gamma_2},X)<r\left(\frac{n\hat{\sigma}^2}{\sigma^2},X\right)<r(\chi^2_{n-1,\gamma_1},X)\right] \\ &=\mathbb P \left[ \underbrace{\dfrac{\sum{(X_i -\bar{X}_n)}^2}{\chi^2_{n-1,\gamma_2}}} _{A} <\sigma^2<\underbrace{\dfrac{\sum(X_i -\bar{X}_n) ^2}{\chi^2_{n-1,\gamma_1}}}_B\right] \\ &= 1-\alpha \end{align*}\]
Note como se tuvieron que invertir los extremos en \(\gamma_1\) y \(\gamma_2\). Esto es debido a que la función \(r\) es decreciente en \(v\). Siempre el valor más pequeño de \(r(v,x)\) debe ir a la izquiera y el más grande a la derecha.
Por lo tanto, el intervalo de confianza para \(\sigma^2\) al \(100(1-\alpha)\%\) es
\[ \Bigg[ \dfrac{\sum(X_i -\bar{X}_n) ^2}{\chi^2_{n-1,\gamma_2}}, \dfrac{\sum(X_i -\bar{X}_n) ^2}{\chi^2_{n-1,\gamma_1}}\Bigg]. \]
Por ejemplo, si implementamos esto en R, tendríamos algo como lo siguiente:
Código
set.seed(123)
X <- rnorm(n = 1000, 0, 2)
gamma1 <- 0.025
gamma2 <- 0.975
gamma2 - gamma1[1] 0.95Código
# Cuantiles de chi^2_{n-1}: pivotal n*sigma_hat^2/sigma^2 ~ chi^2_{999}
(chi2_gamma1 <- qchisq(p = gamma1, df = 1000 - 1))[1] 913.301Código
(chi2_gamma2 <- qchisq(p = gamma2, df = 1000 - 1))[1] 1088.487Código
# n * sigma_hat^2 = sum((Xi - Xbar)^2)
(diferencias <- sum((X - mean(X))^2))[1] 3929.902Finalmente el intervalo es
Código
# r(v, X) = sum(Xi-Xbar)^2 / v es decreciente → cuantiles se invierten
c(diferencias / chi2_gamma2, diferencias / chi2_gamma1)[1] 3.610426 4.302965Código
import numpy as np
from scipy.stats import chi2
rng2 = np.random.default_rng(123)
X = rng2.normal(0, 2, size=1000)
n = len(X)
gamma1, gamma2 = 0.025, 0.975
# Cuantiles de chi^2_{n-1}: pivotal n*sigma_hat^2/sigma^2 ~ chi^2_{n-1}
chi2_g1 = chi2.ppf(gamma1, df=n-1)
chi2_g2 = chi2.ppf(gamma2, df=n-1)
diferencias = np.sum((X - X.mean())**2) # n * sigma_hat^2
print(f"chi2_gamma1 = {chi2_g1:.4f}")chi2_gamma1 = 913.3010Código
print(f"chi2_gamma2 = {chi2_g2:.4f}")chi2_gamma2 = 1088.4871Código
print(f"sum(Xi-Xbar)^2 = {diferencias:.4f}")sum(Xi-Xbar)^2 = 4036.9238Código
# r(v, X) decreciente → cuantiles invertidos: A usa v_gamma2, B usa v_gamma1
ic = (diferencias / chi2_g2, diferencias / chi2_g1)
print(f"IC sigma^2 al 95%: [{ic[0]:.4f}, {ic[1]:.4f}]")IC sigma^2 al 95%: [3.7087, 4.4201]
Precaución
Las cantidades pivotales no siempre existen. Esto ocurre principalmente con las distribuciones discretas.
TipIdeas clave — Cantidad pivotal
- Un pivotal \(V(X,\theta)\) tiene distribución libre de \(\theta\): eso permite obtener cuantiles exactos sin conocer \(\theta\).
- La inversión de \(r(v,X)=g(\theta)\) puede requerir intercambiar los extremos del intervalo si \(r\) es decreciente en \(v\).
- Las cantidades pivotales no siempre existen, especialmente para distribuciones discretas: en ese caso se recurre a aproximaciones asintóticas via el Método Delta.
9.5 Transformaciones estabilizadoras de la varianza
9.5.1 Método Delta
El Método Delta es una herramienta poderosa en estadística que nos permite entender el comportamiento asintótico de transformaciones de estimadores consistentes y asintóticamente normales. Específicamente, nos ayuda a determinar cómo se distribuye una función de un estimador cuando el tamaño de la muestra tiende al infinito.
La pregunta clave es: ¿Cuál es el comportamiento de la distribución de \(\hat\theta\) cuando la muestra es grande?
Recordemos que si tenemos una muestra \(X_1,\dots, X_n\) que sigue una distribución normal \(N(\mu,\sigma^2)\) con \(\sigma^2\) conocida, entonces el estimador de máxima verosimilitud (MLE) de \(\mu\) es \(\hat\mu = \bar{X}_n\). Además, por el Teorema del Límite Central, sabemos que:
\[\begin{equation*} \frac{\bar{X}_n-\theta}{\frac{\sigma}{\sqrt{n}}} = \frac{\sqrt{n}(\bar{X}_n-\theta)}{\sigma} \xrightarrow{d} N(0,1) \end{equation*}\]
con
\[\begin{equation*} \mathrm{Var}(\bar{X}_n) = \frac{1}{n^2}\sum_{i=1}^n \mathrm{Var}(X_i) = \frac{\sigma^2}{n} \end{equation*}\]
Esto en general nos sugiera que si normalizamos un estadístico con su media y varianza, entonces la distribución de la normal estándar es una buena aproximación.
Ahora, el Método Delta dice que si \(Y_n\) es un estimador tal que \(\sqrt{n}(Y_n-\theta)/\sigma \xrightarrow{d} N(0,1)\), y \(g\) es una función diferenciable con \(g'(\theta)\neq 0\), entonces
\[\begin{equation*} \frac{\sqrt{n}}{\sigma\, g'(\theta)}\bigl[g(Y_n)-g(\theta)\bigr]\xrightarrow{d}N(0,1). \end{equation*}\]
En particular, si \(Y_n = \bar{X}_n\) con \(\mathrm{Var}(X_i) = \sigma^2\), este resultado permite derivar la distribución asintótica de cualquier función suave del estimador.
Ejemplo 9.7 Consideremos el ejemplo de una muestra \(X_1,X_2,\dots\) i.i.d. de variables exponenciales con densidad \(f(x\mid\theta) = \frac{1}{\theta} e^{-\frac{x}{\theta}}\), \(x>0\). Entonces \(\mathbb{E}(X)=\theta\) y \(\mathrm{Var}(X)=\theta^2\). Se puede probar que el MLE \(\theta\) es \(\hat\theta = \bar{X}_n\) y que \(\mathrm{Var}(\bar{X}_n) = \frac{\theta^2}{n}\). Por lo tanto, el MLE es consistente. De acuerdo al Teorema del Límite Central, tenemos que:
\[\begin{equation*} \frac{\bar{X}_n-\theta}{\frac{\theta}{\sqrt{n}}} = \frac{\sqrt{n}(\bar{X}_n-\theta)}{\theta} \xrightarrow{d} N(0,1) \end{equation*}\]
o lo que es equivalente que
\[\begin{equation*} \bar{X}_n \xrightarrow{d} N\left(\theta,\frac{\theta^2}{n}\right) \end{equation*}\]
Si definimos \(g(\theta) = \dfrac{1}{\theta}\) entonces \(g^{\prime}(\theta) = -\dfrac{1}{\theta^2}\). Por lo tanto, el MLE de \(\dfrac{1}{\theta}\) es \(\dfrac{1}{\bar{X}_n}\). Estamos interesados en la distribución de \(\dfrac{1}{\bar{X}_n}\) cuando \(n\to\infty\). Por el Método Delta, tenemos que:
\[\begin{align*} \frac{\sqrt{n}}{\theta g^{\prime}(\theta)}[g(\bar{X}_n)-g(\theta)] & = \frac{\sqrt{n}}{\theta \frac{1}{\theta^2}}\left[\frac{1}{\bar{X}_n}-\frac{1}{\theta}\right] \\ & = \sqrt{n}\theta\left[\frac{1}{\bar{X}_n}-\frac{1}{\theta}\right] \xrightarrow{d} N(0,1) \end{align*}\]
En otras palabras
\[\begin{equation*} \frac{1}{\bar{X}_n} \xrightarrow{d} N\left(\frac{1}{\theta},\frac{1}{n\theta^2}\right). \end{equation*}\]
9.5.2 Aplicación del Método Delta para construir intervalos de confianza
Comencemos con este ejemplo y noten que en un punto no podremos avanzar en el desarrollo.
Ejemplo 9.8 Suponga que \(X_1,\dots, X_n\sim \text{Poisson}(\theta)\). Por propiedades del la Poisson, sabemos que \(\mu =\sigma^2 = \theta\). Suponga que se tiene suficientes datos para aproximar por una normal, entonces por el teorema del límite central, \[ \sqrt n\dfrac{\bar{X}_n-\theta}{\sqrt{\theta}}\xrightarrow[]{d}N(0,1). \]
Entonces
\[\begin{align*} \mathbb P[|\bar{X}_n-\theta|<c] & = \mathbb P\bigg[\dfrac{\sqrt n|\bar{X}_n-\theta|}{\sqrt \theta}<\dfrac{c\sqrt n}{\sqrt \theta}\bigg] \\ & \approx 2\Phi\left(\dfrac{c\sqrt n}{\sqrt \theta}\right)-1. \end{align*}\]
Como consecuencia
\[\begin{equation*} \mathbb P\bigg[\bar{X}_n-\dfrac{c\sqrt \theta}{\sqrt n}<\theta<\bar{X}_n+\dfrac{c\sqrt \theta}{\sqrt n}\bigg]\approx 2\Phi\left(\dfrac{c\sqrt n}{\sqrt \theta}\right)-1. \end{equation*}\]
El problema acá es que no podemos avanzar más, pues no conocemos \(\theta\) y la varianza depende de este.
Código
set.seed(42)
x_bar <- data.frame(n = numeric(), Z = numeric())
idx <- rep(x = c(10, 2000), times = 1000)
for (k in seq_along(idx)) {
muestra <- rpois(n = idx[k], lambda = 5)
# estadístico estandarizado: sqrt(n)*(Xbar - theta)/sqrt(theta)
x_bar[k, "Z"] <- sqrt(idx[k]) * (mean(muestra) - 5) / sqrt(5)
x_bar[k, "n"] <- idx[k]
}
ggplot(x_bar) +
geom_histogram(
mapping = aes(x = Z, y = after_stat(density)),
bins = 30,
color = "white"
) +
stat_function(
fun = dnorm,
args = list(mean = 0, sd = 1),
color = "red"
) +
facet_wrap(. ~ n, scales = "free") +
cowplot::theme_cowplot()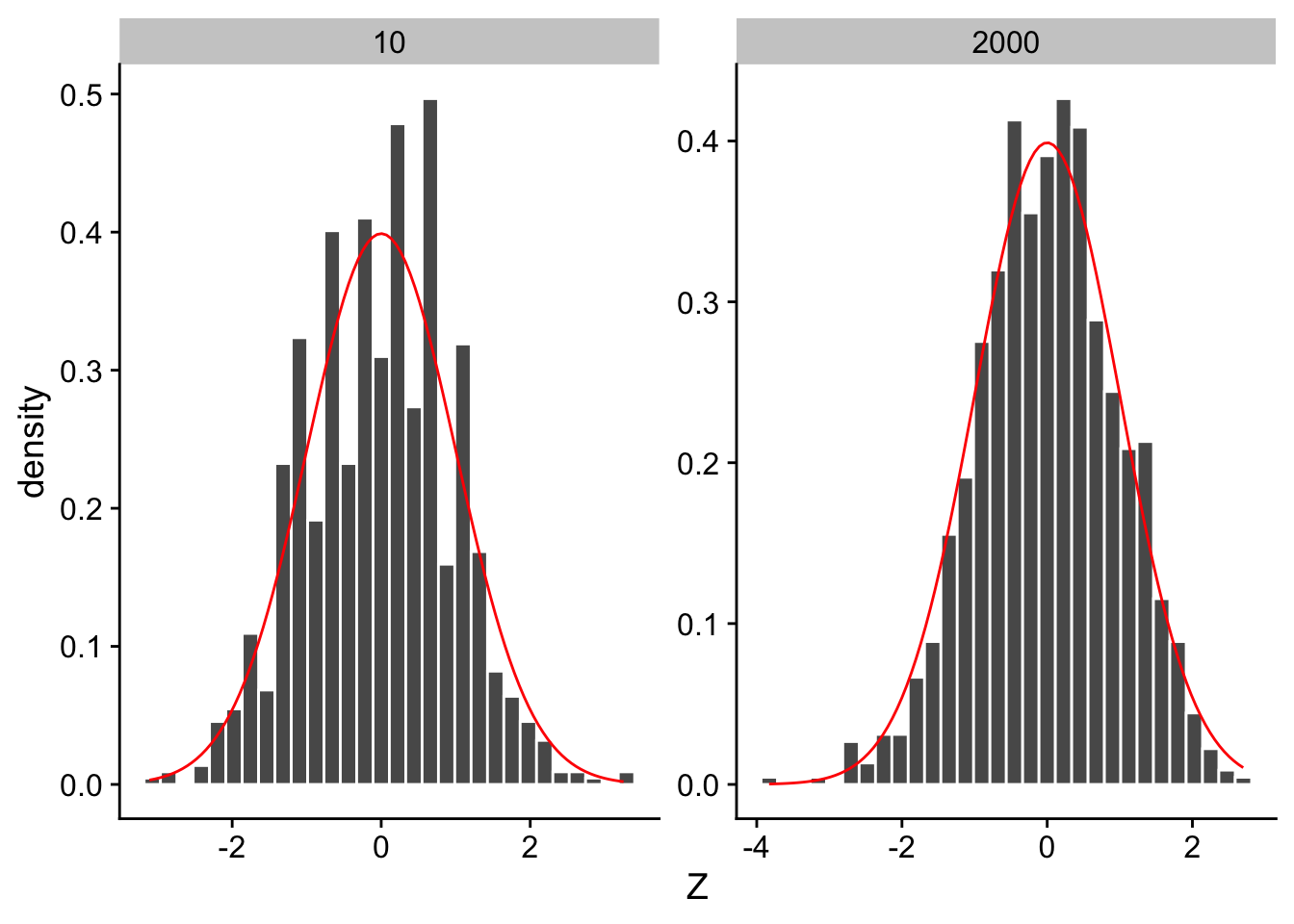
Código
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
rng3 = np.random.default_rng(42)
resultados = {"n": [], "Z": []}
for _ in range(1000):
for n_val in [10, 2000]:
muestra = rng3.poisson(lam=5, size=n_val)
# estadístico estandarizado: sqrt(n)*(Xbar - theta)/sqrt(theta)
Z = np.sqrt(n_val) * (muestra.mean() - 5) / np.sqrt(5)
resultados["n"].append(n_val)
resultados["Z"].append(Z)
z_grid = np.linspace(-4, 4, 200)
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
for ax, n_val in zip(axes, [10, 2000]):
datos = [z for z, n in zip(resultados["Z"], resultados["n"]) if n == n_val]
ax.hist(datos, bins=30, density=True, color="steelblue", edgecolor="white")
ax.plot(z_grid, norm.pdf(z_grid), color="red", linewidth=2)
ax.set_title(f"n = {n_val}")
ax.set_xlabel("Z")(array([0.00432923, 0.00432923, 0.00432923, 0.00865845, 0.04329225,
0.04329225, 0.04329225, 0.16451056, 0.06060915, 0.26408274,
0.16018133, 0.34200879, 0.5844454 , 0.19481513, 0.45889787,
0.44591019, 0.22511971, 0.41993484, 0.28139964, 0.11255985,
0.19048591, 0.05627993, 0.08225528, 0.06493838, 0.02164613,
0.02164613, 0.00865845, 0. , 0.01298768, 0.00432923]), array([-3.39411255, -3.16312433, -2.93213612, -2.7011479 , -2.47015969,
-2.23917147, -2.00818326, -1.77719504, -1.54620683, -1.31521861,
-1.0842304 , -0.85324218, -0.62225397, -0.39126575, -0.16027754,
0.07071068, 0.30169889, 0.53268711, 0.76367532, 0.99466354,
1.22565175, 1.45663997, 1.68762818, 1.9186164 , 2.14960461,
2.38059283, 2.61158105, 2.84256926, 3.07355748, 3.30454569,
3.53553391]), <BarContainer object of 30 artists>)
[<matplotlib.lines.Line2D object at 0x143e91490>]
Text(0.5, 1.0, 'n = 10')
Text(0.5, 0, 'Z')
(array([0.00445765, 0. , 0.00445765, 0.00445765, 0.02228826,
0.02228826, 0.04457652, 0.07132244, 0.14710253, 0.13818722,
0.23179792, 0.27637444, 0.27637444, 0.34323923, 0.37444279,
0.36998514, 0.46359584, 0.37890045, 0.36998514, 0.25408618,
0.27637444, 0.14710253, 0.08915305, 0.04903418, 0.03566122,
0.01337296, 0.03120357, 0. , 0.0089153 , 0.0089153 ]), array([-3.48 , -3.25566667, -3.03133333, -2.807 , -2.58266667,
-2.35833333, -2.134 , -1.90966667, -1.68533333, -1.461 ,
-1.23666667, -1.01233333, -0.788 , -0.56366667, -0.33933333,
-0.115 , 0.10933333, 0.33366667, 0.558 , 0.78233333,
1.00666667, 1.231 , 1.45533333, 1.67966667, 1.904 ,
2.12833333, 2.35266667, 2.577 , 2.80133333, 3.02566667,
3.25 ]), <BarContainer object of 30 artists>)
[<matplotlib.lines.Line2D object at 0x143f0ddc0>]
Text(0.5, 1.0, 'n = 2000')
Text(0.5, 0, 'Z')Código
plt.tight_layout()
plt.show()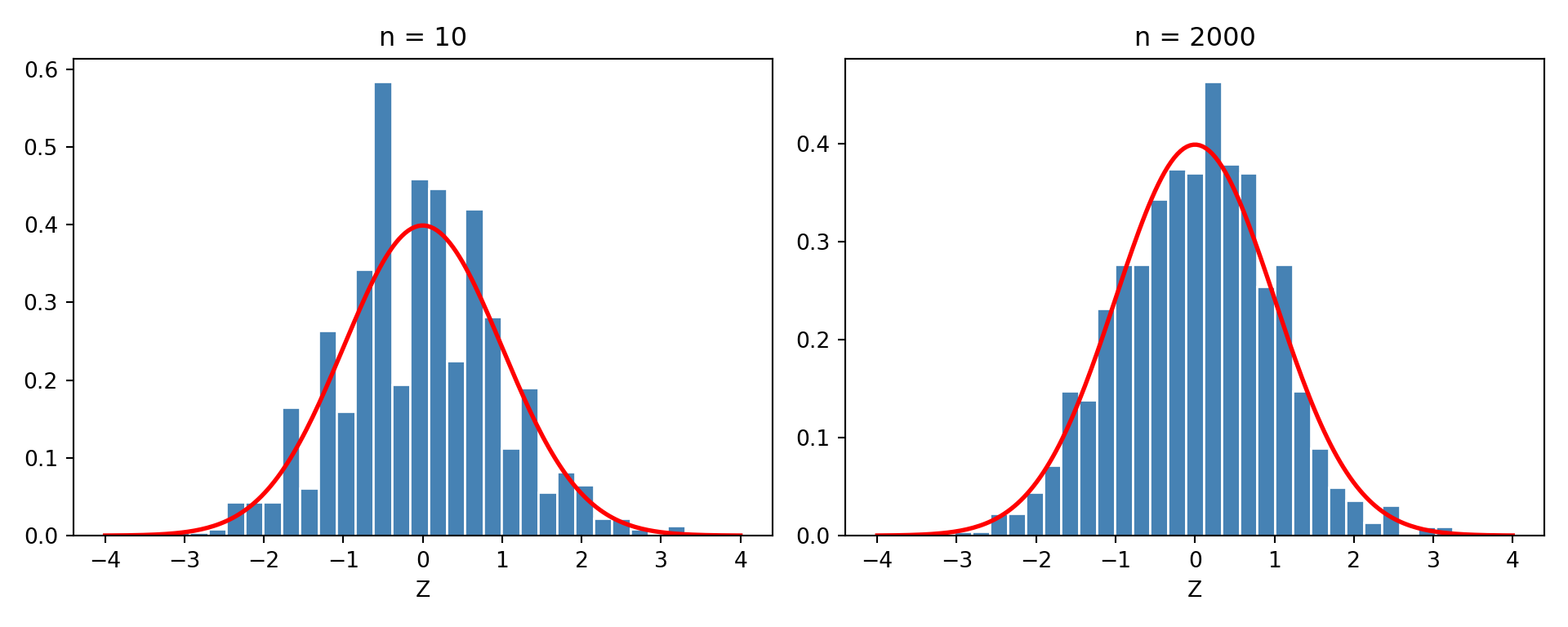
Observación. En este caso recuerden que \(\bar{X}_n\) es una variable aleatoria. Lo que dice el teorema del límite central es que conforme \(n\) es grande, la distribución de \(\bar{X}_n\) (centrada y escalada apropiadamente) converge a una normal estándar.
NotaIdea clave del Método Delta aplicada aquí
El estadístico \(\sqrt{n}(\bar{X}_n-\theta)/\sqrt{\theta}\) converge a \(N(0,1)\), pero la varianza depende del parámetro desconocido \(\theta\): no es pivotal. El Método Delta sugiere buscar una transformación \(g\) tal que la varianza de \(g(\bar{X}_n)\) sea constante en \(\theta\). Si se logra que \(g'(\mu)\cdot\sigma(\mu) = 1\), entonces \(\sqrt{n}[g(\bar{X}_n)-g(\theta)] \to N(0,1)\) sin depender de \(\theta\).
Note que en el caso anterior se necesitaría saber explícitamente el valor desconocido de \(\theta\) para hacer el ejercicio.
Por el método Delta, la varianza “aproximada” de \(g(\bar{X}_n)\) es \[ \left( \dfrac{g'(\mu)}{a_n}\right)^2 =\left( \dfrac{g'(\mu)\sigma}{\sqrt n}\right)^2 = \dfrac{g'(\mu)^2\sigma^2(\mu)}{n}. \] Si se desea que la varianza sea constante con respecto a \(\mu\),
\[\begin{align*} g'(u)^2\sigma^2(\mu) & = 1 \\ \implies g'(\mu) & = \dfrac{1}{\sigma(\mu)} \quad (\sigma(\mu)>0) \\ \implies g(\mu) & = \int_{a}^{\mu} \dfrac{dx}{\sigma(x)}dx \end{align*}\]
donde \(a\) es una constante arbitraria que hace la integral finita (y fácil de calcular).
Ejemplo 9.9 Del ejemplo anterior (Poisson), recuerde que \(\sigma ^{2} = \theta = \mu\), entonces se podría tomar que \(\sigma(\mu) = \sqrt{\mu}\) y por lo tanto definimos
\[ g(\mu) = \int_{0}^\mu\dfrac{dx}{\sqrt x} = 2\sqrt \mu \]
Por el método Delta, \[ 2\bar{X}_n^{\frac12} \underset{n \text{ grande}}{\sim} N\left(2\theta^{\frac 12},\dfrac1n\right) \]
De esta manera
\[ \mathbb P[|2\bar{X}_n^{\frac12}-2\theta^{\frac12}|<c] =\mathbb P\Bigg[\dfrac{|2\bar{X}_n^{\frac12}-2\theta^{\frac12}|}{\sqrt{1/n}}<\sqrt nc\Bigg] \approx 2\Phi(\sqrt nc)-1 \]
Desarrollando, \[ \mathbb P[-c+2\bar{X}_n^{\frac12}<2\theta^{\frac 12}<c+2\bar{X}_n^{\frac12}]\approx 2\Phi(\sqrt nc)-1 \]
Se despeja \(c\) tal que \[ \Phi(\sqrt n c) = 1-\frac{\alpha}{2}\implies c = \dfrac 1{\sqrt n} z_{1-\frac{\alpha}{2}}. \]
El intervalo para \(2\theta^{\frac 12}\) es \[ \bigg[2\bar{X}_n^{\frac 12} -\dfrac 1{\sqrt n} z_{1-\frac{\alpha}{2}},2\bar{X}_n^{\frac 12} +\dfrac 1{\sqrt n} z_{1-\frac{\alpha}{2}}\bigg] \]
Código
set.seed(42)
X <- rpois(n = 1000, lambda = 5)
x_bar <- mean(X)
z <- qnorm(p = 0.975)
# IC para g(theta) = 2*sqrt(theta), varianza estabilizada ~ N(2*sqrt(theta), 1/n)
c(
2 * sqrt(x_bar) - 1 / sqrt(1000) * z,
2 * sqrt(x_bar) + 1 / sqrt(1000) * z
)[1] 4.371529 4.495488Código
import numpy as np
from scipy.stats import norm
rng4 = np.random.default_rng(42)
X = rng4.poisson(lam=5, size=1000)
x_bar = X.mean()
n = len(X)
z = norm.ppf(0.975)
# IC para g(theta) = 2*sqrt(theta), varianza estabilizada ~ N(2*sqrt(theta), 1/n)
ic_raiz = (2*np.sqrt(x_bar) - z/np.sqrt(n),
2*np.sqrt(x_bar) + z/np.sqrt(n))
print(f"IC para 2*sqrt(theta): [{ic_raiz[0]:.4f}, {ic_raiz[1]:.4f}]")IC para 2*sqrt(theta): [4.3846, 4.5086]Para estimar el IC para \(\theta\), vea que si \(y=2x^{\frac12} \implies x = \dfrac{y^2}{4}\). Aplicando esta transformación al intervalo anterior, se obtiene
\[ \bigg[\dfrac 14 \left(2\bar{X}_n^{\frac 12} -\dfrac 1{\sqrt n} z_{1-\frac{\alpha}{2}}\right)^2,\dfrac 14 \left(2\bar{X}_n^{\frac 12} +\dfrac 1{\sqrt n} z_{1-\frac{\alpha}{2}}\right)^2\bigg]. \]
Código
# Aplicar g^{-1}(y) = y^2/4 a los extremos del IC de 2*sqrt(theta)
c(
(1 / 4) * (2 * sqrt(x_bar) - 1 / sqrt(1000) * z)^2,
(1 / 4) * (2 * sqrt(x_bar) + 1 / sqrt(1000) * z)^2
)[1] 4.777567 5.052354Código
import numpy as np
from scipy.stats import norm
# Recomputar ic_raiz para que el bloque sea autónomo (no depende del estado de sesión)
rng4b = np.random.default_rng(42)
X_b = rng4b.poisson(lam=5, size=1000)
x_bar_b = X_b.mean()
z_b = norm.ppf(0.975)
ic_raiz_b = (2*np.sqrt(x_bar_b) - z_b/np.sqrt(1000),
2*np.sqrt(x_bar_b) + z_b/np.sqrt(1000))
# Aplicar g^{-1}(y) = y^2/4 a los extremos del IC de 2*sqrt(theta)
ic_theta = ((ic_raiz_b[0]**2) / 4, (ic_raiz_b[1]**2) / 4)
print(f"IC para theta: [{ic_theta[0]:.4f}, {ic_theta[1]:.4f}]")IC para theta: [4.8062, 5.0818]9.6 Resumen
| Parámetro | Pivotal \(V(X,\theta)\) | Distribución | Intervalo al \(100(1-\alpha)\%\) |
|---|---|---|---|
| \(\mu\) (normal, \(\sigma^2\) desconocida) | \(\dfrac{\sqrt{n}(\bar{X}_n-\mu)}{s}\) | \(t_{n-1}\) | \(\bar{X}_n \pm t_{n-1,\,1-\alpha/2}\dfrac{s}{\sqrt{n}}\) |
| \(\sigma^2\) (normal) | \(\dfrac{n\hat{\sigma}^2}{\sigma^2}\) | \(\chi^2_{n-1}\) | \(\left[\dfrac{n\hat{\sigma}^2}{\chi^2_{n-1,\,1-\alpha/2}},\;\dfrac{n\hat{\sigma}^2}{\chi^2_{n-1,\,\alpha/2}}\right]\) |
| \(\theta\) (exponencial, \(n=3\)) | \(\theta T\) | \(\Gamma(3,1)\) | \(\left(0,\;G^{-1}(1-\alpha)/T\right)\) |
| \(\theta\) (Poisson, asintótico) | \(2\sqrt{\bar{X}_n}\) | \(N\!\left(2\sqrt{\theta},1/n\right)\) | Transformar IC de \(2\sqrt{\theta}\) con \(g^{-1}(y)=y^2/4\) |
Receta general para construir un IC mediante cantidad pivotal:
- Encontrar \(V(X,\theta)\) con distribución \(F_V\) que no dependa de \(\theta\).
- Elegir \(\gamma_1 < \gamma_2\) con \(\gamma_2 - \gamma_1 = 1-\alpha\) y escribir \(\mathbb{P}[v_{\gamma_1} \leq V \leq v_{\gamma_2}] = 1-\alpha\).
- Despejar \(\theta = r(V, X)\) y aplicar \(r\) a los cuantiles: \(A = r(v_{\gamma_2}, X)\), \(B = r(v_{\gamma_1}, X)\).
- Si \(r\) es decreciente en \(v\), los límites quedan invertidos respecto al paso anterior; el valor más pequeño siempre va a la izquierda.
- Cuando no existe pivotal exacto, aplicar el Método Delta para estabilizar la varianza y usar la aproximación normal.